ICLR 2020 匿名评审九篇满分论文,最佳论文或许就在其中
从反传的自动微分机制,到不平行语料的翻译模型,ICLR 2020 这 9 篇满分论文值得你仔细阅读。


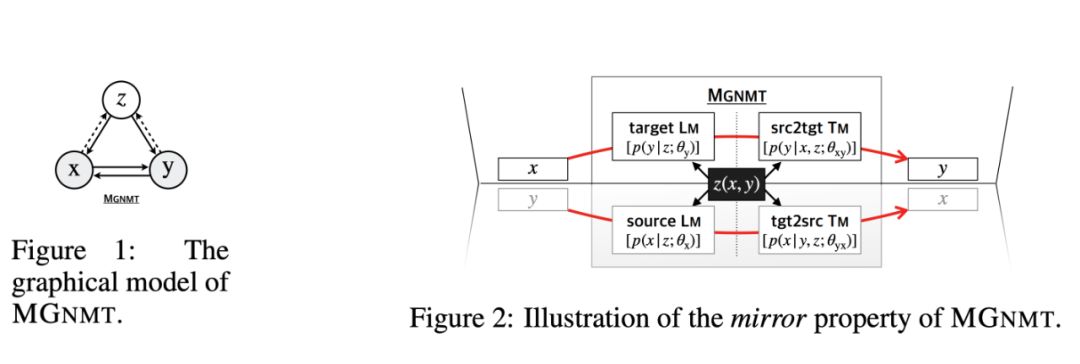

登录查看更多
相关内容
专知会员服务
11+阅读 · 2019年12月28日
Arxiv
7+阅读 · 2019年6月14日




相关VIP内容
专知会员服务
11+阅读 · 2019年12月28日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年6月14日