Hinton AAAI2020 演讲:这次终于把胶囊网络做对了

作者 | 杨晓凡
责编 | 贾伟
AI 科技评论按:2020 年 2 月 9 日,AAAI 2020 的主会议厅讲台上迎来了三位重量级嘉宾,这三位也是我们熟悉、拥戴的深度学习时代的开拓者:Geoffrey Hinton,Yann LeCun,Yoshua Bengio。
其实仅仅在几年以前,我们都很少在计算机科学界的学术会议上看到他们的身影,Hinton 甚至表示自己都很久不参与 AAAI 会议了 —— 毕竟十年前的时候神经网络还被主流的计算机科学研究人员们集体抗拒,即便有进展,论文也不会被各个学术会议接收。如今,随着深度学习成为机器学习科研的绝对主流和面向大众的人工智能技术中的核心技术,2018 年的图灵奖终于授予这三人,也就是对他们的贡献的(迟来的)认可。
在这天的两小时的特别活动中,三位各自进行三十分钟演讲,最后还有三十分钟的圆桌讨论,圆桌讨论中也会回答在座观众提出的问题。
Hinton 第一个进行演讲,按惯例,在演讲嘉宾登台之前要做简单的介绍。AAAI 2020 两位程序主席之一的 Vincent Conitzer 说道:「我们都知道,发生在这三位身上的是一个饱含天赋和坚持的故事。如今我们也许很难想象,但当时神经网络这个研究方向简直不能更冷门了,Jeff、Yann、Yoshua 三个人就是在这种时候做出了许多关键的成果。他们的故事鼓励我们要追寻自己认定的学术方向,而不是一股脑拥到最热的话题上去」。
Vincent 还讲了一则 Hinton 的趣事,这还是 Hinton 自己讲给别人的。我们都知道 Hinton 一直在琢磨人脑是怎么运转的,有一天 Hinton 告诉自己的女儿「我知道大脑是怎么运转的了」,她的反应却是:「爸爸你怎么又说这个」;而且这种事甚至每隔几年就会发生一次。
观众发出笑声,接着 Geoffrey Hinton 在掌声中走上演讲台。AI 科技评论把他的演讲全文整理如下。

今天我要讲的是近期和 Adam、Sara、Yee-Whye 一起完成的一些研究。今天我不打算讲哲学话题,也不会解释我为什么很久都不参加 AAAI 会议之类的(观众笑),我就给大家讲讲这项研究。
依旧从批评 CNN 开始

对象识别这个任务主要有两大类方法,一类是老式的基于部件的模型,它们会使用模块化、可感知的表征,但通常也需要很多的人工特征工程,所以它们通常也不具备学习得到的部件的层次结构。另一类方法就是卷积神经网络,它们完全是通过端到端学习得到的。对象识别中有一个基础规律,如果一个特征检测器在图像中的这个位置有效,那么在另一个位置也是有效的(译注:平移不变性),CNN 就具备这个性质,所以可以组合不同的信号、很好地泛化到不同的位置,有不错的表现。
但 CNN 和人类的感知有很大的区别。我今天演讲的第一部分可以算是都在针对 Yann LeCun 了,我要指出 CNN 的问题,告诉你们为什么 CNN 是垃圾。(观众笑)

CNN 的设计可以处理平移,但是对其他类型的视角变换处理得很不好,比如对于旋转和缩放 —— 不过比我们一般认为的还是要好一点。一种处理方式是把二维特征 map 换成四维或者六维的,但是计算成本增加得太多了。所以,训练 CNN 的时候要使用各种不同的视角,来让模型学习如何泛化到不同的视角上;这种做法很低效。理想的神经网络应当不需要花什么额外的功夫,可以自然而然地泛化到新的视角上 —— 学会识别某种物体以后,可以把它放大十倍,再旋转 60 度,仍然能够识别,这样才是合适的。我们知道计算机图形学就是这样的,我们也希望能设计出更接近这样的神经网络。

