自然语言处理技术在商业领域可以支持哪些应用?


人工智能和机器学习技术在很多领域已经取得了重大进展。就某些任务而言,人工智能已经超越了人类的水平。在这波新的 AI 浪潮中,图像识别和语音处理技术方面的突破给人的印象最深刻。相比较它们而言,自然语言处理 (NLP) 领域的进展却给我们一种很滞后的感觉。
NLP 领域中目前比较突出的一点是机器翻译(MT)技术:最近的基于神经网络的方法明显优于传统的机器翻译方法。但有人认为,端到端的神经网络方法并不真正“理解”所处理的自然语言的含义。虽然我们可能会讨论什么是“理解”,但机器翻译的质量,尤其是长句的质量,确实还有很大的提升空间。
与此同时,很多人对 NLP 技术如何推动各种新旧业务的发展抱有很大的热情。我有一位非常聪明的炒股朋友,想知道 NLP 技术是否可以帮助他阅读财经新闻并提供贸易前景的建议,以便扩大他的贸易规模。我的另一位朋友正在探寻制作聊天机器人的方法,他想让这种机器人有足够的知识与患者交谈并进行医学诊断。还有一位朋友,他希望创建一个可以百分百信任的私人助理,每个人都可以与它分享自己的全部想法,这样它可以为每个人提供一些私人的生活建议,让用户感觉更快乐,生活更积极。我们距离实现这些愿景还有多远呢?
NLP:The State-of-the-Art
在深度学习浪潮到来之前,传统的 NLP 任务,如词性标注 (POS tagging),句法分析 (syntactic parsing),实体链接 (entity linking),语义分析 (semantic parsing) 等任务一直在缓慢而稳步地发展着。概括来说,这些任务都是文本标注的任务,可以用下面的图片形象地描绘出来。

用深度学习的方法来处理这些任务并不一定能得到更好的效果,但深度学习能让这些事情变得更加简单。例如,以前,为了训练一个解析器,我们需要构建数百万个特征,现在我们可以从 word embeddings 开始,而将剩下的部分留给神经网络去做。
是什么让 NLP 变得与众不同和如此困难,为什么深度学习能为图像识别和语音处理任务带来显著的改进,却对 NLP 任务没有太大帮助?这里有两个因素对于理解自然语言非常重要:先验和结构。
2011 年,Tenenbaum 等人提出了一个非常有趣的问题:我们的大脑是怎样从少量的知识中获取到大量的信息的?我们的大脑构建了非常丰富的世界模型,并且对输入数据进行了高度的概括,这些输入数据可能是稀疏的,嘈杂的和模棱两可的————这些信息在很多方面都远远不能支持我们所做的推论。那我们究竟是怎么做到的呢?
Tenenbaum 等人给出了令人信服的答案:贝叶斯推断。贝叶斯推断允许一个三岁的孩子在看到三匹马的图片后学会马的概念。但是这种推断可能依赖于经过亿万年地进化而悄悄植入我们大脑中先天的先验知识。
但是机器却难以获得这些用于贝叶斯推断的正确先验知识。以下是一个简单的例子(尽管不完全相关):搜索“Jordan 7 day weather forecast”,我们如何确定“Jordan”指的是什么?人类能立即知道它指的是国家“Jordan”。但一个不理解查询语句结构的简单算法可能会将“Jordan”误认为是“Jordan 鞋”(一种 Nike 品牌)。
这可能是由于它在贝叶斯推断中使用的先验是通过计算人们在网上搜索乔丹鞋与约旦这个国家的频率来估计的。这个估计是有偏差的,在我们当前的情况下尤其如此:事实证明前者比后者的搜索频率更高。有偏差的先验会导致错误的推断结果。我们是否应该用更复杂的方式来估计先验?当然。但是不能保证在所有情况下都采用更复杂的方法。

先验很重要,但更重要的是自然语言展现的递归结构。查询语句“jordan 7 day weather forecast”具有可以被映射到具有位置参数(时隙)和时间跨度参数(时隙)的“天气预报”语义帧的结构。如果算法识别到这种结构,那么它不会受到先验知识的困扰,而将 Jordan 误认为是乔丹鞋。这种方法可以更进一步地理解这个查询语句。
