数学 + 统计 + 脑科学 = 破解 AI “黑盒子” 的密匙?

AI 科技评论按:2019 年 5 月 9 日,由北京智源人工智能研究院主办的“智源论坛”在中关村国家自主创新示范区会议中心举行。“智源论坛”是一系列高水平人工智能技术分享活动,将定期邀请业内顶尖学者共同探讨前沿技术、分享经验。围绕当前人工智能所面临的可计算性、可解释性、泛化性和稳定性等基础问题,主办方从数学、统计和计算的角度,设立了人工智能的数理基础重大研究方向,本期论坛主题为“人工智能的数理基础”,由 15 名学者分为三天进行分享。AI 科技评论有幸受邀出席,将现场精华记录如下。

第一期论坛一共安排了 5 场分享,第一位主讲人是北京大学董彬副教授,其报告题目是《Bridging Deep Neural Networks and Differential Equations for Image Analysis and Beyond》。

目前学界已关注到深度学习存在的问题,比如 Ali Rahimi 就在 2017 年 NIPS 大会上提到 Deep learning 是 “alchemy”(炼金术)。与此同时, Ali Rahimi 也表示 Being alchemy is certainly not a shame,而 not wanting to work on advancing to chemistry is a shame,意思是说只有提供系统的理论指导,该领域才会从纯实验学科变成有理论体系的学科。我和团队试图从应用/计算数学的角度去理解深度学习,以期能为网络构架设计、相关研究提供一些新的指导思想。
一般来说,数学家都会通过严谨的理论分析去证明猜想,而我们采取了另一条思路,先寻找深度学习与数学概念的对应关系,再据此进行分析。比如我们可以把深层网络理解为微分方程,亦或者是微分方程的一种离散形式。建立起这个联系后,我们就会清楚该从数学的哪个领域入手去理解深度学习。
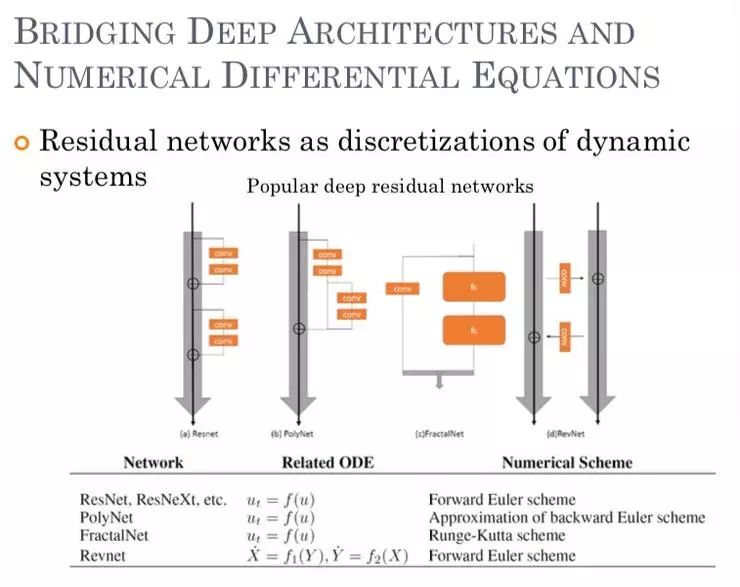
DNN 与数值 ODE 之间是一个什么样的关系呢?如果以数学的形式写出来,就会认为这是一个动力系统,然而这个很难被分析。有名的残差网络从数学形式上来看就比较好理解,其实就是连续的 ODE,对时间做了前项欧拉的离散,只不过在设计网络时把 Δt 设成了 1。
这是很有意思的观察,但人们也在怀疑,残差网络核与动力系统的联系是否只是特例?更重要的是,假如 numerical ODE 和网络构架之间建立了联系,我们是否能从 numerical ODE 这个相对成熟的研究领域去反推出有用的构架?
后来我们发现,除了残差网络,其他网络如 pulling Net 对应的实际上也是一个解了的反向欧拉,而反向欧拉需要我们对非常大的非线性方程组的逆进行求解,做不了就得利用多项式的逼近。于是我们用 numerical ODE 尝试设计一些新的网络构架,主要针对 residue block,至于具体里面的 block 是什么,并不做太大修改。
除了确定性内容,深度学习的训练还会面临各种各样的随机扰动,按理来说其对应的就是随机微分方程。我们发现,不管是随机策略还是网络自带的随机性质,训练网络实际上是一个求解随机控制的问题,因此可以从随机控制的角度来看待带有随机训练策略的深度学习训练。我们做了简单对比,发现在不减少精度情况下,可以把深度减少90%,100层就能达到1200层的效果。
此外,随着采集数据的手段越来越先进,如今存在大量的三维甚至四维数据,我们是否能将 PDE 与深度学习结合,形成提取规律的高效工具?我们对此也做了初步尝试,核心思想是对卷积做部分约束,确保学习方程之余,还能保证模型的可预测性。
过去用演化预热方程做图像去噪,一旦演化的时间过长,图像的细节也会随之丢失,也就是说,停止的时机是个超参数,且与噪声的水平有关。不同的图像,不同的噪声水平,超参数的最佳停止时间是不一样的,我们除了对网络的参数进行优化,也将动力系统的停止时间纳入到优化范畴内,即是网络深度可以根据当前数据进行自动调节,最终结果的自动化程度要比以前好很多。
下一步,我们将借助智源的支持去做更多理论分析,比如将数值微分方程或者是反问题里的其他方法视作深度学习网络构架,接着分析这些网络构架的泛化水平、压缩感知等,最终设计出更加紧致的网络。

