npj: 机器学习——无机材料合成的科学“炒菜法”
海归学者发起的公益学术平台
分享信息,整合资源
交流学术,偶尔风月

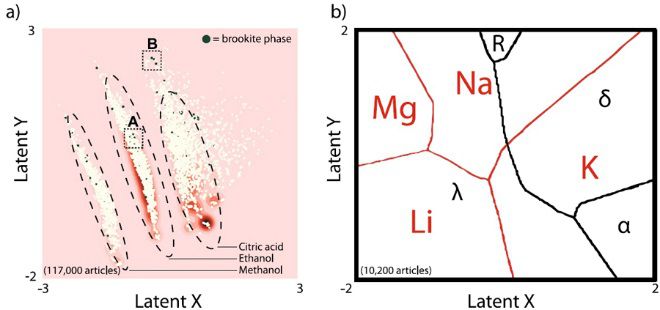
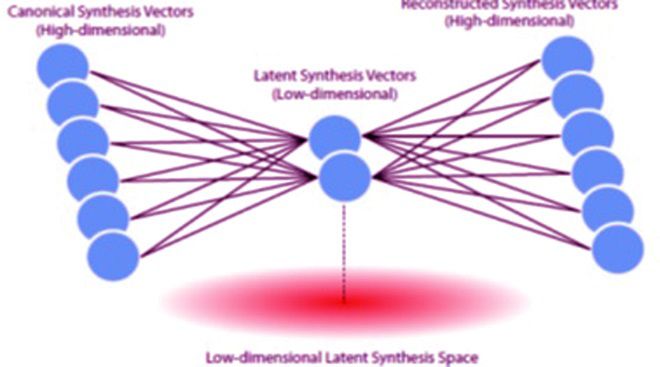
传统的无机材料合成方法少有理论指导,经验为上,被誉为“炒菜法”。近十年来第一原理计算和机器学习算法两种技术快速发展,使得材料虚拟筛选方法种类迅速增长,但由计算驱动的材料合成筛选法,却一直深陷数据稀疏性和稀缺性的困境,蹒跚不前,仍处起步阶段,不但合成工艺仍落在难以直接优化的、稀疏的、高维参数的空间,而且一些有趣材料的合成也鲜有文献报道。来自麻省理工学院的Elsa Olivetti教授等开发了一种算法,用来量化合成参数和潜在驱动因素与合成结果之间的关系。他们发现,用变分自编码器将稀疏合成表达方式压缩到较低维空间,可以提高机器学习的工作能力;用材料合成的一些代表性关键参数(如反应温度)来简化问题的复杂性、训练相关的算法。最终该算法能为实验合成一些化合物而“学习”,从而给出新的合成方法,比如钛酸锶的合成参数和一些其他无机氧化物的合成方法。该文近期发表于npj Computational Materials 3:53(2017); doi:10.1038/s41524-017-0055-6。
英文标题与摘要如下,点击阅读原文可以自由获取论文PDF。
Virtual screening of inorganic materials synthesis parameters with deep learning
Edward Kim, Kevin Huang, Stefanie Jegelka & Elsa Olivetti
Virtual materials screening approaches have proliferated in the past decade, driven by rapid advances in first-principles computational techniques, and machine-learning algorithms. By comparison, computationally driven materials synthesis screening is still in its infancy, and is mired by the challenges of data sparsity and data scarcity: Synthesis routes exist in a sparse, high-dimensional parameter space that is difficult to optimize over directly, and, for some materials of interest, only scarce volumes of literature-reported syntheses are available. In this article, we present a framework for suggesting quantitative synthesis parameters and potential driving factors for synthesis outcomes. We use a variational autoencoder to compress sparse synthesis representations into a lower dimensional space, which is found to improve the performance of machine-learning tasks. To realize this screening framework even in cases where there are few literature data, we devise a novel data augmentation methodology that incorporates literature synthesis data from related materials systems. We apply this variational autoencoder framework to generate potential SrTiO3 synthesis parameter sets, propose driving factors for brookite TiO2 formation, and identify correlations between alkali-ion intercalation and MnO2 polymorph selection.
媒体转载联系授权请看下方