在最先进的网页搜索和问答/会话应用程序中,工程师会写一些规则用于捕捉自然语言输入中的结构,这会大大减少推理中的错误。但问题是,概括和扩展这种解决方案是很困难的。神经网络和深度学习促进了自然语言处理中分布式方法的使用。
通过 word2vec 和 GloVe 等词嵌入(word embeddings) 方法,可以将自然语言中的离散词语映射到连续的空间中。在这个空间中,“猫”与 “狗”两个词很接近,这使得我们可以概括出我们为“猫”和“狗”总结的结论。然而,分布式方法和先验和结构的必要性并不冲突。事实上,我们没有比单词更好的表示语句的方法,比如用短语、句子或者是段落等其他表示方法,原因仅仅是我们不知道如何有效地去建模它们的结构。此外,我们没有很好的方法去表示知识和常识,而这是解释和推理不可或缺的两样东西。
也许深度学习在图像处理中更成功的原因是因为图像中的“结构”更易于捕捉:允许平移不变性的卷积神经网络(CNN)符合要求。然而,对自然语言做同样的事却难得多。因此,我们没有看到 NLP 的突破,除了在少数几个孤立的领域中,我们碰巧有大量的训练数据可以隐式地学习先验和结构(例如,Google 使用数十亿的历史搜索来训练 RankBrain 进行搜索结果排序)。
NLP 技术很薄弱,在机器可以处理自然语言的开放域通信之前还有很长的路要走。但是在我们最终到达那里之前,现有的 NLP 技术如何帮助我们在商业领域中更进一步呢?
The power of aggregation
NLP 在许多应用中已经发挥着关键作用。但都使用了一个小伎俩。通常,在这些应用程序中,我们不依赖于 NLP 来理解自然语言中单个话语的含义。相反,我们使用 NLP 技术处理大型语料库,并汇总其结果以支持应用程序。
情感分析。特别是面向特定领域的情感分析,是评估企业和产品的有用工具。它对大量的用户评论语料进行信息提取,并向企业和产品输出综合情绪或意见。但是如果我们更深入地了解这项技术,我们会看到它的缺陷:我们有时无法衡量情绪,因为我们不了解自然语言的特定表达。例如,“the phone fits nicely in my pocket(这部手机与我的口袋很相称)”是对手机尺寸的积极情绪,但要自动将“fits nicely in my pocket”与“size”联系起来并不容易。
摘要。有两种类型的文本摘要:抽取和抽象。总结一篇文章,抽取的方法是在文章中选择几个句子,而抽象的方法则是产生新的句子。抽取的方法使用纯粹的统计方法,例如,它通过研究句子间的共享单词和主题来创建两个句子之间的联系。但这种方法一直无法产生好的结果,直到最近几年深度学习可以派上用场。但即便使用了深度学习(例如,最近的工作有使用 sequence to sequence translation, attention mechanism, copy mechanism, coverage mechanism 等),摘要的质量仍然达不到产品级别。那么,这项技术何时可以帮助我的朋友来阅读财经新闻并提供贸易建议呢?至少目前的方法需要多做些额外的工作,例如通过在摘要中考虑明确的目标(例如提供贸易建议)。
知识库。知识库构建是另一个依赖信息提取(IE)聚合结果的领域。它还展示了聚合的优势和弱点:为创建一个更完整的知识库而付出的努力并不是非常成功,因为
–i)通过聚合大语料库的信息抽取结果而获得大部分开放域的知识,通常已经被 Freebase 或其他人工库涵盖了。
–ii)从个人的话语中获得的知识通常是不可靠的。
尽管如此,特定领域的知识库依然可能会在商业领域发挥巨大作用。以两个重要行业为例:电子商务和医疗保健。在电子商务网站上,用户可以通过名称或功能搜索产品,但他们不支持诸如“how to fight insomnia(如何与失眠做斗争)”或“how to get rid of raccoons(如何摆脱浣熊)”等这样的查询,尽管他们有很多适用这类情况的产品出售。他们需要的是将任何名词短语或动词短语映射到产品列表的知识库。医疗保健领域也有类似的情况。我们需要一个能够连接症状、环境、治疗手段和药物的知识库。