第二位主讲人是来自北京大学的林伟研究员,他的报告题目是《破解机器学习中的中的维数灾难:从可辨识性谈起》。

所谓高维统计,即是研究所谓的高维数据或者高维模型的统计学。以数据为例,维数指的是变量的个数,比如同时分析几千个甚至是更多数据,那么维数就会非常高。放在模型维数语境来说,,高维就是俗称的“过参数化”。
怎么从统计学的角度给人工智能技术建立一个能提高可解释性的理论学习框架呢?我认为目前存在两套工具,一套基于随机矩阵理论,我们可以从这种渐进框架下推导出许多与经典统计学中 N 趋于无穷不同的渐进结果;另一套是我所做的集中不等式,简单来说,许多结果都是非渐进的,我们可以据此得出推论,令 P 随着 N 具有某种关系,借此得到一些允许 P 远大于 n 的渐进结果。
什么是可辨识性?如果数据分布的两个参数 θ1 和 θ2 对应的数据分布是一样的,我们就可以借此推导出是同一个参数。这个很关键,如果没法确定真实参数是什么,一旦用算法做优化找参数,结果将极其不稳定。不可辨识的模型有哪些缺点?一个是解释性差;一个是泛化能力弱。我们可以通过稀疏和低秩来保证可辨识性。需要强调的是,因果推断理论在很多情况下是不可辨识的,但我们可以为之做出定界,如果上界与下界足够小,那么还是有作用的。
如果可辨识性无法保证,我们是不是非要达到可辨识性的目标?不可辨识性所导致的误差,能否反映在我们的结果里?我们的工作给出了答案:前者是no,后者是yes。如果是做生物学习,那么问题一的答案是最好有,但不是非要不可,因为确实存在过稀疏的网路性能更好的例子,但不绝对;至于第二个问题目前还没有定论。
神经网络是一种高维或者过参数化的模型,从统计学来说,我们可以如何进行修改?第一、拟合目标函数;二、分析目标的真实函数到底是在什么类别。有了这个东西以后,我们将能得到一些解,比如说两种稀疏。


