在2019中国人工智能产业年会分论坛——“知识智能及其产业应用论坛”上,东南大学计算机科学与工程学院教授张敏灵发表了题为《偏标记学习的研究》的报告。
张敏灵教授:2007年南京大学计算机科学与技术系博士毕业,现任东南大学计算机科学与工程学院教授。主要研究领域为机器学习与数据挖掘。现任中国人工智能学会机器学习专委会秘书长、中国计算机学会人工智能与模式识别专委会常务委员、江苏省人工智能学会学术工委主任等。担任《ACM Trans. IST》、《Neural Networks》、《Frontiers of Computer Science》等国际期刊编委、《中国科学:信息科学》青年编委等。应邀担任ACML'18大会主席、PAKDD'19、ACML'17、PRICAI'16等程序主席以及IJCAI/AAAI/ICDM等国际会议SPC或领域主席20余次。获CCF-IEEE CS青年科学家奖(2016)。
获取张敏灵教授相关科研信息,请登录AMiner网站:
https://www.aminer.cn/profile/minling-zhang/53f42d38dabfaee0d9afa76f
在本次报告中,张敏灵教授对偏标记学习的研究现状做了全面梳理总结。
他从三方面内容介绍了偏标记学习的研究现状:一是简要讨论偏标记学习的问题设置及其与相关弱监督学习框架的关系;二是对现有偏标记学习算法进行总结并介绍张教授所在团队在该方面的最新工作;三是给出偏标记学习的相关学术资源。
![]()
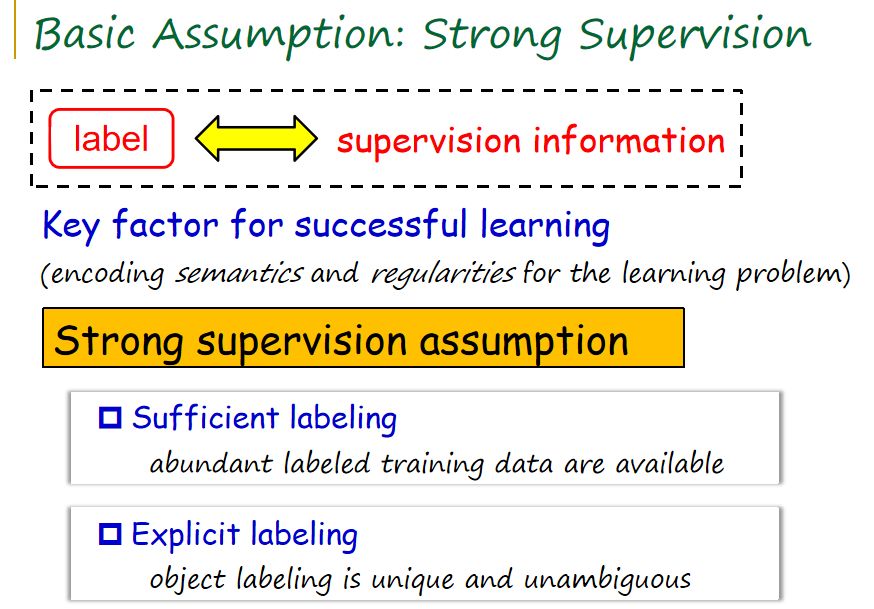
