一个奇异值的江湖 -- 机器学习观
【数萃大数据】公众号又开办了一个新栏目,之后我们每周末会为大家分享各种趣闻趣事名人好书。
我们将连续转载史春奇老师高品质的推文。感谢史春奇老师的授权以及对数萃大数据学院的大力支持!
前面我们熟悉了经典统计处理outlier的方法。 这里会说明常见的机器学习的方法。
在展示算法之前, 有几类特殊的数据类型可能需要强调一下, 因为这些数据特性会影响到具体算法的选择的:
1. 基于距离的数据 (Distance based)
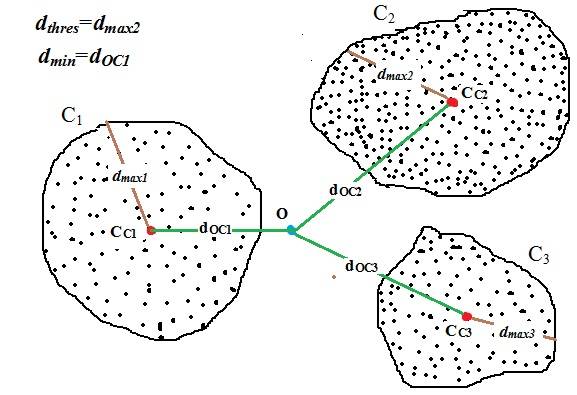
2. 相关性维度的数据 (Correlated dimensions)
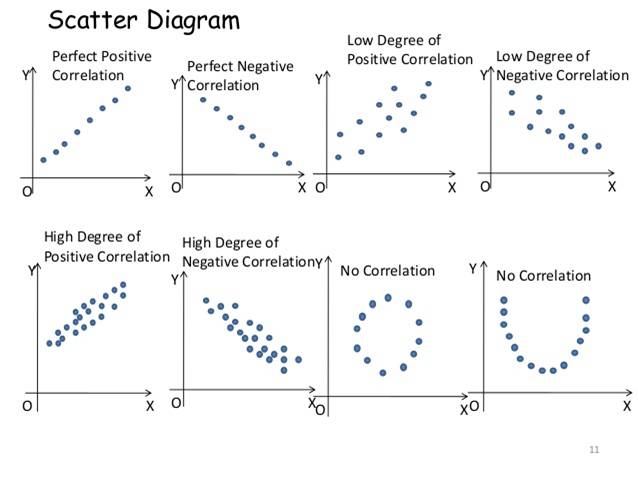
3. 类别数据 (Categorical data)

4. 高维度数据 (High dimensional)
机器学习方法
机器学习根据是否有监督一般可以分为三类: supervised, unsupervised, semi-supervised。
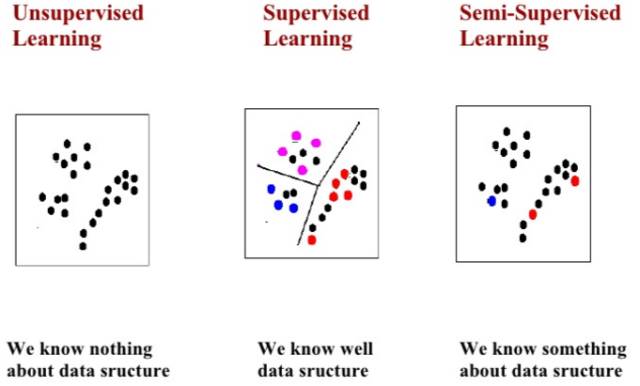
为什么要探讨这三种模式,其实主要看你是否有经验数据的积累。
1) 一般来说, 如果你之前人工收集了大量的outlier数据的积累, 你想把这些信息有效的用起来, 那么监督学习是最好的。
2) 但是如果你没有outlier的积累, 或者这种手工积累太麻烦, 你就希望自动找出一些outlier来。
