谷歌大脑发布概念激活向量,了解神经网络的新思维方式
大数据文摘出品
编译:李可、张秋玥、刘俊寰
可解释性仍然是现代深度学习应用的最大挑战之一。计算模型和深度学习研究的最新进展使我们能够创建极度复杂的模型,包括数千隐藏层和数千万神经元。效果惊人的前沿深度神经网络模型构建相对简单,但了解这些模型如何创造和使用知识仍然是一个挑战。
最近,Google Brain团队的研究人员发表了一篇论文,提出了一种名为概念激活向量(Concept Activation Vectors, CAV)的新方法,它为深度学习模型的可解释性提供了一个新的视角。
可解释性 vs 准确性
可解释性 vs 准确性
要理解CAV技术,需要了解深度学习模型中可解释性难题的本质。在当今一代深度学习技术中,模型的准确性与可解释性之间存在着永恒的矛盾。可解释性-准确性矛盾存在于完成复杂知识任务的能力和理解这些任务是如何完成能力之间。知识与控制,绩效表现与可核查性,效率与简便性...任意一项抉择其实都是准确性和可解释性之间的权衡。
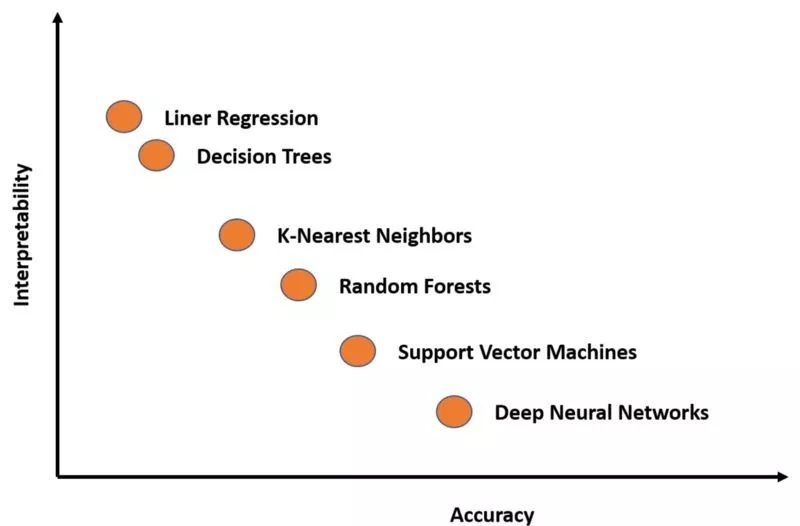
你是关心获得最佳结果,还是关心结果是如何产生的?这是数据科学家在每个深度学习场景中都需要回答的问题。许多深度学习技术本质上非常复杂,尽管它们在许多场景中都很准确,解释起来却非常困难。如果我们在一个准确性-可解释性图表中绘制一些最著名的深度学习模型,我们将得到以下结果:
深度学习模型中的可解释性不是一个单一的概念。我们可以从多个层次理解它:
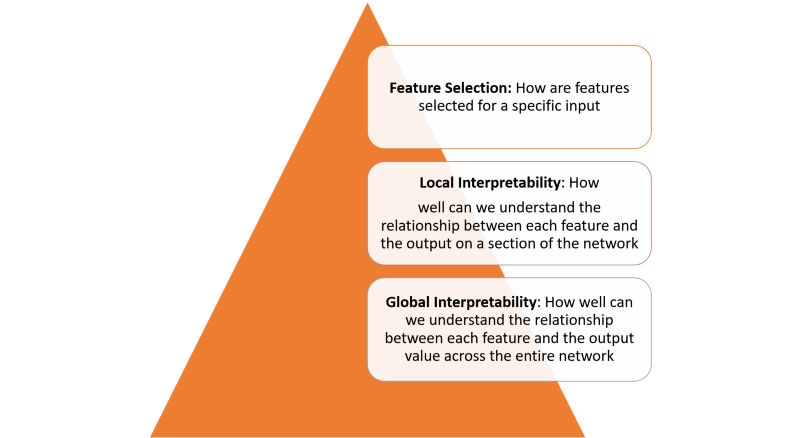
要得到上图每层定义的可解释性,需要几个基本的构建模块。在最近的一篇论文中,谷歌的研究人员概述了他们看来的一些可解释性的基本构建模块。
Google总结了如下几项可解释性原则:
了解隐藏层的作用:深层学习模型中的大部分知识都是在隐藏层中形成的。在宏观层面理解不同隐藏层的功能对于解释深度学习模型至关重要。
了解节点的激活方式:可解释性的关键不在于理解网络中各个神经元的功能,而在于理解同一空间位置被一起激发的互连神经元群。通过互连神经元群对神经网络进行分割能让我们从一个更简单的抽象层面来理解其功能。