下面我先解释一下 equivalence(等价)和 invariance(不变)。典型的 CNN,尤其是带有池化的网络,它得到的表征是不随着视角的变化而变化的,是「invariance 不变」,和得到「equivalence 等价」的表征是两码事。「equivalence 等价」的意思是说,随着视角变化,表征也跟着变化。我相信的是,在人类的感知系统中,当你的视角变化的时候,神经活动的模式也会跟着变化;我不是说识别得到的标签要变化,显然标签是需要保持不变的,但你的感知活动的表征可能会发生很大的变化。不随着视角变化而变化的,是连接权重,而权重编码了不同的东西之间的关系。这个我待会儿还会说到。

CNN 也不能解析图像。当你让 CNN 识别一张图像的时候,它不会做任何的显式解析,不会尝试分辨什么是什么的一部分、什么不是什么的一部分。我们可以这么理解 CNN,它关注的是各种各样的像素位置,根据越来越多的环境信息对每个像素位置上存在的东西建立越来越丰富的描述;最后,当你的描述非常丰富了,你就知道图像中有什么东西了。但 CNN 并不会显式地解析图像。

CNN 识别物体的方式也显然和人类很不一样,在一张图像里增加一点点噪声,CNN 就会把它识别成完全不同的东西;但我们人类几乎看不出图像有什么变化。这种现象是非常奇怪的。在我看来这是一个证据,证明了 CNN 识别图像的时候使用的信息和我们人类完全不同。这不代表 CNN 就做错了,只不过是确实和人类的做法有很大区别。

我对 CNN 还有一点不满是,它会计算下方的层的点积、再乘上权重,用来决定是否激活。这是一个找到线索的过程,然后把线索叠加起来;叠加的线索足够多了,就激活了。这是一种寻找巧合的激活方式,它比较特殊。巧合其实是非常重要的,就像物理学很大程度上研究的就是两个不同的物理量之间的巧合;巧合可以构成一个等式的两端,可以构成理论和实验。在高维空间里如果发生巧合了,这是非常显著的,比如你在收音机里听到了「2 月 9 日,纽约」,然后在别的信息里又看到了几次「2 月 9 日,纽约」,全都是 2 月 9 日和纽约的话,你会觉得很震惊,这就是高维空间里的巧合,非常显著。
那么,目前我们使用的这种神经元是不会寻找巧合的;不过情况也在变化,我们也开始使用 Transformer 模型,而 Transformer 是会寻找巧合的;等一下我也会解释这个。计算两个活动向量的点积,这要比原来的做法强多了;这就是计算这两个活动向量是否匹配,如果是,那就激活。Transformer 就是这么工作的,这带来了更好的过滤器。这也带来了对协方差结构和图像有更好响应的模型。这里真正重要的就是协方差结构,像素的协方差结构。

最后一点,也是 CNN 最严重的问题是,CNN 不使用坐标系。当我们人类观察东西的时候,只要看到一个形状,我们就会给它假定一个坐标系。这是人类感知的一个基本特点。我会举例子尝试说服你接受这件事;不过我的时间不是很多,我会试着很快地举例子说服你。

因为没有时间看那些很漂亮的 demo,我们就看看这两个形状。左边这个像是某个国家的地图,有点像澳大利亚;但是如果我告诉你这个形状不是正的,是斜的,它看起来就像非洲。一旦你看出来它像非洲了,它就和一开始感觉的那个仿佛镜像过的澳大利亚完全不一样。但我们不是第一眼就能看出来它像非洲的,如果告诉你它是某个国家,那你就只会把它看作某个国家。
再看右边这个形状,它要么是个很正的菱形,要么是个正方形转了 45 度;基于你觉得它像什么,你对它的感知也会完全不同。如果你把它看作菱形,那么只要左侧和右侧的两个角的高低有一点点区别你都能注意到,但你就注意不到这四个角是不是直角,你的观察根本不会在意这里。也就是说,如果如果我把它上下拉长一点,让里面的四个角不是直角了,它在你看来仍然是一个很正的菱形。
但反过来,如果你把它看作一个正方形转了 45 度,你就会注意到这四个角都是直角;即便只是从 90 度变成 88 度,你都能看得出来不再是直角了;但同时,你也就不再会在意左侧右侧的两个角的高低是否一样。
所以,根据你选取的坐标系不同,你内心的感知会完全不同。CNN 的设计就没法解释这个现象,对于每个输入只有一种感知,而且这个感知也不取决于坐标系的选取。我觉得这和对抗性样本有一些联系,也就是 CNN 和人类的感知方式有很大不同。