3) 如果你通过无监督找到一部分oulier,然后交互式的标记一些, 然后希望找到更为精确, 那么半监督就是一个很好的方式。
有监督 (Supervised)
1. Gaussian Mixture Model (GMM, 高斯混合模型) :
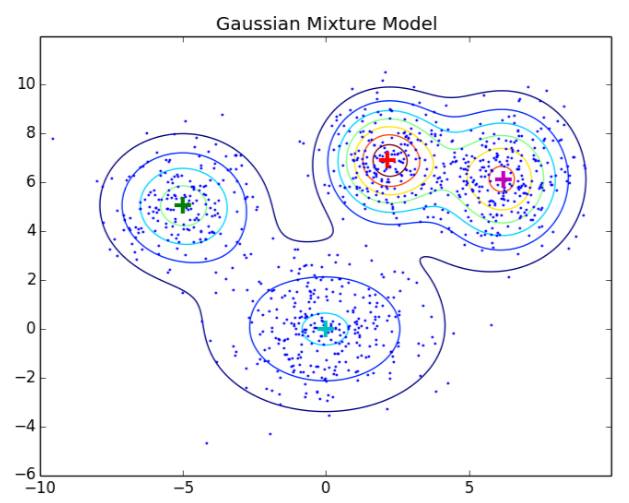
2. Bayesian Networks (贝叶斯网络)
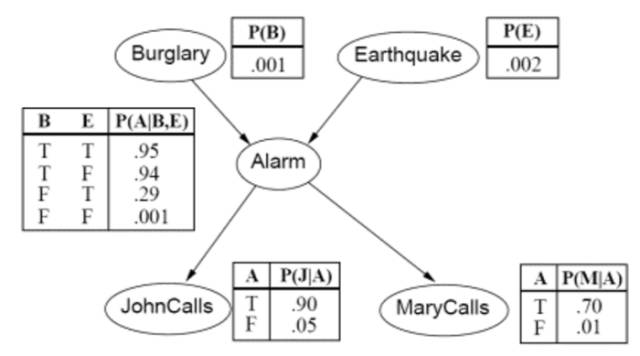
3. Support Vector Machine (SVM, 支持向量机):
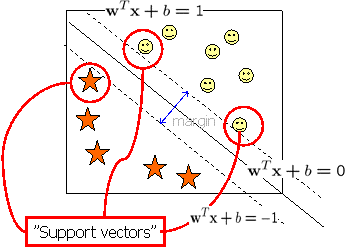
4. Multi-Layer Perceptron (MLP, 多层神经网络):
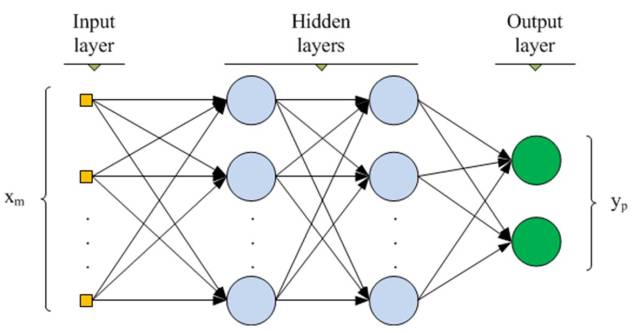
5. K Nearest Neighbor (KNN, K 近邻)
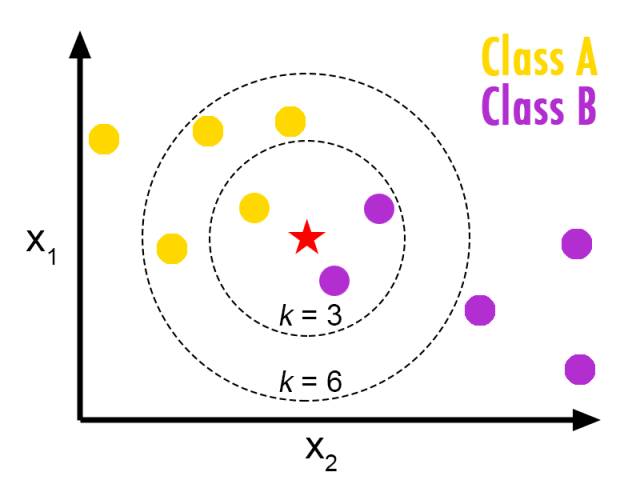
Rule-based Systems (基于规则的系统):
无监督 (Unsupervised)
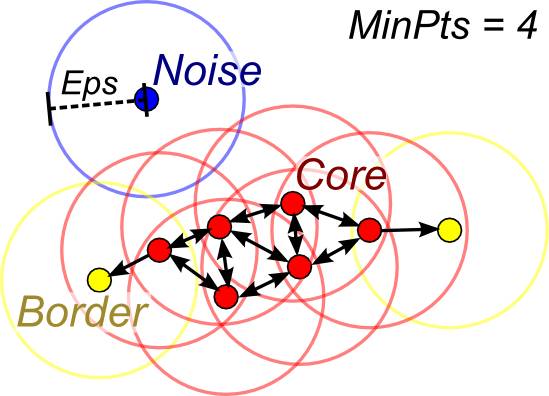
6. DBScan(Density based, 基于密度的聚类)
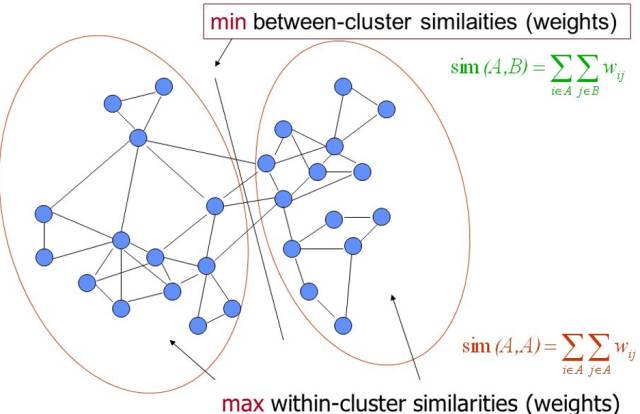
7. Spectral Clustering (谱聚类)
