口音歧视?语音AI技术的尴尬,却暗藏社会经济地位偏见 | 深度

智能语音助理已经成为现下最火的人机交互技术,用说的就可以下指令、查找东西、或是陪聊,但想让它得听懂你说什么,前提是你说话没有带口音。
先说一个真实故事吧,有一回 DT 君在美国友人家想要观看由知名导演 David Lynch 执导,睽违 26 年才回归的烧脑影集—《双峰》(Twin Peaks),对着当地有线电视 Comcast 的语音搜索助手说“Twin Peaks”,但不管说了几次,电视画面永远只显示青春校园片,猜想它应该是把“Twin”,听成了“Teen”。那时 DT 君有一个感觉:我的英文这么差吗?听不懂你口音的语音识别系统令人沮丧。
口音,是一种某个群体、地区或国家所特有的发音方式,而带口音的语音与标准语音间的差异主要体现在发音方面而非词汇等层面。对于非英文母语的人来说,说英文时往往会受到母语发音的强烈影响,例如中文腔、欧洲腔、印度腔,同样的,我们听外国人讲中文,经常觉得他们带有浓浓的口音。
口音,对人类来说,不是大问题,有时还会觉得充满了异国情调的魅力,但对机器来说,却是高级挑战。
当人类听不明白带口音者所要表述的内容时,可以请对方再说一次或说慢点,但目前智能音箱、手机上的语音助手不具备这种能力,当它们听错带有口音的人所说的话,用户可能觉得体验很差,决定放弃使用,目前来看,这件事不是一个大问题,但如果看得更深一点,特别是训练数据集的来源很可能暗藏着一种歧视危机时,它会是一个更严肃的议题。
自动语音识别的挑战

一直以来,说话的口音是自动语音识别(ASR)系统希望进一步突破的领域,不论是对神经网络引擎或统计模型都是如此。
华盛顿邮报不久前发表的一篇深度报导引起了颇大的回响,他们与 Globalme、Pulse Labs 两家语言研究公司合作研究智能音箱的口音问题,研究范围来自美国近 20 个城市、超过 100 位受试者所发出的数千条语音命令,发现这些系统对不同地区人们的语言理解有着差异,例如 Google Home 听懂西岸口音胜于南方口音,但差异更明显的是,非英文母语(non-native)的人所说的英文,例如以西班牙文、中文作为第一语言的人,在此测试中,这两大族群所说的英文,不论是 Google Home 或 Amazon Echo 的辨识准确率都是排最后,很可惜的是,拉丁裔及华裔是美国两大移民族群。
反观印度族群所说的英文,Google Home 或 Amazon Echo 对其辨识率均高于西文腔和中文腔英文。就有网友开玩笑说,不知道这与开发者的背景有没有关系,因为这两家公司都有许多工程师来自印度,当他们在开发产品时,每天跟智能语音助理对话,因此机器比较听得懂他们的英文。
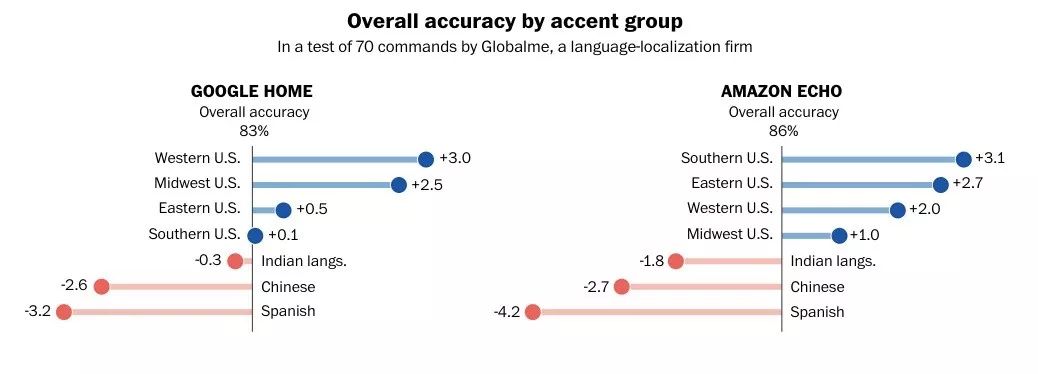
图|华盛顿邮报测试智能音箱的口音问题(资料来源:华盛顿邮报)
面对此研究发现,上述两家科技巨头官方回应是:口音仍然是他们面临的主要挑战之一,他们正投入资源以训练、测试新的语言和口音,包括利用游戏的方式来吸引用户,以取得不同的声音数据。
“这些系统最适合白人,受过高等教育的中产阶级美国人,可能来自西岸,因为那是打一开始就可以使用该技术的群体,”Kaggle 数据科学家 Rachael Tatman 接受华尔街日报采访时不客气地说。
智能语音助理只服务高富帅、白富美?
