今日 Paper | 高维感官空间机器人;主动人体姿态估计;深度视频超分辨率;行人重识别等
为了帮助各位学术青年更好地学习前沿研究成果和技术,AI科技评论联合Paper 研习社(paper.yanxishe.com),重磅推出【今日 Paper】栏目, 每天都为你精选关于人工智能的前沿学术论文供你学习参考。以下是今日的精选内容——
目录
Causal Mosaic: Cause-Effect Inference via Nonlinear ICA and Ensemble Method
Intrinsic Motivation and Episodic Memories for Robot Exploration of High-Dimensional Sensory Spaces
Deep Reinforcement Learning for Active Human Pose Estimation
Kervolutional Neural Networks
Deep Video Super-Resolution using HR Optical Flow Estimation
A Strong Baseline and Batch Normalization Neck for Deep Person Re-identification
FACLSTM: ConvLSTM with Focused Attention for Scene Text Recognition
End-To-End Trainable Video Super-Resolution Based on a New Mechanism for Implicit Motion Estimation and Compensatio
TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images
Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification
因果马赛克:通过非线性ICA和集成方法进行因果推断
论文名称:Causal Mosaic: Cause-Effect Inference via Nonlinear ICA and Ensemble Method
作者:Wu Pengzhou /Fukumizu Kenji
发表时间:2020/1/7
论文链接:https://paper.yanxishe.com/review/8418
推荐理由:作者解决了在双变量设置中区分因果关系的问题。基于非线性独立分量分析(ICA)的最新发展,作者训练了允许非加性噪声的非参数通用非线性因果模型。此外,作者建立了一个整体框架,即因果马赛克,它通过混合非线性模型来模拟因果对。
作者在人工和现实世界基准数据集上将此方法与其他最近的方法进行了比较,并且其方法显示了最新的性能。


高维感官空间机器人探索的内在动机和情节记忆
论文名称:Intrinsic Motivation and Episodic Memories for Robot Exploration of High-Dimensional Sensory Spaces