搜索。许多人认为搜索问题已经解决。不是的。搜索依赖于搜集的用户行为数据,这意味着搜索主要在头查询时效果很好。但在网页搜索以外的情景中,即使是头查询目前效果也并不好。

考虑一下这个问题:在 Facebook 上搜索“travel in Arizona(在亚利桑那州旅行)”。我的一位朋友在我的查询前四个小时发了相关帖子,这本是一个完美的匹配。但是,在搜索时看到这篇文章是非常困难的,因为用户行为数据还没有导入它。
因此,对于社交搜索、电子邮件搜索、电子商务搜索、应用搜索等,NLP 和语义匹配仍然扮演着重要角色。具体而言,在只有有限甚至是没有用户行为数据的情况下,知识图、实体链接、语义分析技术可以更好地服务于搜索。
教育。一个非常有趣和有利可图的业务是帮助用户更有效地学习或使用一种语言。例如,几个初创公司(例如,Grammarly,DeepGrammar 等)提供工具来纠正用户的语法错误。在高层次上,这是相当可行的,因为算法应该能够通过大型语料库的离线学习获得足够的语法知识。这应该使他们能够捕捉文本中的大部分错误,而不必理解文本的含义。但是,还有很多需要改进的空间。例如,给出“I woke at 4 am in morning”的时候,Grammarly 或 DeepGrammar 都没有建议将“woke”改为“woke up”或者将“in morning”改为“in the morning”。DeepGrammar 实际上建议将“woke” 改为“work”,这当然是没有意义的。当然,识别某些错误需要语义知识,例如,这些工具何时能够建议在下面的文字中“I woke up at 4 pm in the morning”,将“pm”改为“am”?
A little technical breakthrough plus a lot of dirty work
我们喜欢想象漂亮的 NLP 解决方案,但其中很多都是通用人工智能(Artificial General Intelligence, AGI),因为他们需要处理所有可能的场景。通用人工智能不会很快出现。尽管如此,技术突破仍然时刻在发生。有时候,只需要人工额外做一点苦活,我们就可以将它们变成商业上的成功。
自动问答(QA)和聊天机器人现在已并不新鲜 — 第一个聊天机器人是在 60 年代开发的(ELIZA,1966),但它并没有走得太远。50 年过去了,是什么让 QA 和聊天机器人又变得如此火爆?发生了三件事:
1.(技术)语音识别的突破,使得 Alexa,Google Assistant,Siri 成为可能; 大型知识库的可用性,特别是开放领域的知识库,如 Google 的知识图谱。
2.(市场)信息已经成为商业和日常生活中不可或缺的元素,最近聪明的语音助手突然无处不在。
3.(实用性)人们已经准备好从关键字搜索切换到基于语音/自然语言的界面,以更直接的方式获得更具体的答案。但技术突破 – 语音识别和知识库 – 不会自动导致问答系统的产生。我们仍然需要理解问题,解释和推理问题,但在过去的 50 年中,这种能力并没有根本的改善。
尽管如此,QA 非常成功,我们都在 Google 上体验过。(它仍然犯了错误,下文中,谷歌将婆婆错认为是它创始人的母亲,截图产生于 2017 年 7 月)。只是成功不是来自于自然语言理解的新水平,相反,它是通过大量手工模板实现的。
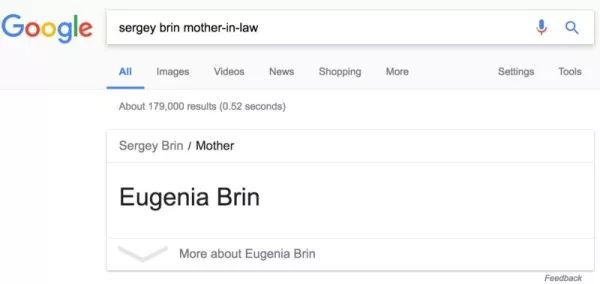
这里我们观察到一些现象。
1.技术的进步在很大程度上推动着产品的影响力。因此,我们知道技术的局限性至关重要:毕竟,半个多世纪以来,问答系统和聊天机器人并没有多少大事件发生。