等等,难道这是要说智能语音助理有歧视?在进入这个智能语音助理难道是歧视带有口音的人这个严肃话题之前,先简单谈下 ASR 的训练方式。
要训练机器识别语音,需要大量的语音样本。首先,研究人员会收集谈论各种话题的声音,然后手动转录、剪辑这些音档。这种数据组合—音档和手写抄录,也就是所谓的语音语料库(speech corpora),让机器在声音和文字之间产生关联,变成学习人类如何说话的算法,进而可以辨识语音,当遇到先前没有听过的单词或口音时,最好它还会猜对。
例如,宾夕法尼亚大学发起的语言数据联盟(LDC),在全球众多大学的加入下,累积了不少的语料库,可对外授权给公司和研究人员使用,其中最著名的语料库之一是 Switchboard。
Switchboard 起初是由 DARPA 赞助、知名半导体公司德州仪器(TI)在 1990 年左右进行数据搜集的电话语音语料库,当时为了吸引大众参与,研究人员还祭出长途电话卡作为小礼物,民众拨电话到研究专线,跟研究人员谈论某些话题,像是儿童保育或体育。此项目搜集了 543 位发言者(caller)、70 个话题,总计大约 260 个小时的电话录音。而 Switchboard 自 1992 年由 LDC 发布后第一版后,持续进行修正及更新,微软及 IBM 近一两年的语音识别研究,就使用 Switchboard 来测试语音系统的错字率(WER,Word Error Rate)。
中文部分也有不少语料库,例如,北京大学 CCL 汉语语料库、北京语言大学 BBC 汉语语料库、民间企业则有海天瑞声科技投入,另外,在国家 863 高技术项目支持下完成的 RASC863 普通话语音语料库,可以说是目前规模及应用较大的中文带口音的语音数据库。
口音数据搜集的难题
ASR 系统在识别口音不够好的主要原因在于缺乏带口音的数据集。收集数据本身就是一项成本昂贵、流程繁琐的工作,训练系统识别新口音时,通常是音韵学家(phonologists)根据说话者的口音,手动提取语音的特征,写成通用的规则。
相反的,标准语音的采集和标注难度较小,比较容易获得训练模型所需要的大量数据,所以大多数开发出来的 ASR 系统都是基于标准语音训练而生,以美国为例,就是所谓的通用美国英语(GAE,General American English),像是广播、新闻节目中的字正腔圆英文。
由于 GAE 不具备明显地区或种族特征的英语口音特征,而且机器缺乏不同口音的音频样本,自然就不知道之间的差异。当说话者带有某种重口音,对着智能音箱说话、下指令,此时机器收到一个输入(input),input 中含有的口音变异会导致测试数据的声学特性与标准语音训练的 ASR 失配(mismatch),就可能出现识别错误的现象。

尽管有公司会宣称自家的系统可以辨识带口音的说话,但事实上得看辨识到什么“程度”,能听懂“几种”特定口音?能听懂输入的一部分,还是全部?目前看来,就算是先进的 ASR 系统如 Google 、亚马逊,依旧不够完美,在面对西语腔英文或中文腔英文时的错误率较高。
机器无错,但数据多元化可以让它变更好
正因为搜集带口音数据的成本高,对企业来说,自然会选择先从体量较大的群体下手,相较于说着标准语音的族群,带口音的群体是少数,因此企业多会认为服务大多数人或目标客群,才能取得较高的投资效益,等到有余力再去优化产品,所以就算开发的系统无法很准确识别带口音的语音也不是什么大错。也就是说,当一切基于商业考量,只想着哪些群体比较愿意或是有钱购买自家的产品,口音就容易被忽略。
至于规模较大的公司例如苹果、谷歌和亚马逊,他们的产品有很大部分是销售到美国以外的地区,他们意识到迎合口音是件重要的事,内部均有自己的方法来收集这些语言和口音数据,但就算如此,很大程度上是只针对每个国家进行训练,例如同样是“英文”,会预先针对美国、英国、澳大利亚的口音做训练。同时,消费者越常使用他们的产品,提供的反馈越多,越能帮助产品的改善,“随着越来越多的人与 Alexa 交谈,并且有各种口音,Alexa 的理解能力将得到改善,”亚马逊表示。
另一方面,他们期望借开发者伙伴之力一起来解决问题,例如 Alexa 应用程序上的 Voice Training 程序,另外 IBM Waston 也提供 API,让开发者上传音档来自定义、训练模型,以识别有口音的语音。但尽管如此,他们仍认为口音依旧是个挑战。