我觉得做计算机视觉的一个很好的方法是把它看作计算机图形学的反向,这种想法可以回溯到很久很久以前。计算机图形程序中会使用层次化的模型,它们对空间结构建模,用矩阵来表示内嵌在整体内的坐标系和每个部分自己的坐标系之间的转换关系。
对于整个物体,它有一个自己的、内嵌的坐标系,我们也可以指定一个;然后整体的每个部件也有各自的坐标系。在坐标系全都选定了之后,就可以确定部件和整体之间的关系,这就是一个简单的矩阵运算;对于刚体,这就是一个线性关系。
所以这是一个很简单的线性结构,计算机图形学中用的就是这样的思路。对于做计算机图形学的人,你要是请他把东西换个角度展示给你看,他们就不会说「我其实是很乐意的,但我们没从别的角度训练过,所以最多只能转 15 度」这样的话,他们可以直接转到你要的随便什么角度,因为他们有真正的三维模型,他们会对空间结构建模、对部件和整体之间的关系建模。这些关系也完全不受视角的影响。
我觉得,如果处理三维物体的图像的时候不使用这种美妙的结构才是真的有问题。一个原因是,如果要做长距离的外推,线性模型是可以很方便地做外推的;次数更高的模型很难外推。而且我们也一直在寻找线性的隐含流形,在计算机视觉里我们知道它们是什么;视角变换对图像有很大的影响,这其中其实就有一个隐含的线性结构,而我们并没能利用这个结构。
2019 年版的最新的胶囊网络

现在我要具体介绍一个系统,它的名字叫做 Stacked Capsule Auto-Encoders。有的人可能已经读过一些胶囊网络相关的东西,这里我得说明,这是另外一种版本的胶囊。每一年我都会设计出一种完全不同的胶囊网络,NeurIPS 2017 的那篇是关于路由的,ICLR 2018 的那篇使用了 EM 算法,然后在 NeurIPS 2019 还有一篇新的,就是我现在要介绍的这个。
所以,首先要把之前的那些版本的胶囊网络的一切都忘了,它们都是错的,只有现在这个是对的(观众笑)。之前的那些版本用了判别式学习,我当时就知道这个做法不好,我一直就觉得无监督学习才是对的,所以之前的那些版本都走错了方向;而且它们都使用了「部件-整体」关系,效果也不好。用「整体-部件」关系要好很多。用「部件-整体」关系的时候,如果部件的自由度比整体的自由度要少,好比部件是点,然后你要用点组成星座,那你很难从一个点的位置预测整个星座的位置,你需要用到很多点的位置;所以不能从单个部件出发对整体做预测。
在这个新的版本中,我们用的是无监督学习,以及用「整体-部件」关系。

「胶囊」的出发点是,在神经网络中建立更多的结构,然后希望这些新增的结构可以帮助模型更好的泛化。它也受到了 CNN 的启发,在 CNN 里 Yann 只设计了很少、很简单的一些结构,就是让特征检测器可以在不同的平移变换之间复制,这个改进产生了巨大的好处。那么我的下一个问题就是,我们能不能沿着这个方向继续往前走,能不能设计一些更加模块化的结构,这样就可以做解析树之类的。

那么,胶囊会表征某个东西是否存在,它会学习它应该表征什么实体,也会有一些这个实体的参数。在 2019 年的胶囊,也就是这个最终的、正确的胶囊里,它会有一个逻辑单元,就是最左侧的浅蓝色的东西,它用来表示当前的图像中是否存在这个实体,不管实体是在这个胶囊覆盖的图像范围的任何地方。也就是说胶囊自己可以是卷积的。
胶囊里会有一个矩阵,右边红色的,用来表示这个胶囊表示的实体和观察者之间的空间关系,或者是这个实体内嵌的固有坐标系和观察者之间的空间关系;这样就知道了它朝什么方向、多大、在哪里,等等。还有一个包含了其它属性的向量,里面会包含变形之类的东西;如果要处理视频,也会包含速度、颜色等等信息。