第三位主讲人是来自北京大学的邵嗣烘副教授,他的报告题目是《面向智能的数学》。

我们现在造很多机器,总想弄清楚人类从哪里来,要到哪儿去,以解答所谓的终极问题。那么问题就来了,我们是怎么意识到我们是我们的呢?这就涉及到人脑是怎么形成意识的问题。
所谓的人工智能,其根本是通过人类能理解的方式去模仿智能或者说探索智能的机理。人的大脑是一个由 1000 亿的经元构成的脑神经网络,无论好的坏的想法都来自这里,这隐含着两个基本事实:一、构成网络的物质基础与自然界中的原子没有区别,所以我们得用量子力学描述它;二、要基于量子力学的行为去描述神经元突触量子力学的行为,这对于理解意识的产生非常重要。
这么重要的课题,为何一直都没太大的进展呢?其一,直到去年我们才成功掌握果蝇的全脑产高清图像,也是从这个时候开始我们才可以看到所有神经元的空间位置,不过这个活体已经失去生命力了。其二,对量子力学行为进行测量,从物理原理的层面上来说其实特别困难。具体难在什么地方呢?海森堡测不准关系告诉我们,微观世界的粒子除了是粒子以外,还向着光。
为此,我们利用计算机算解通过经典的量子力学方程给解出来,使用了维格纳函数。维格纳函数是目前唯一拥有严格数学理论知识、可以从量子世界过渡到经典世界的数学表述形式,利用维格纳函数做模拟,可以为实验科学家提供观测和对比的数据结果。一旦要在实际的脑神经网络中去跑动力学,肯定会遇到计算规模的问题,因此我们采取了随机算法模式,通过数学的等价推理,发现它等价于一个更新方程,而方程本身内在存在一个随机解释,即是所谓的分枝随机游走,基于这个过程将可以进行进一步模拟。
我们来看一下果蝇的大脑数据实验,它的脑神经元是由十万个神经突触构成的脑神经网,而人脑则是一千亿。从数据模拟的角度来说,规模差距太大,无论对算法设计还是数学理论而言都是极大的挑战。因此,我们必须研究优化算法,如何在不损害精度的情况下,在误差允许范围之内对网络做分解。
我们在这方面做了很长时间的探索,试图去探讨图上的数学,结果发现很多问题不是我们所想象的那样。比如图上讨论某一类问题,你将发现其特征函数或者特征向量非常多,而且可以把它进行局域化。换句话说,给你一个网络,再给你一把剪刀进行裁剪,我们既可以剪最多的边,也可以剪最小的边,但我们最终希望,剪下来的两块是比较匀称的。现实的数学理论会告诉你,不可能在有生之年找到最佳方案。
既然如此,我们如何以最快的代价拿到次优解?我们的思路是把大图剪成小图,再用小图拿来跑维格纳量子物理学,从中了解时间之间是否存在量子关联,再把数据开放做实验。我们想办法找到连续优化问题与之进行对应,回到数学分析层面其实很简单,一个序列的极限是唯一的,但是具体产生同样极限的序列有多少种,以及具体是哪个序列,则取决于额外约束。
我们希望能把这套理论走通,以便产生的优化问题能有解析表达形式。于是,我们做了所谓的Lovasz扩展,随便给个组合优化问题,我们都能找到对应的联系。我们据此设计了一个简单的算法叫表达式迭代,这些问题虽然不能知道最优值,那我们就把文献里看到的最佳值做一个解,由此找到这些算法的相对误差,然后再简单的跑一下,这样最终结果与最佳值的误差能够控制在1%以内,比原来的快了不只一点点。
这个方向我们已经做了很好的积累,其中包括组合问题,如何解两个关联等。这个方向如果要继续往前走,需要跨好几个领域,具体究竟需要用到哪些数学工具或者数学理论,目前还不是很清楚,目前只能做各种尝试。
总而言之,这些事情一下把我们拉回了起点,我们可能真的需要从根子上或者从数学理论上去理解,把连续的东西或者离散的东西放在统一的框架里进行讨论。过去,我们做的很多事情都太局限了,而现在你再也躲不开,从这个角度而言,这件事情才刚刚开始。
第四位主讲人是来自北京应用物理与计算数学研究所的王涵,他的报告题目是《Deep Learning for Multiscale Molecular Modeling》。