针对第一个部分的讲解,张教授从“监督信息”入手,指出“设计一系列标记训练样本并将其交给监督学习算法可以得到一个预算模型,我们可以基于这个预算模型预测新对象的标记。传统监督学习里面有一个重要概念就是标记,通常叫做监督信息。”而监督信息的质量很大程度上决定着监督学习问题的成败。
由此出发,张教授向大家解释了标记学习中涉及到的重要问题,即“强监督假设”。其主要分为两个方面:一,强监督假设能充分标记信息,从而在训练集当中获得充分多标记训练样本。二,强监督假设通常假设这个标记信息是明确,且每个标记对象是唯一的。即如果标记信息唯一,则满足强监督假设。
![]()
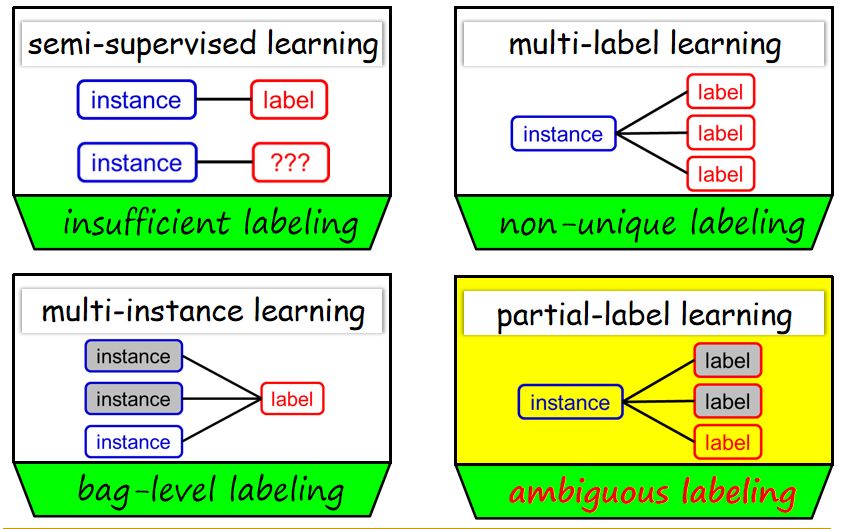
而弱监督学习概念相对泛化,作为机器学习中非常重要的研究之一,其发展较为成熟的方向便是大家熟知的半监督学习。该类学习的特点是只涉及到少量标记数据,大量数据都是未标记的,即标记信息不充分。
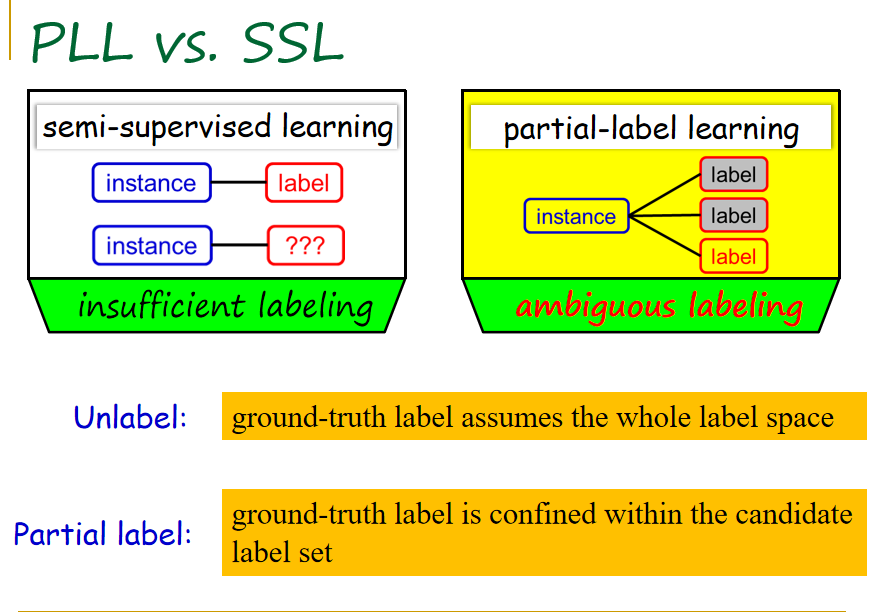
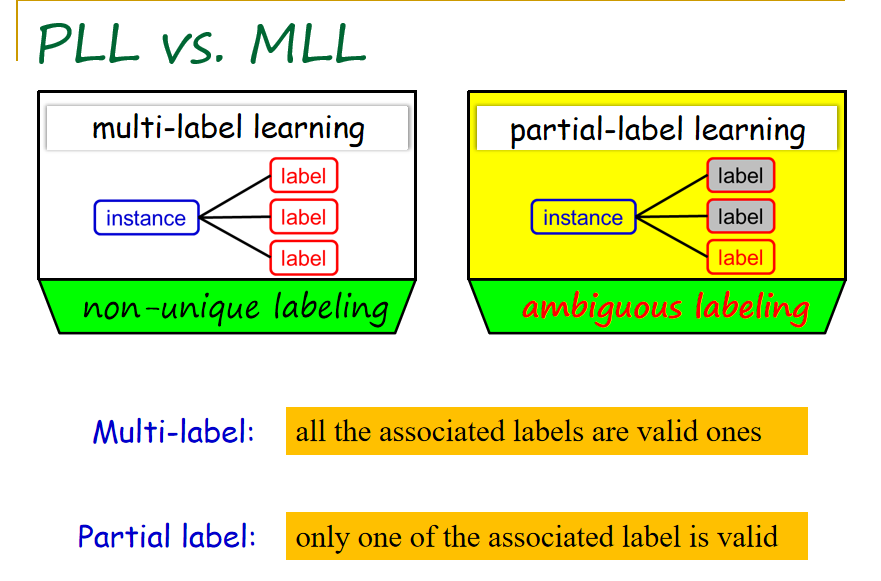
例如在多标记学习中,每一个对象可以有多个标记,即这个对象标记的信息不再满足唯一性。与之相对,偏标记学习指每一个事例可能会对应多个标记,我们称之为侯选标记。这些标记当中只有一个标记是这个对象正式的标记。虽不明确具体在哪个标记,但这个真实标记一定是在侯选标记中的,这便是偏标记学习问题的基本设置。
![]()
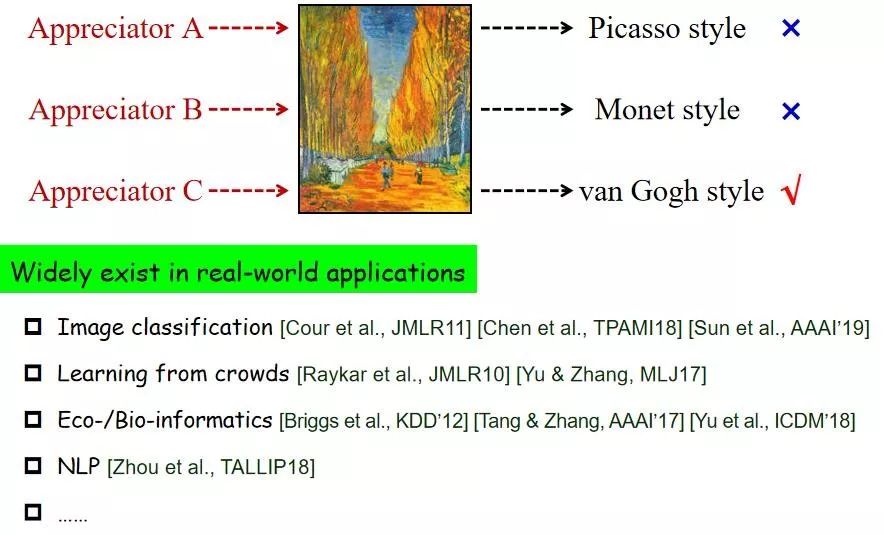