我再重复一下重点:胶囊是用来捕捉固有几何特性的。所以,一个表示了某个物体的胶囊可以根据自己的姿态预测出它的部件的姿态,而且,物体自己和物体的部件之间的关系不会随着视角的变化而变化。这才是我们要以权重的方式存储在神经网络里的,这才是值得存储的知识,然后也就可以用这些不依赖视角的知识做对象识别。
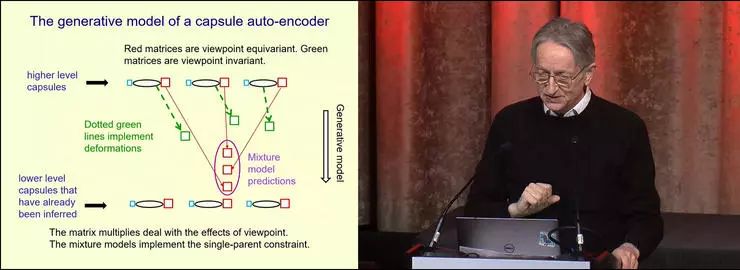
集中注意力,理解了这页 PPT,你就理解了这个新的胶囊。这里的思路是,我们有某种自动编码器,一开始先用贪婪的方法训练它 —— 从像素得到部件,从部件得到更大的部件,从更大的部件得到再大的部件。这个训练过程是贪婪的,就是一旦从像素得到部件了,就不会逆过来重新选取像素和部件,而是就直接使用已经得到的结果,然后往更高的一层进发,尝试把这些部件拼成更熟悉的整体。
这张 PPT 里展示的就是一个两层的自动编码器中的解码器,但其中的单元已经不是传统的那种神经元了,是更复杂的胶囊。下面这一层中是一些我们已经从图像中收集信息得到的胶囊 —— 这算是一种归纳法的解释 —— 我们已经得到了一些低层次的胶囊,已经知道了它们是否存在、它们的向量属性是什么、姿态是什么、和观察者之间的关系,现在要在它们的基础上学习更高一层的胶囊。我们希望每个更高层次的胶囊可以解释好几个低层的胶囊,也就是一个整体胶囊对应多个部件胶囊,就有了一个学习过程。
在这样的生成式模型中,我们不直接生成低层次的数据,我们根据高层次的胶囊生成「低级别的数据可能是什么」的预测。首先我们要做的是找到颊囊中的参数向量,然后这里的绿色虚线表示,通过这个实体中提取到的这些参数,分别为每个部件预测整体和部件之间的空间关系。
如果是一个刚体,那就不需要这些绿色虚线,对应的矩阵就是常数;如果是可变的物体,就需要这些绿色虚线。对于每一个高层次的胶囊 —— 等会儿我会解释它们是怎么实例化的 —— 每一个已经实例化的高层次胶囊都会为每个已经从图像中提取到的低层次的胶囊预测姿态。这里被椭圆圈出来的三个红色方块就是三个高层次的胶囊分别对某个低层次的胶囊的姿态作出的预测。
这里我们感兴趣的是,高层次的胶囊中应该应该有一个是有解释能力的。所以这里会使用一个混合模型。使用混合模型有一个隐含的假设是,其中有一个是正确的解释,但一般来说你不知道哪一个是正确的。
我们选择的目标函数是,让高层次胶囊通过混合模型产生的、已经在低层次胶囊上观察到的姿态的对数似然最大化。在这个混合模型下,对数似然是可以计算的。这些结构的训练方式是反向传播,学习如何让高层次的胶囊实例化。
当通过混合模型做反向传播的时候,其中并不能很好地解释数据的元素的后验概率几乎为 0。那么当计算反向传播的时候,反向传播并不会改动它们,因为它们没有什么作用;那些提供了最好的解释的元素得到最大的导数,就可以学习、优化。
这就是这个生成式模型的设计。需要说明的是,生成式模型里有两种思想。首先,每个低层次的胶囊只会被一个高层次胶囊解释 —— 这就形成了一个解析树,在解析树里每个元素只有一个父项。其次,低层次的胶囊的姿态可以从高层次胶囊推导得到,就是通过高层次胶囊相对于观察者的位姿和整体相对于部件的位姿做矩阵相乘,就得到了低层次胶囊相对于观察者的位姿。视觉里非常重要的两件事,处理视角变化,以及建立解析树,就这样设计到了模型里面。

