新算法可以优化三维重建,极大推动AR中的对象跟踪速度

该算法在数据分析方面大大优化,助力AR、VR等相关领域的发展。
近日,伯克利的AI研究人员发布新的算法,该算法根据物体的单幅二维图像信息,就可以快速地将其三维结构构造出来。

虽然对于人类而言,根据物体的单面信息推测出东西的整体形状很容易做到,但是对于机器而言,这一过程十分艰难,因为增加一个维度意味着要增加大量的数据。
具体来看,当你拍一张照片,每一边的像素点数是100,那这张图像的像素点数一共就是一万个。但是如果你想增加一个维度,也就是增加一边,假设增加的新边像素点数仍然是100,那整体像素点数将增加一百倍。如果稍微追求精度,单边像素选用128,整体像素点将增加两百倍。不言而喻,数据量的增加是成数量级的。
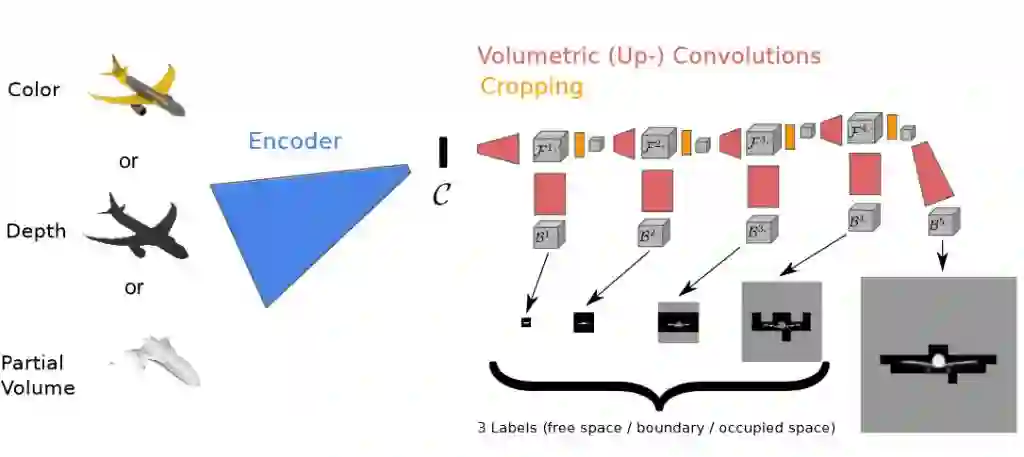
同时为了确保不失真,图像的每一个像素点及像素点之间的关系都要计算分析,如果想要高精度,那计算量就将十分巨大。
对此很多研究人员都以提升硬件处理速度来弥补算法运行数据量巨大这一不足,但运行速度依然十分之慢,不过伯克利人工智能实验室的Christian Häne却指出,事实上,我们不是在计算和重建100x100x100的整体,而只是描述一个对象的表面,至于表面以外或以内的空间,我们都可以不用管。
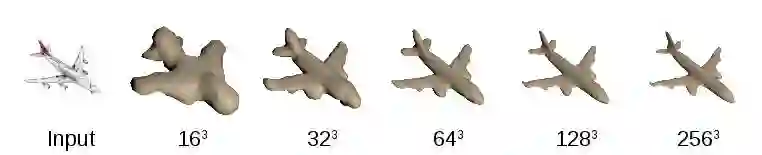
所以,首先他以很低的分辨率对2D图像进行3D重建,接着抛去表面以外的数据部分,对保留的区域进行更高分辨率的渲染,以此循环重复,从而以较高速率和精度实现了对物体3D空间的重构。
笔者认为,这一定不是最佳解决方案,但是Christian Häne对数据的筛选方法上的改进是对算法本身很好的一次优化,提升了计算机处理的速度和精度,有助于AR和VR中更迅速和精准的对象跟踪。
/- 推荐阅读 -/




 微信ID:im2maker
微信ID:im2maker
 长按识别二维码关注
长按识别二维码关注
硬科技第一产业媒体
提供最有价值的行业观察
登录查看更多
相关内容

在计算机视觉中, 三维重建是指根据单视图或者多视图的图像重建三维信息的过程. 由于单视频的信息不完全,因此三维重建需要利用经验知识. 而多视图的三维重建(类似人的双目定位)相对比较容易, 其方法是先对摄像机进行标定, 即计算出摄像机的图象坐标系与世界坐标系的关系.然后利用多个二维图象中的信息重建出三维信息。
物体三维重建是计算机辅助几何设计(CAGD)、计算机图形学(CG)、计算机动画、计算机视觉、医学图像处理、科学计算和虚拟现实、数字媒体创作等领域的共性科学问题和核心技术。在计算机内生成物体三维表示主要有两类方法。一类是使用几何建模软件通过人机交互生成人为控制下的物体三维几何模型,另一类是通过一定的手段获取真实物体的几何形状。前者实现技术已经十分成熟,现有若干软件支持,比如:3DMAX、Maya、AutoCAD、UG等等,它们一般使用具有数学表达式的曲线曲面表示几何形状。后者一般称为三维重建过程,三维重建是指利用二维投影恢复物体三维信息(形状等)的数学过程和计算机技术,包括数据获取、预处理、点云拼接和特征分析等步骤。





相关VIP内容
相关资讯
相关论文