假设这个世界由原子构成,每个原子我们都看成是一个质点,这个位置是 Ra 。根据中学学过的牛顿第二运动定律,只要给定初值就能把这个方程解出来,这样我们就能知道所有原子在任意时刻的坐标,这是分子模拟在干的一个事情。如果大家看过三体,就会马上意识到要精确地解方程,只能对两原子体系求解,然而任意一个多原子体系,你都无法在无穷长的时间内把它给精确的解出来,由此初始的初值误差就会变得非常大,造成你的解变得不靠谱。
然而分子模拟想获得的结果并不是原子运动的轨道,而是原子运动的轨道在无穷长时间内对相空间的一个分布,这样就意味着数值误差对于这个分布的影响实际上是可以被控制的。换句话说,如果离散做得足够好,我们获得的平台分布就能与物理中想要的分布保持一致。分子建模试图把能量函数的 E 给写出来,而多尺度分子建模就是对原子坐标做一定的粗粒化,然后再去写出等价的形式。
多维函数在传统数学的处理上还是比较困难的,深度学习正好给我们提供了非常有利的工具。我们的目标就是在保证第一性原理计算精度的前提下,能做到计算开销,并与经典力场尽可能进行合并。
然后对称性开始成了问题。举个例子,比如手机是一堆原子,然后这个手机在空间中平移一下,所有原子的坐标一起加一个向量,还能保证这个手机的能量显示不变,即使是把手机转一下,能量也同样不变。 对称性对于一个生物学模型或者神经网络来讲无法被保证,任意的坐标平移或交换都可能导致网络的输出不一样。
保持模型的对称性有两种做法:第一种是在分子体系里固定一个随体的标件,这样就能通过排序把交换的对称性给稳住,这个做法的优点是表示能力强,缺点是会给能量函数造成一定的不连续性。另一种则基于两个观察,第一个观察是以两个向量做内基,做完内基以后是旋转不变的,第二个观察是对 i 原子的坐标的近邻求和,求完和以后交换就不变。基于这两点,我们设计了所谓的描述子,然后我们把描述子放到神经网络前面,再把输出接到神经网络里面,以保持整个模型的对称性。
我们的深度学习模型发表后,别人拿去解决了一些实际问题。比如一位英国皇家科学院院士用来研究硅,他说早先产生的力场很难把硅的固相跟硬相同时描述好,但我们深度学习的模型可以,他用来做了一个硅的熔化,取得了很好的效果。另一个是北师大的教授,他拿来做激发态的反应动力学。在过去传统的建模里,激发态的动力学的两个势能面交接锥的精度总是做不好,是该领域的一个难题,我们的深度学习模型却很好解决了这个问题。
前面讲的都是深度学习对原子间相互作用的表示,实际上却存在一个很严重的问题——数据从哪儿来。我们因此提出主动学习策略,先训练出一个可进行分子动力学的模型,然后再通过分子动力学去构型更多分子,简单来说,就是每次改进完模型后,立马就回产生新的构型,新的构型经过测试,我们把误差大的挑出来重新打标签,进而丰富数据库。
最后,在表示高维空间函数深度学习的技术方面使用主动学习,关键之处在于误差估计,怎么样能够把误差通过第一性原理计算给估计出来,将会是设计的核心。