现在我还没展示如何做编码器,也就是感知的部分。这是一个很难的推理问题,在之前版本的胶囊里,我们对编码器做了一些人工工程,要对高层次的胶囊投票、看投票的结果是否一致,这种方式特别难搞,很难做对。Sarah 花了很多时间精力研究这里,她虽然让它运行起来了,但还是非常困难。
很幸运的是,当我们做这些尝试的时候,Transformer 出现了。Transformer 本来是用来处理语言的,但它的设计非常巧妙。那么我们面对的状况是,我们有一些部件,想从部件推理出整体,这是一个很难处理的推理问题。但有了 Transformer,我们就可以试试直接把所有部件都输入到 Transformer 里,让它们自己去碰吧。
我们就使用了一个多层 Transformer 模型,最终把一个简单的生成模型和一个复杂的编码模型配合使用。这个多层 Transformer 模型会决定如何处理一致性、如何组织不同的部件,我们只需要想办法训练它就行。
要训练 Transformer,一般来说我们需要有正确答案。但这儿实际上可以不需要正确答案,只需要训练它的导数,就是看它给出的答案,然后让它给出一个比现在更好的答案。这是从生成模型得到的。

做法是,把所有已经提取到的胶囊都找出来,把它们输入到多层 Transformer 套模型(Set Transformer)里,这个套模型会给每个低层次胶囊取向量描述,然后随着在模型里逐层上升,把其他胶囊的信息作为背景环境不断更新这个向量描述。当这些部件的描述更新得足够好了以后,就在最后一层里把它们转换成预测,预测整体物体应该在哪里。

这个多层 Transformer 套模型很好训练,因为我们有一个对应的生成式模型,生成式模型可以把导数提供给 Transformer。训练 Transformer 模型的目标也和训练生成式模型一样,都是在给定高层次胶囊预测的位姿的条件下让实际观察到的部件位姿的对数似然最大化。我们也在里面设计了一个稀疏的树结构,鼓励它每次只激活少数几个高层次胶囊。

对于这个多层 Transformer 套模型,感兴趣的人可以去读这篇论文,我就不介绍更多细节了。
我相信你们中有很多人都知道 Transformer 是怎么运行的,而且我的时间也不多了,我会很快很快地讲一下 Transformer 是怎么运行的。
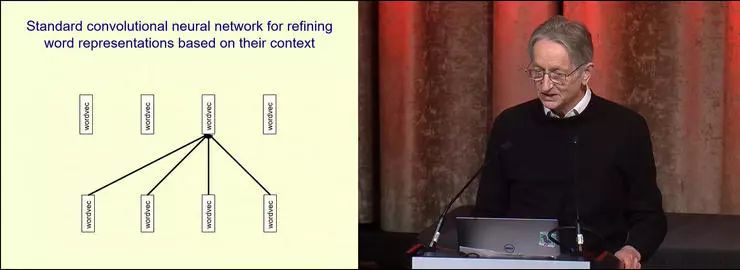
这是处理句子的情况对吧,它处理句子的方式是先得到一批词向量,然后在上面运行卷积网络,让每个词向量都可以依据它附近的向量进行更新。这整个设计都可以用无监督学习的方式训练,训练目标是重建其中被拿走的词向量。