对于偏标记学习的框架设计,张教授用一个简单例子进行了解释:“假设现在有一幅油画,请大家判断一下是什么风格。不同人给出不同答案,这样便可以获得关于这个对象多个侯选标记,但显然在多个标记当中只有一个标记是正确的。”这只是一个非常简单的例子,实际上偏标记学习问题在很多真实学习建模任务当中都会遇到,包括图片分类、自然语言处理等任务。
![]()
张教授将偏标记学习和半监督学习进行了比较。其相同之处在于,半监督学习中未标记对象的真实标记是不明确的;偏标记学习中训练样本的标记也是不明确的。不同之处在于,对于半监督学习,真实标记取值空间或者范围是整个标记空间,其中任何一个标记都可能是它的真实标记。对于偏标记学习,真实标记取值范围只能位于侯选标记集合中,其标记范围是限定的。
![]()
如果将偏标记学习与多标记学习进行对比,相同之处在于:多标记学习和偏标记学习中每个对象均有多个标记;不同之处在于:多标记学习中,假设对象的多个标记都是它的真实标记,但在偏标记学习中,假设对象多个侯选标记里面只有一个是它的真实标记。
![]()
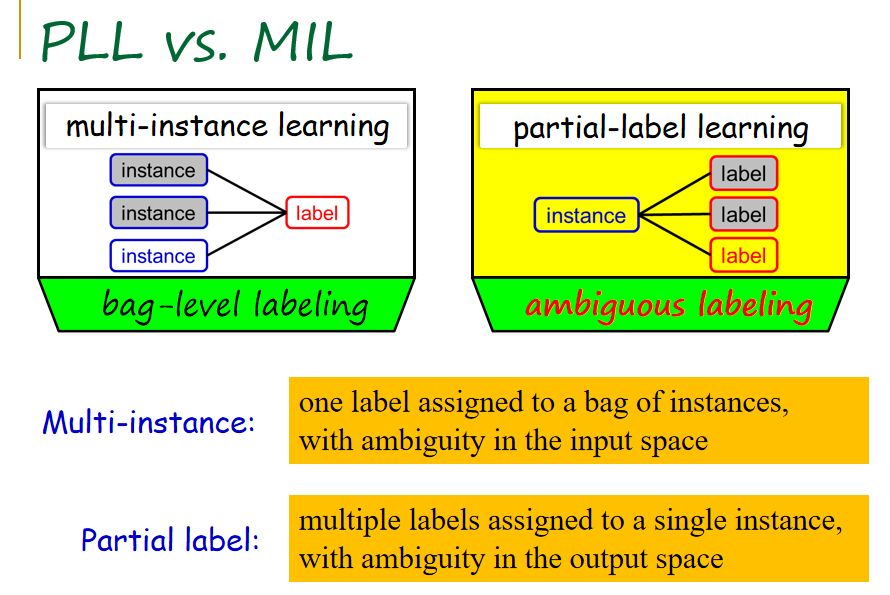
如果把偏标记学习与多事例学习做对比,相同之处在于,基于对象和事例的标记都是未知的。不同之处在于,对于多事例学习而言,它的歧异性出现在输入端,每一个对象由多个事例表示;而偏标记学习的歧异性出现在输出端,其有多个侯选标记,但并不知道哪一个为真实标记。
![]()