作者:Schillaci Guido /Villalpando Antonio Pico /Hafner Verena Vanessa /Hanappe Peter /Colliaux David /Wintz Timothée
发表时间:2020/1/7
论文链接:https://paper.yanxishe.com/review/8419
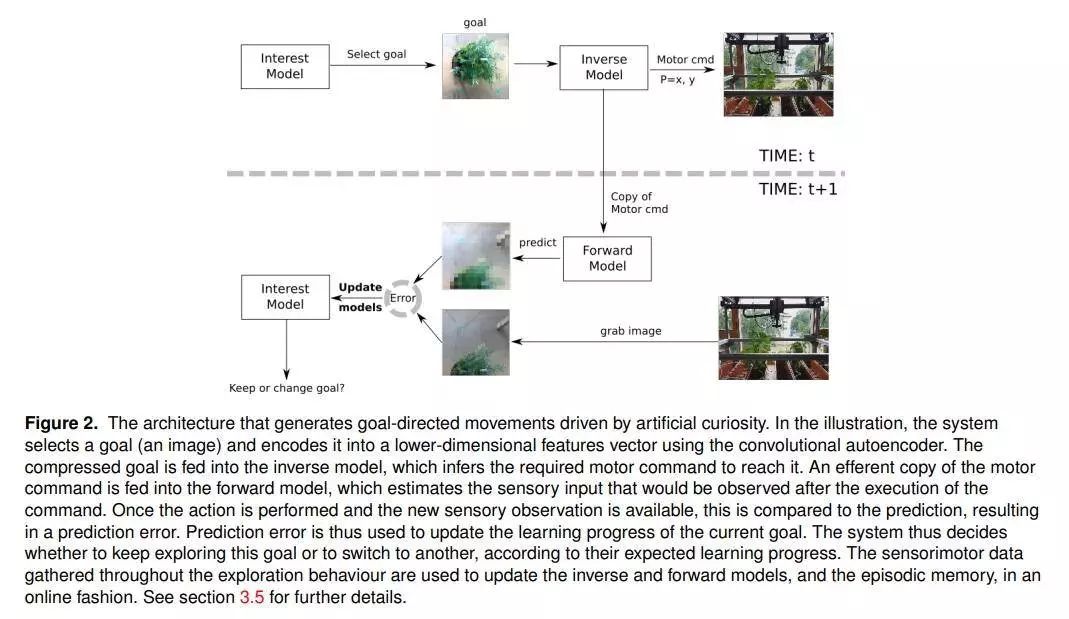
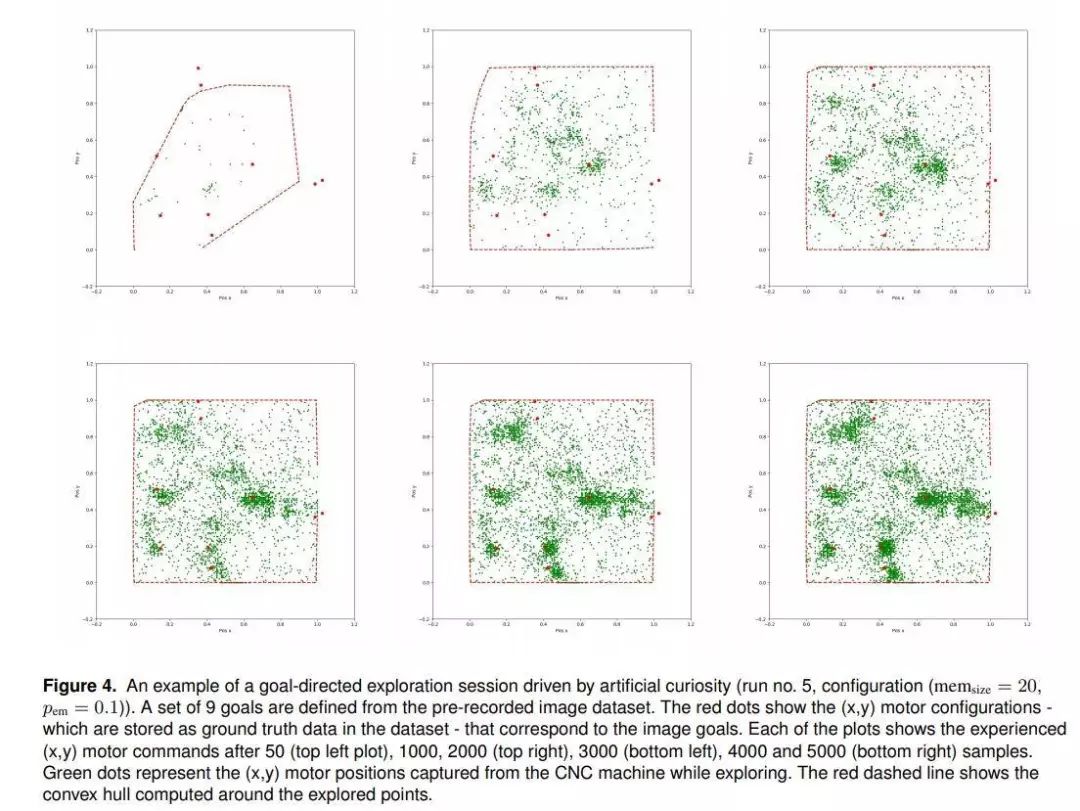
推荐理由:本文的工作提出了一种体系结构,该体系结构可以为微型农业机器人的图像传感器生成好奇心驱动的目标导向的探索行为。已经使用了深度神经网络的组合,用于从图像中进行离线的无监督学习,以进行低维特征的学习,以及用于浅层神经网络的在线学习,用于表示系统的逆向运动和正向运动学。人工好奇心系统将兴趣值分配给一组预定义的目标,并将探索驱向那些有望最大程度地提高学习进度的探索。
作者建议将情景记忆整合到内在动机系统中,以应对灾难性的遗忘问题,这些问题通常在执行人工神经网络的在线更新时会遇到。我们的结果表明,采用情景存储系统不仅可以防止计算模型迅速忘记先前已获得的知识,而且还为调节模型的可塑性和稳定性之间的平衡提供了新途径。


用于主动人体姿态估计的深度强化学习
论文名称:Deep Reinforcement Learning for Active Human Pose Estimation
作者:Gärtner Erik /Pirinen Aleksis /Sminchisescu Cristian
发表时间:2020/1/7