2.通常新技术并不能解决 100%的问题,但没关系。我们很乐意去做一些苦活(例如,手工制作模板和写规则等)以弥补技术上的不足。在很大程度上,QA 和数字助理(如 Siri,Alexa,Google Assistant 和 Cortana)的成功是由手工模板驱动的。
但是最新的会话式 AI(例如,使用深度强化学习来构建聊天机器人)怎么样呢?它是使聊天机器人如此热的动力之一吗?是,但它尚未产生真正的影响。在这里,我专注于以目标为导向的对话系统(Siri,Alexa,Google Assistant),尽管我承认漫无目标的 smalltalk(Microsoft Tay) 可能会有趣。但我们应该不断研究技术进步和应用需求的交集,而不是回避使用低技术含量的苦活来实现目标。
Narrowing the problem domain
让我们重新审视我之前提到的朋友们的项目:
1.与病人交谈并进行医学诊断的聊天机器人。
2.一种读取财经新闻并提供贸易建议的算法。
3.个人助理,记录你的日常活动,并提供建议,让你更快乐,更充实。
必胜客部署了一个聊天机器人来处理客户的订单,这非常成功。Facebook 的虚拟助理 M 已经死了,因为 Facebook 没有对 M 能做或不能做的事施加限制。在讨论朋友项目的可行性之前,让我们重新回顾一下微软 AI 总裁 Harry Shum 的这句话:
今天的电脑可以很好地执行特定的任务,但是当涉及到一般任务时,AI 甚至还无法与人类孩子竞争。
– Harry Shum
斯坦福大学教授 Andrew Ng 的这句引述:
今天深度学习只能在一些可以获得大量数据的狭小的领域内发挥价值。下面是一个它不能做的事情的例子:进行一次有意义的对话。在相关的 demo 中,如果你精心挑选对话,那么看起来它像是一个有意义的对话。但如果你实际去使用一下那些产品,它们通常会很快不知所云。
– Andrew Ng
当谈到让机器人进行医学诊断时,人们自然会产生很多怀疑和担忧。但从技术上讲,这并非不可能。要解决狭窄领域的问题,首要任务就是开发特定领域的知识库,使我们的机器人成为领域的专家。
在这种情况下,我们需要模拟症状、病情、诊断、治疗、药物等之间关系的知识图表。无论如何,人们都会收到非医疗机构的健康建议:每 20 个谷歌搜索中就有一个与健康相关的信息搜索。聊天机器人仅提供比网络搜索更直接的通信形式。另一方面,这个项目的真正难点可能是如何访问用户的病历。事实上,一些初创公司(例如 doc.ai 和 eHealth First)已经投资使用区块链技术来解决这个问题。
阅读金融新闻并提供贸易前景的任务涉及一个更广泛的领域,因为股票价格受到无数因素的影响:自然因素、政治因素,科学因素,技术因素,心理因素等等。了解某些事件如何导致股票价格变动是困难的。但是,缩小这些领域并为他们开发专门的工具是可能的。
例如,我们可能并非监测广泛的股市,而是专注于商品期货。然后,我们再次开发知识库,其中可能包含如下规则:“如果像智利这样的国家出现政治动荡或自然灾害,铜的价格会上涨”。最后,我们可以开发算法来读取新闻和检测某些国家的政治动荡或自然灾害的事件。由于机器读新闻的速度远比人类快,它们提供的信息可能转化为算法交易的优势。
创建个人助理是一个非常有趣的想法,个人助理可以记录用户的日常思考和活动,并提供反馈,让用户更快乐,更满意。这让我想起 Google Photos。Google 会不时挑选一些旧照片来创建一个标题,例如“Rediscover this day 4 years ago(重新发现 4 年前的今天)”这样的标题。它从来都可以让我笑容满面。尽管如此,照片只能捕捉人们一生的一瞬间,而自然语言有可能以更全面的方式保存我们的想法和活动,并以更有创意的方式回放给用户。
然而,这是一个开放的领域任务:个人助理需要了解各种思想和活动,这使得它成为通用人工智能(AGI)。是否有可能缩小问题域?