针对本报告的第二部分“偏标记学习的算法”,张教授指出:算法是机器学习和计算机科学的核心研究问题。当前在偏标记学习领域中有一个形式化定义,即“假设大X是特征空间,大Y是标记空间,对于偏标记学习问题而言,它的输入为一个训练集,有M个样本,每一个样本是XI和XI的配对。XI是一个特征向量,它是整个标记空间的一个子集,我们称之为‘与XI相关侯选标记集合’。其基本假设是,该对象的真实标记一定是落在侯选标记结合里的,但不明确具体为哪一个。”
由上述特征我们可以看到,偏标记学习最核心的策略是做消歧,基本策略是对某一个样本的真实标记做某种形式的估计,这也是张教授团队目前着重研究的方向。如果两个数据对象在输入空间里面比较相似,输出空间对应的标记或者语义也应该是比较相似的。张教授指出:“特征空间当中这种结构化信息实际上可以帮助我们在输出空间中对对象做消歧。”
![]()
张教授为我们举了一个例子:假设现在有一个偏标记训练样本,是X,对应侯选标记是Y2和Y3,没有任何知识情况下难以判断哪一个是真实标记,它们成为真实标记的执行度都是一样的。假设现在训练集当中有另外两个样本,X1对应侯选标记Y1,Y2;X2对应侯选标记Y3,Y4,则可以观察X1和X2在输出空间的关系。假设发现X1与X2两个对象在输入空间比较近,则其在输出空间当中具有相同真实概率比较大。
针对偏标记学习问题的最终目标,张教授指出,其是为了构建一个多类分类器,得到一个特征空间到标记空间的映射。“做多分类问题一个最常见策略就是做二类分解。其有两个基本策略,一个是一对多分解,还有一种是一对一的分解。如果是做一对多分解,假设多类分的问题里面有Q个标记,每次把其中一个标记看成正类,剩下所有标记看成负类,这样可以构造一个二类分类器,整个做下来一共可以得到Q个二类分类器,测试阶段判断一下哪一个二类分类器输出最大,我们就认为这个对象属于哪一个类”。