论文链接:https://paper.yanxishe.com/review/8416
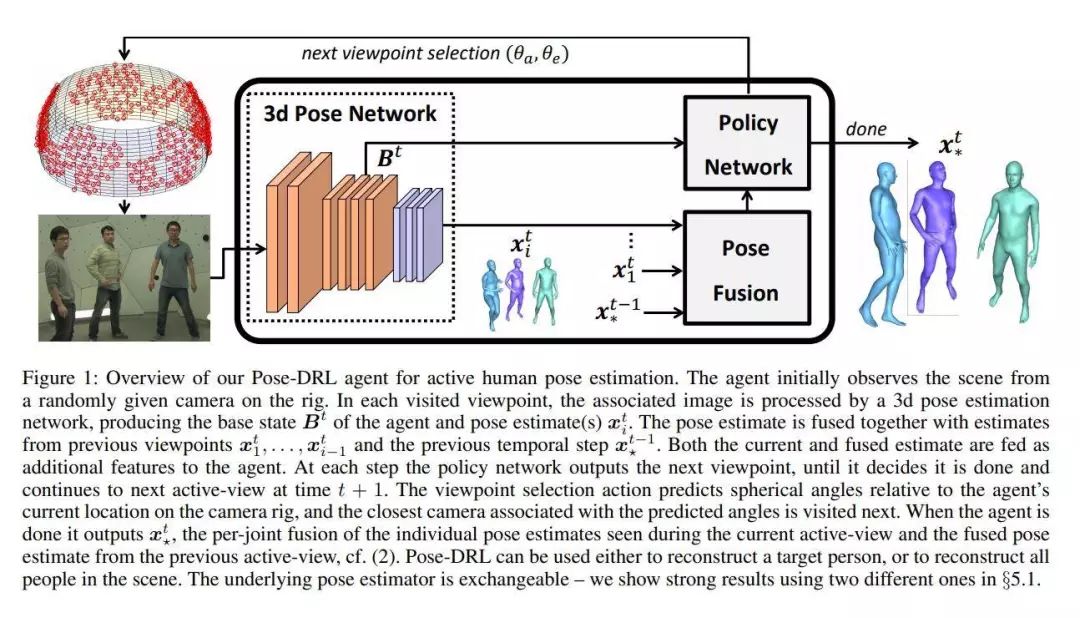
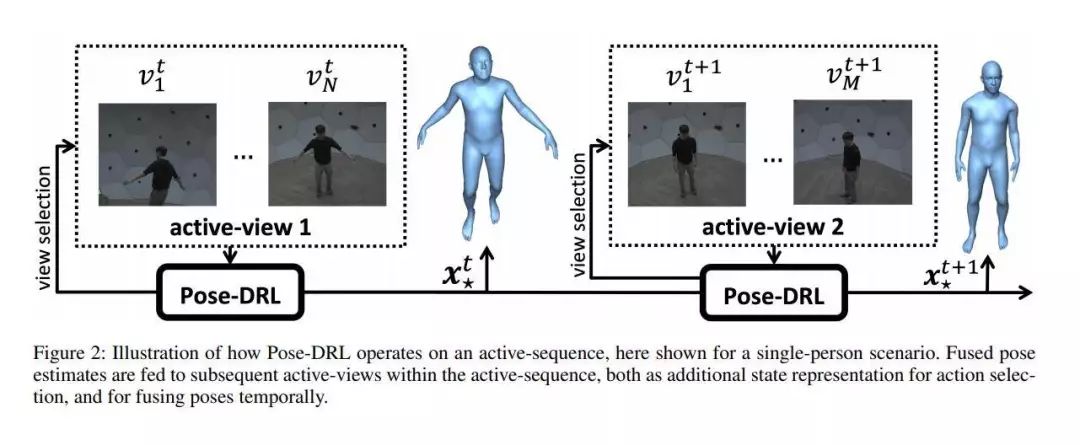
推荐理由:已有的3D人体姿势估计方法都假定从一个视频或者多个视角中收集的场景图像是可以用的,因此它们专注于通过融合空间或时间信息来利用先验知识和度量信息。这篇论文研究了主动观察者可以自由移动并探索场景的3D人体姿势估计问题,并提出了一个名为Pose-DRL的基于增强学习的人体姿势估计模型。Pose-DRL可以在空间和时间维度上选择最好的视角来进行姿势估计。在Panoptic多视角数据集上的实验表明,与基准模型相比,Pose-DRL学会了如何选择能够产生更为准确的姿势估计值的视角。


内核卷积神经网络
论文名称:Kervolutional Neural Networks
作者:Wang Chen /Yang Jianfei /Xie Lihua /Yuan Junsong
发表时间:2019/4/8
论文链接:https://paper.yanxishe.com/review/8415
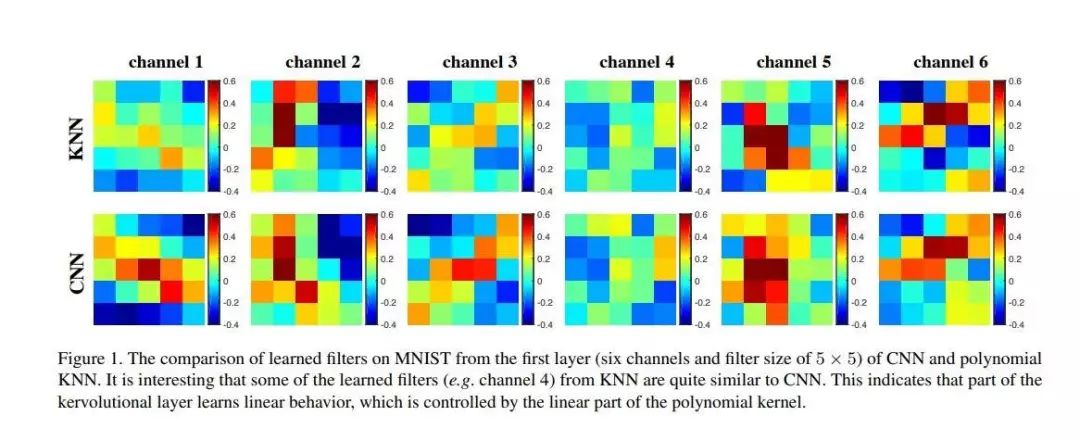
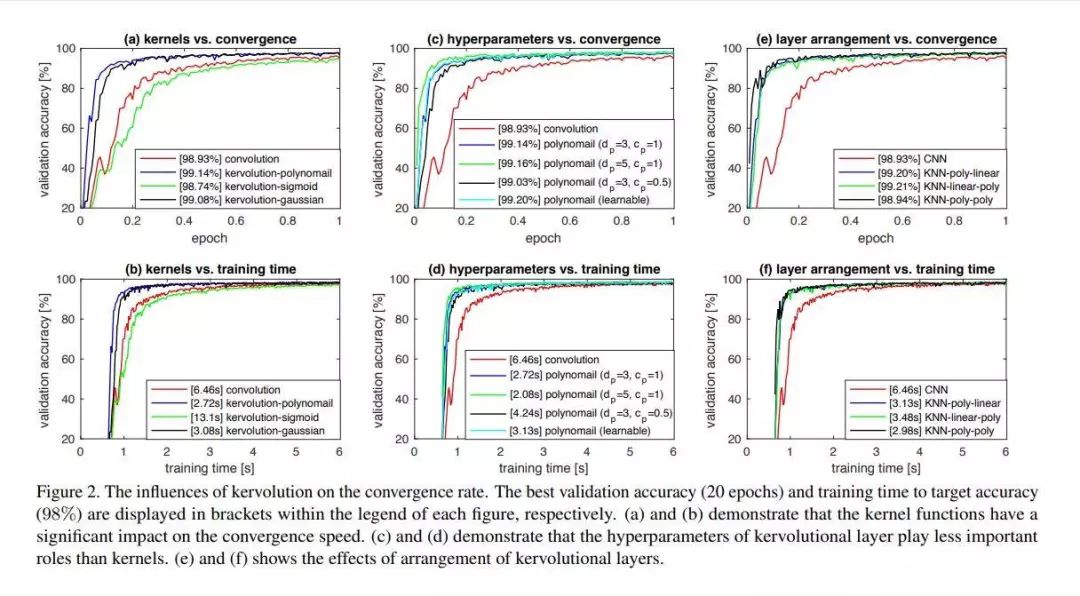
推荐理由:现有的卷积神经网络相关的研究大多依赖于激活层,而现有的激活层只能提供逐点非线性。为了解决这个问题,这篇论文提出了一种新的内核卷积(Kervolution)运算,利用内核技巧来近似人类感知系统的复杂行为。内核卷积操作通过逐块内核函数来增强模型容量并捕获要素的高阶交互,而无需引入其他参数。大量的实验表明,与基线CNN相比,基于内核卷积的神经网络具有更高的准确性和更快的收敛速度。