我们为什么不从 1000 个模板开始?1000 个模板将涵盖令人惊讶的许多人类活动(例如,“我今天在斯坦福大学校园跑步 3 英里”和“我在帕洛阿尔托市中心的哈纳斯与阿隆喝咖啡”等),这是相当合理的。私人助理会将我们生活中的片段转化为结构化的表示,对它们进行分类,聚合,然后以一种新的形式将它们呈现给我们。
尽管如此,还有一些私人助理无法理解的东西。例如,“我的岳父昨天去世了。我的妻子和我整晚都拥抱在一起聊天。“它可能不适合我们手工制作的 1000 个日常生活类模板中的任何一个。尽管如此,私人助理不应该错过这个人一生中的重要事件。
私人助理可以做几件事情。首先,使用预先训练的分类器,它可以将事件分类并归档为失去亲人。其次,它可以使用语义分析或槽填充机制来进一步检测谁去世。第三,当上述工作都不奏效时,它仍然可能将其记录为原始文本,并等待未来的先进技术去解决它。
Pushing technical boundaries
现有的 NLP 技术不足以理解自然语言; 通用人工智能没有实现,至少不会很快实现。这是否意味着产生商业影响的唯一途径是通过缩小问题范围来达到我们可以使用劳动密集型技术来涵盖所有情况的程度?当然不是。
推动技术边界的方法有很多种。在这里,我将讨论我们正在研究的两个方向。
如果现在的自然语言处理技术不允许我们深入理解自然语言,那么是不是可以试着扩展它?
作为一个例子,让我们考虑 QA 和 chatbots 的客户服务。客户服务是 NLP 和 AI 发展的前沿。它不需要我们特别深入地理解自然语言。如果我们的技术能够处理 30%的客户互动,企业就可以节省 30%的人力,这非常重要。因此,许多公司正在部署自己的 QA 或聊天机器人的解决方案,并且已经取得不同程度的成功。
曾经有一段时间(20 世纪 70 年代以前),每个企业都需要以自己的方式管理某种数据存储(例如,保留工资记录)。然后是关系数据库管理系统,它宣称无论您运行什么业务,关系数据库管理系统都可以以声明的方式为您处理工资单和其他应用程序,这意味着无需编写代码以进行数据操作和检索。
是否有可能为客户服务建立一个通用的会话式 AI?换句话说,为一个企业设计的客户服务系统用于不同的业务需要做些什么?
这可能听起来很牵强,但并非完全不可能。首先,我们需要统一用于客户服务的后端数据模型。这是可行的,因为大多数业务数据已经在关系数据库中。其次,我们将客户的自然语言问题转换为针对底层数据库的 SQL 查询。
这是否意味着我们需要处理所有情况下的自然语言问题?不是的。我们只处理一小部分自然语言,也就是说,那些可以转换为 SQL 语句的部分。在这种约束下,一个业务领域中的自然语言问题必须与不同业务领域中的自然语言问题类似,因为他们共享相同的潜在结构。事实上,如果我们将 i)数据库模式,ii)数据库统计数据,以及 iii)在自然语言中提及数据库属性和值的等效方法作为可注入 QA 和会话 AI 的元数据,则可以创建一个系统满足不同的客户服务需求。
如果缺乏训练数据是 NLP 的瓶颈,那么为什么不努力将明确的领域知识注入机器学习算法?
这并不是什么新鲜事,但问题是实际存在的。机器学习将大量训练数据中的统计相关数据转化为隐式知识。但有时候,这些知识可以用明确的方式注入机器学习中。
举个例子,假设一个知识库有一个父母关系,但不是祖父母关系。学习 grandparentOf 等同于 parentOf(parentOf)需要大量的训练数据。更有效的方法是将该领域知识作为规则传递给机器学习算法。
在我们上面描述的客户服务项目中,我们使用深度学习(基于 seq2seq 的模型)将自然语言问题转换为 SQL 语句。从训练数据中,算法学习自然语言问题的含义以及 SQL 的语法。尽管如此,即使拥有非常大的训练数据,学习模型并不总是生成格式良好的 SQL 语句,但是模型不应该需要学习 SQL 的语法!
原文标题:Getting NLP Ready for Business,作者:Haixun Wang
文章来源:51CTO

媒体合作请联系:
邮箱:contact@dataunion.org