第五位主讲人是来自北京大学的张志华教授,他的报告题目是《数学工程——理解机器学习的一种角度》。

机器学习与人工智能从本质上来讲还是很不一样的,它并不是模拟人的思维和行为,而是通过经验和交互的方式去改善性能。实际上它是研究算法的学科,这个算法基于数据型算法,然后再反馈到数据里去。可以按这个思路理解机器学习:我拥有一个数据,如何把它作为一个表示,或者获得一个特征,再基于这个表示特征达到预测和决策的目的。
当中较有代表性的,毫无疑问是基于规则的学习,该方法的重点是特征工程,这也意味着,需要对领域非常了解,才有可能做成这个东西。这个事情实际存在一些问题,比如一旦做的是个深层次的推理,就会导致维数灾难。为了解决这问题,一个简单的思路是把原来基于规则的方式,环城一个非线性的模型,然后反过来弱化数据到表示的过程,基于这样的数论发展出了统计机器学习。
统计方法发展到一定的时候,大家认为数据到表示这件事情依然绕不过去,方法再强大,数据到表示如果不行还是会带来很多麻烦。于是又出现一个简单的思路,通过学习的方式来求解表示问题,也就是通过机器学习的方法来求解表示问题。
实际上,这个时期的深度学习目的还不纯粹是为了表示,关键还是为了非线性的拟合。这就导致至今还没找到有效表示网络的自然语言处理领域,发展上没图像处理领域那么快。深度学习发展到现在,面临的一个问题是无监督问题远远比有监督问题要多,且更复杂。随后就出现一个思路,把无监督问题形成与有监督类似的学习过程。
换句话说,如果有一个优化过程,是需要用机器学习方法来解决的话,统计学里就会假设这个X要生成它。那么 X 如果是连续的,我可以假设这个 X 是高斯;如果 X 的高斯假设很强,我们可以说 X 是一个高斯混合体。这个时候大家发现, X 是一个抽象的数学意识,并没有具体的物理意义,那么自然神经网络技术能不能像图像进行一样去生生成语言,而不是对数学意义上的 X 去生成。这时候就发展出类似生成对抗网络的方法来解决这样的问题,它的框架实际上就是如何形成一个优化问题。
近期流行还有强化学习,它利用规则与环境交互形成一个学习优化问题。强化学习比有监督学习具备一些先验,再利用这些先验知识形成一个优化目的,这是强化学习目前的发展情况。深度学习是在 2006 年被提出来的,直到 2012 年才落地,实际上中间五六年主流的机器学习家都在其中徘徊,很多人都没真正去跟进,换句话说,这可能是一个机遇期,但是不是一个大的机遇期,就不太好说了。
我们知道机器学习存在三个问题:有监督、无监督和强化学习。那么机器学习跟统计的关系是什么呢?原来我们认为机器学习是统计的分支,现在我们认为机器学习是现代统计学,但是它跟统计还有微妙的关系,机器学习是分类问题,而统计是回归问题,但是从回归上来讲也没有太本质的区别。
此外,机器学习往往会形成优化问题,模型你弄得再好,但是新的数据不行,机器学习就没什么用。从这个角度来理解,就是学习完了以后,还要关注泛化的问题。现代的机器学习的成功之处在于表示,深度学习不是单纯的一个非线性模型,而是一个非线性的表示。我们想要用机器学习做预测,而预测是通过计算得来的,所以说一个好的表示要适合最终的预测,而且这个表示也要适合我的计算。
深度学习目前也遇到很多挑战,第一个是对于大数据的要求,往往会带来过参数的问题。另外,我做的这个表述是基于多层表述,所以问题是高度的非凸化,这是它的基本问题。机器学习要关注的重点问题有四个:可泛化性、可计算性、稳定性、可解释性。现在大家都强调可解释性,但是重点应该是稳定性和泛化性这个层面。多级技术、正则化和规范技术、集成+平均化的技术、自适应方法都可以在客观上帮助我们解决这些问题。
最后我总结一下,为什么我要提出数学工程的概念。数学里的概率论、随机分析这些东西是可以来研究AI的数学机理。就算有了模型,最后我们都要通过计算来表示这个结果。这个计算一共可分为三个方面,第一个方面是数据分析,求解连续问题的算法,另外是离散算法,这个可以看作是求解离散结构的算法,还有大规模的集散的构架问题。这些我们可以认为是个工程,这些东西可以通过计算的工程思路把数据问题给实现出来。
应用数学最重要的魅力在于提出问题的思路和途径,而不仅仅来证明定理,工程即是技术,也是一种艺术,它是算法的必要补充。没有计算图、自动微分这样的工程工具,深度学习根本不可能得到推广。深度学习里的很多技巧都是工程的,但是它也是数学的东西包含在内。如果强化学习能够获得巨大成功,那么我相信数学与工程的发展也将随之形成一个巅峰。

“智源论坛——人工智能的数理基础”的首场报告至此圆满结束,接下来两场报告将于 5 ⽉ 13 ⽇ & 5 月 16 ⽇举行,更多详情请关注北京智源人工智能研究院官网:
https://www.baai.ac.cn

点击阅读原文,加入强化学习论文讨论小组


