【NeurIPS2020-华为】DynaBERT:具有自适应宽度和深度的动态BERT

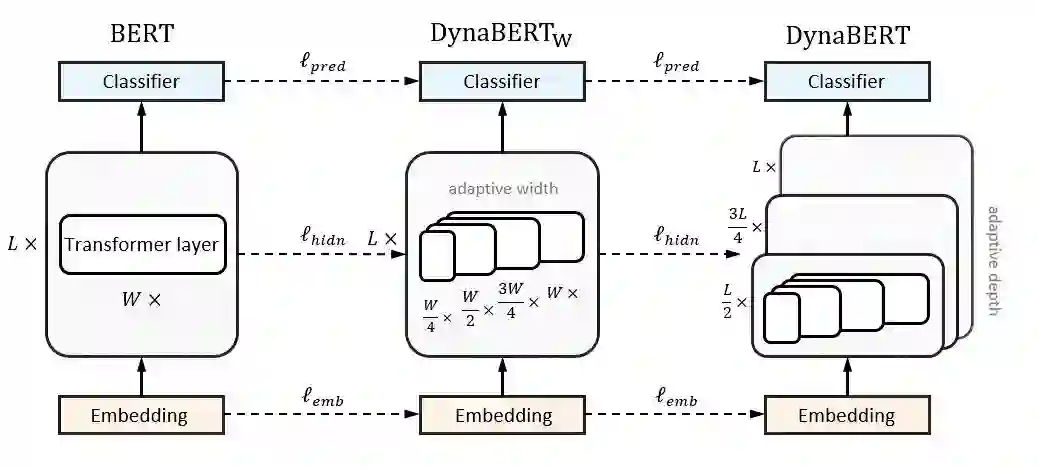
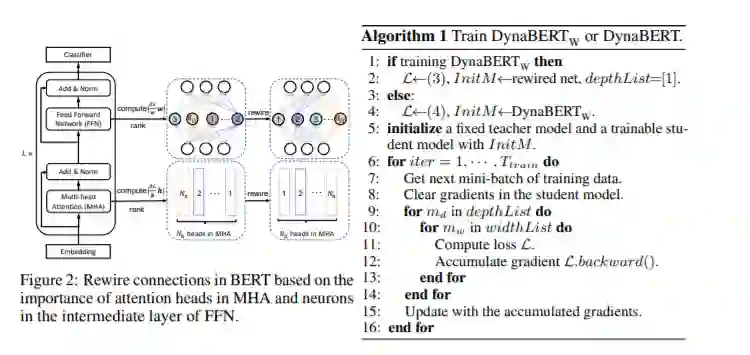
近来,基于Transformer结构的预训练语言模型(如BERT和RoBERTa)在自然语言处理任务上取得了显著成果。但是,这些模型参数量巨大,限制了其在存储、计算、功耗等性能有限的边缘设备上的部署。将BERT部署到这些设备的困难体现在两个方面:(1)各种终端设备性能各不一样,怎么给不同性能的设备部署适合自身性能的模型;(2)同一个终端设备在不同的情况下可接受的运行BERT模型的存储、计算和功耗也不一样。为了解决这个问题,我们提出了一种宽度和深度可伸缩的动态预训练模型DynaBERT。与以往将BERT网络压缩到固定大小或者只在深度方向做可伸缩的方法相比,本文第一次提出来在BERT宽度方向进行可伸缩训练。宽度可伸缩通过调整Transformer层可以并行计算的注意力头和全连接层中间层神经元数目达到。本文还针对宽度方向提出了新颖的网络重连方式使得重要的注意力头和神经元被更多的子网络共享。在基准数据集上的实验结果表明,该模型通过新颖的知识蒸馏策略显著提升了子网络在NLU任务上的准确率。该模型可以根据不同设备的硬件性能部署不同宽度和深度的子网络。并且一旦某个设备部署了BERT模型,该设备也可以根据自身资源条件动态加载已部署模型的一部分进行推理。代码已经开源在https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/DynaBERT。
https://www.zhuanzhi.ai/paper/c3d0e1a923f1659db405ff8b974de647
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DynaBERT” 可以获取《【NeurIPS2020-华为】DynaBERT:具有自适应宽度和深度的动态BERT》专知下载链接索引