8. Principal component analysis (PCA, 主成分分析, Dimension Reduction, 维度压缩) 高维数据
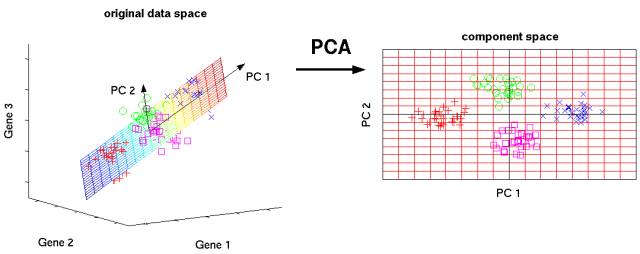
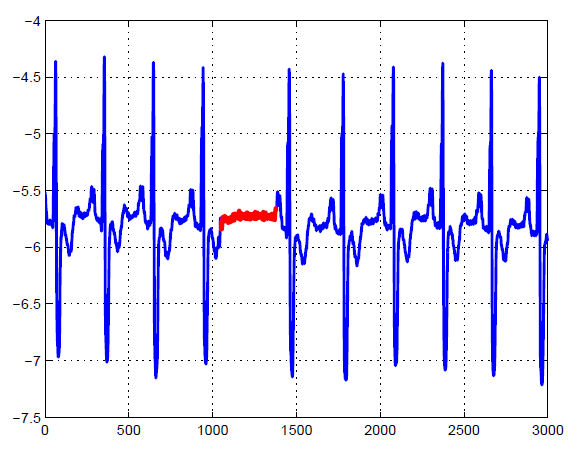
半监督 (Semi-supervised)
Collective anomaly anlaysis (聚集的奇点分析)
优缺点说明
有监督
优点:
能进一步区分outlier的更细的类别。
对于新增数据不需要重新计算
缺点:
要求有大量的标记数据集
不能捕捉未知outlier
部分分类算法不能给定是outlier的可能性
无监督
优点:
不需要已标记数据
能够给定outlier额外的距离,或者概率信息
缺点:
对样本的采集有很高要求, 要求样本分布和真是分布一直。
对于分布复杂的数据有一定局限性。
对聚类算法本身过于敏感。
新数据来的计算量会比较大。
半监督
优点:
能够兼顾有监督和无监督的优点
缺点:
没有固定的算法
需要领域背景知识
机器学习 VS 经典统计
经典统计:
优点:
统计正确,容易解释
可以看成无监督过程
缺点:
对样本和假设检验的设定要求高
对于复杂结构的数据难以处理
机器学习:
优点:
可用的方法选择多, 大量现有工具
适用的数据范围广
缺点:
1. 存在可解释性的问题




欢迎参加【杭州站】Python大数据分析培训
8月18日-22日
扫描下方二维码了解更多