理解概念的形成过程:理解深度神经网络如何形成组成最终输出的单个概念,这是可解释性的另一个关键构建模块。
这些原则是Google新CAV技术背后的理论基础。
概念激活向量
概念激活向量
遵循前文讨论的想法,通常所认为的可解释性就是通过深度学习模型的输入特征来描述其预测。逻辑回归分类器就是一个典型的例子,其系数权重通常被解释为每个特征的重要性。然而,大多数深度学习模型对诸如像素值之类的特征进行操作,这些特征与人类容易理解的高级概念并不对应。此外,模型的内部值(例如,神经元激活)也很晦涩难懂。虽然诸如显著图之类的技术可以有效测量特定像素区域的重要性,但是它们无法与更高层级的概念相关联。
CAV背后的核心思想是衡量一个概念在模型输出中的相关性。概念的CAV就是一组该概念的实例在不同方向的值(例如,激活)构成的向量。在论文中,Google研究团队概述了一种名为Testing with CAV(TCAV)的线性可解释方法,该方法使用偏导数来量化预测CAV表示的潜在高级概念的敏感度。他们构想TCAV定义有四个目标:
易懂:使用者几乎不需要机器学习专业知识。
个性化:适应任何概念(例如,性别),并且不限于训练中涉及的概念。
插入即用:无需重新训练或修改机器学习模型即可运作。
全局量化:可以使用单一定量测度来解释所有类或所有实例,而非仅仅解释单个数据输入。
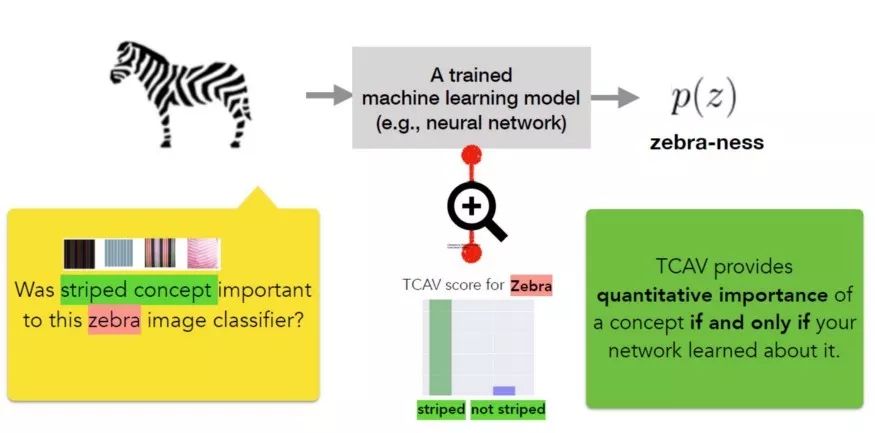
为实现上述目标,TCAV方法分为三个基本步骤:
1)为模型定义相关概念。
2)理解预测对这些概念的敏感度。
3)推断每个概念对每个模型预测类的相对重要性的全局定量解释。
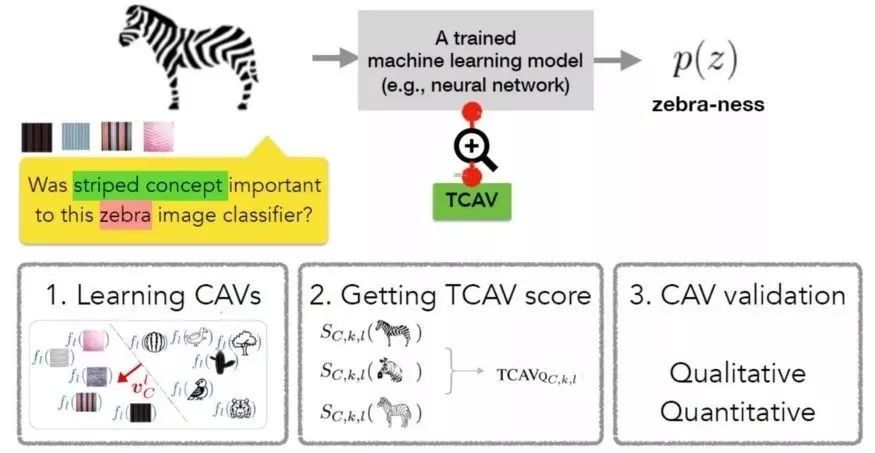
TCAV方法的第一步是定义相关的概念(CAV)。为实现此目的,TCAV选择一组代表该概念的实例或寻找标记为该概念的独立数据集。我们可以通过训练线性分类器区分概念实例产生的激活和各层中的实例来学习CAV。
第二步是生成一个TCAV分数,用于量化预测对特定概念的敏感度。TCAV使用了用于衡量ML预测值在某一概念方向、在激活层对输入敏感度的偏导数。