如今更多语音数据的积累,无疑有助于提升 ASR 对口音识别的精确度,不过,部分行业人士及科学家并不是故意要煽动社会与人工智能的对立,他们更想呼吁外界重视一个问题:语音数据集代表性的不足,反映出隐藏在背后的社会经济地位偏见。在这个领域还是会隐约感觉到有某种偏好:喜欢使用没有口音及腔调自然的声音。
例如,“一个典型的美国声音数据库将缺乏贫穷、未受过教育、农村、非白人、非以英文为母语的声音。而缺少的群体往往是一般被边缘化的群体,”Rachael Tatman 先前接受《连线》采访时直言。
除此之外,视频网站 YouTube 使用谷歌的语音识别系统,自动为影片创建字幕,结果发现系统遇到女性、带有南方或苏格兰口音的人时,生成字幕的水准就会明显下降。尽管大家都知道这不是机器的错,但这种尴尬的情况往往让人感到不适。
技术本来就是中性,不会歧视人,智能语音助理也没有只偏爱服务高富帅、白富美,一切都在于训练过程。这阵子人工智能领域谈论很多关于数据偏见、数据偏差的问题,是因为当初在开发系统的过程中人类没有意识到数据公平性及多元性的问题,导致训练出来的模型不够精确,一但把不精确或可能不精确的系统用在判断或决策,就可能伤害某些群体。
目前大多数的人工智能只能识别那些它曾经听过的内容,想要它变得更灵活,就得喂给它更多元的数据,例如不同口音的样本。同样的,缺乏多样化的语音数据,最终仍会无意间导致歧视的发生,特别是当语音被视为是未来交互的主流,走入车载、智能家居等情境,但如果它听不得懂某些群体讲的话,就代表这些人将被这些技术及服务排除在外,这就完全背离了人工智能普及化、人工智能应为所有人使用的初衷,这将是大众不愿见到,也是科学家认为所有人必须警觉的观点。
Mozilla 号召全球“献声”,齐力打破垄断
尽管有人认为,把语音助理不懂辨识带有口音的指令上升为歧视问题,根本就是小题大做。不过,换一个角度想,现今企业往往强调用户至上,当公司推出某样产品本该就以“用户体验”为主要考量,当讲话有口音的人买了一个智能音箱回家,却感到挫折或失望,自然就会完全远离这个产品,甚至是这家公司。因此就算站在商业利益的角度,解决带口音的语音识别,是开发智能助手、智能音箱的公司必须着手解决的问题。
尽管不少企业意识到口音识别的问题,但碍于商业考量,多半不愿意将资源公开,值得庆幸的是,开源世界已经先行,以开源而生、打造浏览器 Firefox 和诸多开源工具的 Mozilla,在去年 7 月宣布了一项最大开源语音募集专案—同声计划(Common Voice),希望建立一个开放且公开的语音数据集,每个人都可以使用它来训练语音应用程序,以打破目前 ASR 技术被 Google、亚马逊等巨头垄断的现况,同时 Common Voice 另一大目标就是收集尽可能多的不同口音,以便计算机能够更好地理解每个人。
图|Mozilla 号招全球贡献自己的语言及口音
Mozilla 指出,要训练一个声音转文字(STT,Speech To Text)模型大约需要 1 万小时的声音数据,为了加快收集声音数据的进度,希望利用开源社区的美德,也就是群众力量,鼓励大家“献声”,捐赠声音,并制作了一个专属网页,点开“捐赠声音”的按钮后,网友就念出网页上显示的句子,只要协助录音的人越多,就能记录越多句子,这套系统也就能越准确,希望全球开源者能够贡献自己的语言以及当地口音,目前在上头已经搜集了非常多种语言,除了德语、法语、英文这种常见的语言外,还有加泰隆语、卡拜尔语、鞑靼语等超过 40 种语言。
Mozilla 首席创新官 Katharina Borchert 先前在博客上表示:“语音接口是互联网的下一个前沿...... 我们认为这些接口不应该被少数公司控制,我们希望用户可以是在基于自己的语言和口音的情境下被识别和理解。”
图|Mozilla 首席创新官 Katharina Borchert 在博客发文
今年早些时候,DT 君和一位初创公司的创始人聊到了前述 Comcast 听不懂我说的英文的趣事,还记得他开玩笑的说,因为听不懂带口音的英文,Google 和亚马逊未来很可能会被用户控告歧视,美国律师也可以开始用这打广告了。由于美国拥有众多的移民族群,对于可能涉及或暗指种族歧视的言论、行为都得相当留心,当时的一番玩笑话,现在听起来,可以是给 Google、亚马逊、苹果及微软的忠告。
-End-