如果做一对一的分解,任意取两个标记做一个配对,其中一个作为正类,另外一个作为负类,就可以构造一个CQ2二类分类器,测试时候把每一个二类分类器输出看成某一个标记上投的一票,最后算一下哪一个标记得票最多,我们就认为这个对象应该属于哪一个标记。
![]()
除了上述内容,在多类分解问题中还有一种常见的二类分类策略,即纠错输出编码。张教授认为只要对它进行一个非常简单的改造,就可以让它很自然地用于求解偏标记学习问题。这种二类分解策略是基于ECOC实现的,最后得到的方法有一个非消歧的重要性质,即不再尝试对这个对象侯选标记做任何消歧操作。
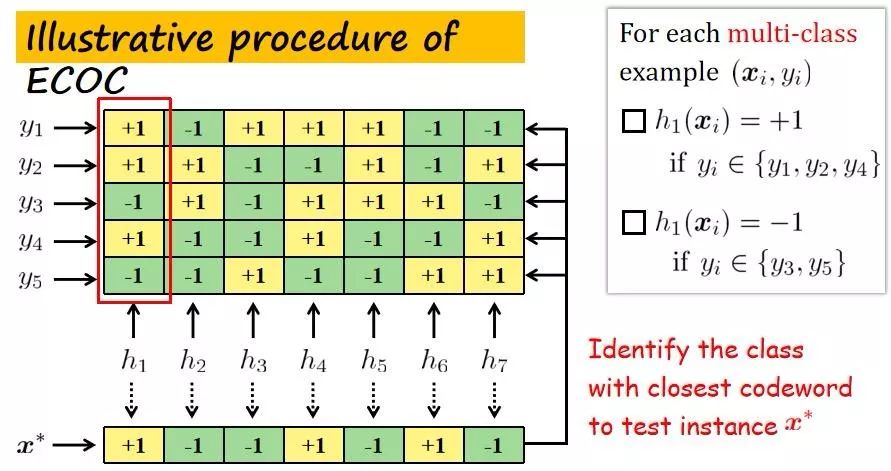
张教授为我们举例讲解了ECOC是如何做非消歧的:“假设现在有五个标记,ECOC求解多类分类问题会利用到一个编码举证。每一行是和一个标记相对应的,每一个元素要么正一,要么负一。ECOC方法进行建模的时候,针对编码举证,每一类都会构造一个二类分类器。具体怎么构造呢?”
以第一类作为一个例子,Y1Y2Y4对应编码值是+1,Y3和Y5对应编码值是-1,这样便可以把Y1,Y2,Y4看成一个正划分,Y3和Y5看成一个负划分。这个时候对于任何多类训练样本,每一个对象都有一个对应标记是训练样本。如果Y2落在正划分里面,我们就认为这个训练样本是一个正样本,如果Y2落在负划分里面,我们便认为这个训练样本是一个负样本。
ECOC原理示意图
报告的最后,张教授为我们提供了有关偏标记学习的数据资源。
![]()
![]()
![]()
公众号后台回复“张敏灵PPT”,即可获取张敏灵教授完整版PPT。