最后一步尝试评估学到的CAV的全局相关性,避免依赖不相关的CAV。毕竟TCAV技术的一个缺陷就是可能学到无意义的CAV,因为使用随机选择的一组图像仍然能得到CAV,在这种随机概念上的测试不太可能有意义。为了应对这一难题,TCAV引入了统计显著性检验,该检验以随机的训练次数(通常为500次)评估CAV。其基本思想是,有意义的概念应该在多次训练中得到一致的TCAV分数。
TCAV的运作
TCAV的运作
团队进行了多次实验来评估TCAV相比于其他可解释性方法的效率。在一项最引人注目的测试中,团队使用了一个显著图,尝试预测出租车这一概念与标题或图像的相关性。显著图的输出如下所示:
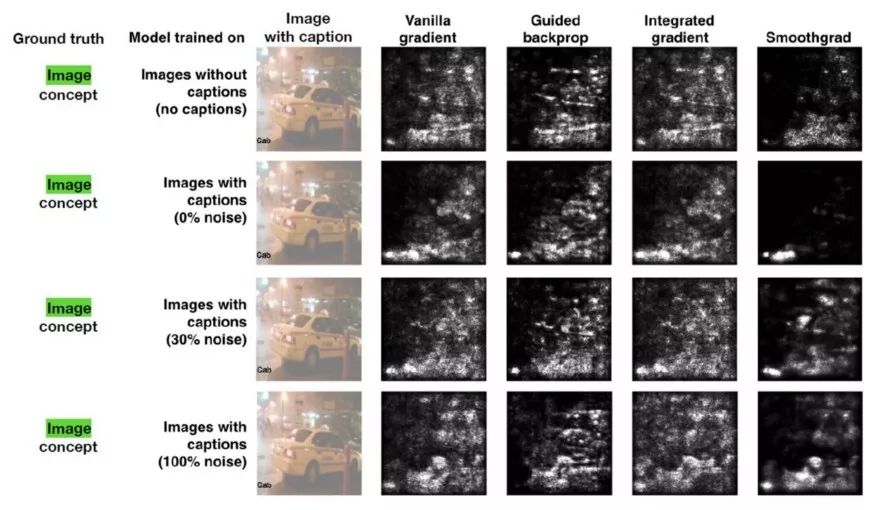
使用这些图像作为测试数据集,Google Brain团队在Amazon Mechanical Turk上邀请50人进行了实验。每个实验人员执行一系列共六个针对单个模型的随机顺序任务(3类对象 x 2种显著图)。
在每项任务中,实验人员首先会看到四幅图片和相应的显著性蒙版。然后,他们要评估图像对模型的重要程度(10分制),标题对模型的重要程度(10分制),以及他们对答案的自信程度(5分制)。实验人员总共评定了60个不同的图像(120个不同的显著图)。
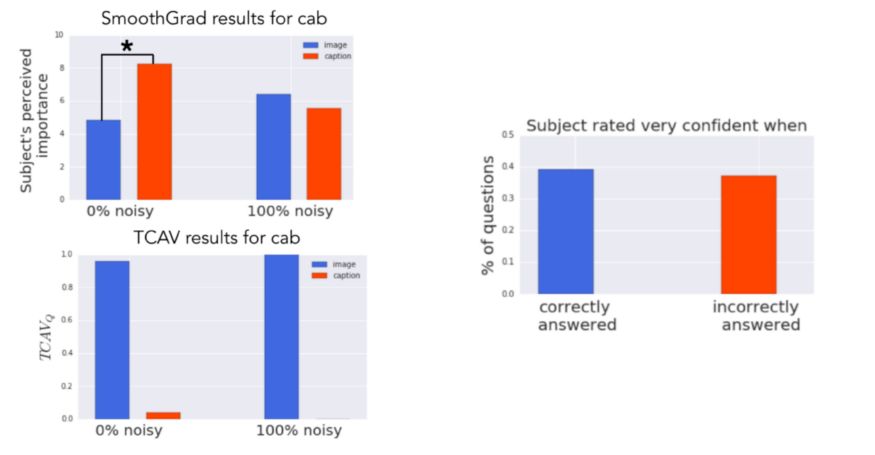
实验的基本事实是图像概念比标题概念更相关。然而,看显著图时,人们认为标题概念更重要(0%噪声的模型),或者辨别不出差异(具有100%噪声的模型)。相比之下,TCAV结果正确地表明图像概念更重要。
TCAV是这几年最具创新性的神经网络解释方法之一。初始的代码可以在GitHub上看到。许多主流深度学习框架可能会在不久的将来采用这些想法。
相关报道:
https://towardsdatascience.com/this-new-google-technique-help-us-understand-how-neural-networks-are-thinking-229f783300

3个月,深度学习从理论到实战(英语)
全球最火机器学习社区School of AI清华专场
每周一次社区实战

实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn
志愿者介绍
后台回复“志愿者”加入我们