利用光流重构估计的深度视频超分辨率
论文名称:Deep Video Super-Resolution using HR Optical Flow Estimation
作者:Wang Longguang /Guo Yulan /Liu Li /Lin Zaiping /Deng Xinpu /An Wei
发表时间:2020/1/6
论文链接:https://paper.yanxishe.com/review/8414
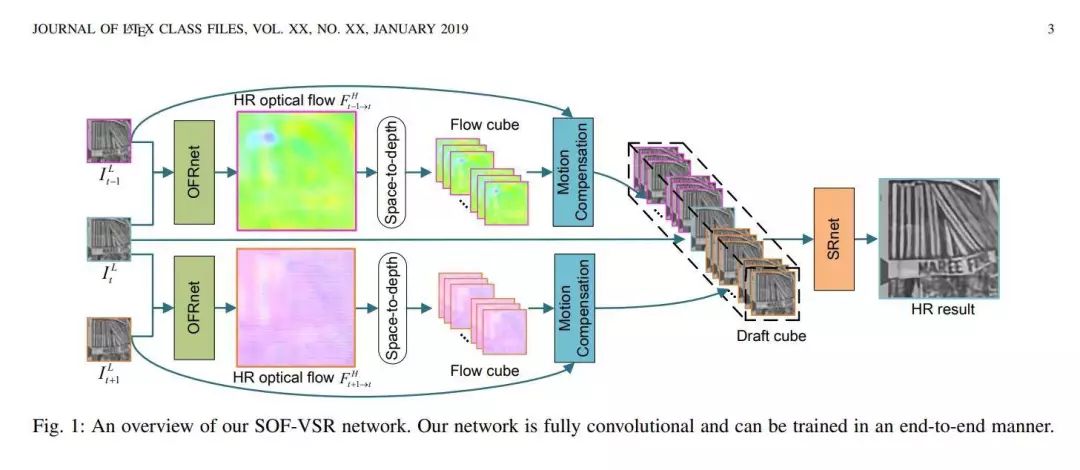
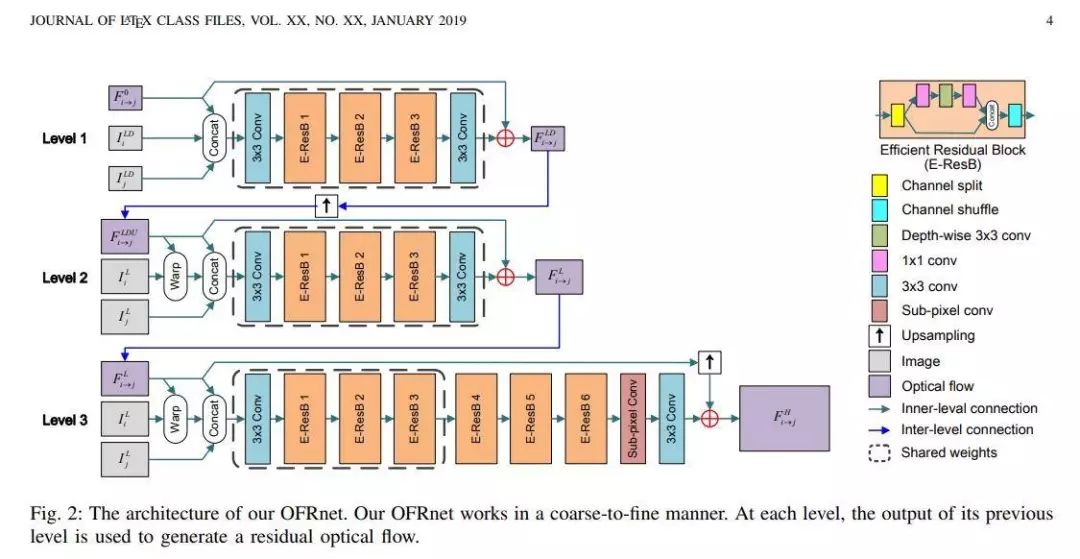
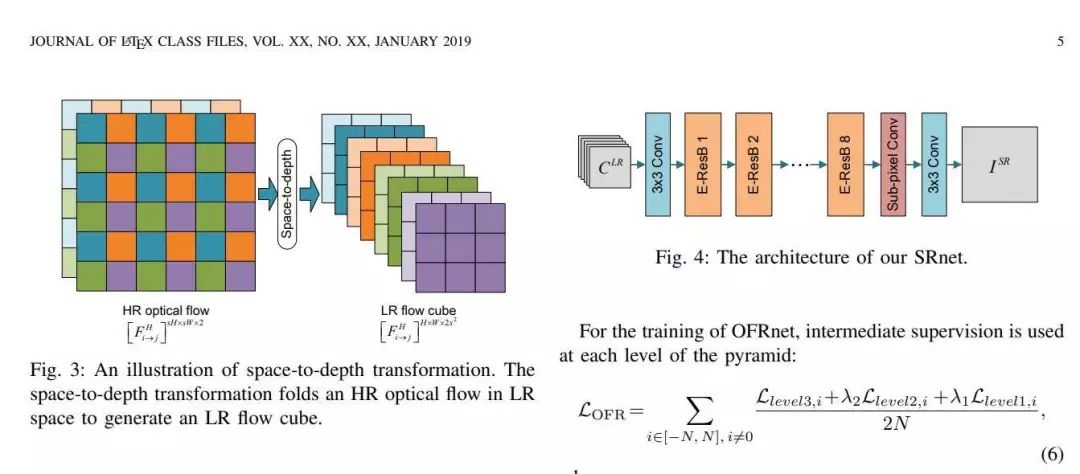
推荐理由:现有的基于深度学习的方法通常会估计低分辨率帧之间的光流以提供时间依赖性,但是低分辨率光流和高分辨率输出之间的分辨率冲突会妨碍帧中的细节恢复。为了解决这个问题,这篇论文提出了一种名为Optical Flow Reconstruction Network (OFRnet)的端到端的光流重构网络,其中来自低分辨率帧的光流提供了准确的时间依赖性,并最终提高了视频超分辨率任务的性能表现。文章使用高分辨率光流执行运动补偿以对时间依赖性进行编码,最终低分辨率输入会作为一个超分辨率网络的输入,从而生成超分辨率结果。这篇论文中的实验证明了高分辨率光流对改善超分辨率性能的有效性,在Vid4和DAVIS-10数据集上的实验也证明了OFRnet达到了SOTA的性能表现。


拓展阅读
由于篇幅有限,剩余五篇的论文推荐精选请扫描下方二维码继续阅读——
用于深度行人重识别的强基线和批量归一化结构
论文名称:A Strong Baseline and Batch Normalization Neck for Deep Person Re-identification
FACLSTM:重点关注场景文本识别的ConvLSTM
论文名称:FACLSTM: ConvLSTM with Focused Attention for Scene Text Recognition
基于一种新的隐式运动估计和补偿机制的端到端可训练视频超分辨率
论文名称:End-To-End Trainable Video Super-Resolution Based on a New Mechanism for Implicit Motion Estimation and Compensation
TableNet:用于从扫描的文档图像进行端到端表格检测和表格数据提取的深度学习模型
论文名称:TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images
相互均值教学:用于提炼行人重识别的无监督领域适配伪标签
论文名称:Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification

(扫码直达,可直接跳转下载论文)
阅读原文浏览剩余五篇论文推荐
↓↓↓