这相当于是用卷积的的方式来设计自动编码器,并且 Transformer 中还有一些更精细的人工设计:除了让词向量直接影响同一层和更高层的词向量之外,每个词向量还会生成一个 key、一个 query 和一个 value。根据我这页 PPT 展示的 Transformer 的状态,词向量会查看自己的 query,这是一个学习得到的向量,然后把它和临近的词向量的 key 做对比。如果匹配了,它就会把临近的词向量的一部分 value 作为自己的新的 value。这个过程就是不断地寻找相似的东西,然后把它们组合起来得到新的表征。Transformer 的运行方式基本就是这样。
下面我给大家看看用一个 Transformer 组合模型和一个带有坐标系、解析树的简单生成式模型配合起来,在简单的数据集上的运行结果。

大家不要笑,这些是 MNIST 数字样本,是 1980 年代的东西了。我取了一些有难度的样本,模棱两可的那种。我要用设计的模型处理这些,验证想法对不对。对这些 MNIST 数据的建模方式是,先有一层部件层,可能是一部分笔画;然后有一个整体层,高层次的胶囊,可能是整个数字,不过不是完全和数字对应的。

每个部件是学习得到的小的 11x11 大小的模版,这里我不会详细解释部件是怎么学习到的,因为和整个数字的学习方式基本一样,所以我主要讲讲整个数字是怎么学的。这里的核心是,用来自各种不同部件的预测形成的套模型对像素密度建模,其中的每个部件可以是带有仿形变换的,也就是说它的姿态矩阵允许它有不同的实例化结果。

这儿有几个数字,比如我们看那个「4」。其中红色的部分是从图像中提取部件,然后重新构建出像素得到的;绿色的部分是从图像中提取部件、激活更高级别的胶囊,然后再重构低级别的胶囊、重构像素得到的,也就是从高级别一步步生成的。红色和绿色重叠的部分是黄色。可以看到,大部分都是黄色的,红色、绿色都只有一小部分边缘,也就是说两种方法重构出的结果区别很小。
右边显示的是 24 个高级别胶囊的激活情况。这些高级别胶囊学习的是整个数字之类的内容,也可以是更大的,并不和数字完全对应。
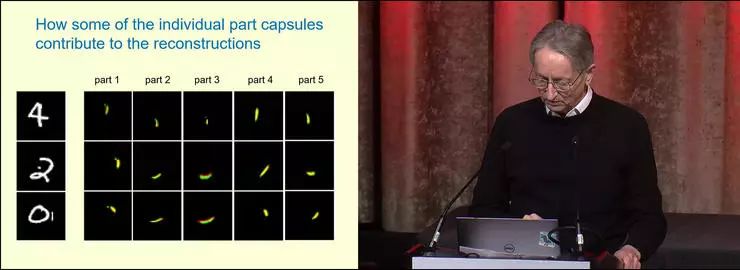
现在我们看看部件是如何组成整个数字的。数字 4 的第四、五个格子,也就是 4、5 部分,是同一个部分,但是进行了不同的仿射变换。那么,随着仿射变换的不同,它实例化的结果也会非常不同;这样,同一个部件就可以起到不同的用途。
接下来我要展示的是,在学会了如何提取部件之后,要学习整体,来解释这些部件的组合。然后把那 24 个高层次胶囊的激活模式组成的向量拿出来,用 t-SNE 作图,也就是把这些高维向量嵌入到二维空间,两个向量越相似,他们的距离就越小。在看图之前我要说明,这些胶囊从来没有学习过标签,完全是无监督学习得到的,然后得到的结果是:

它分出了 10 类,这 10 个类之间有明显的区分,而且也有一些误分类的。现在我要是给它们加上标签,就从每一类里面取一个样本,把它的标签作为它所在的类的标签,就可以直接得到 98.7% 的 MNIST 准确率 —— 你可以说这是没有使用任何标签的学习结果,也可以说使用了 10 个标签。
总的来说,用这个允许部件带有坐标系的生成式模型学习 MNIST,然后 MNIST 中的自然分类也就自然而然地出现了。实际上 MNIST 中的数字是有变形的,整个数字和它的部件之间的关系不是固定的,是取决于具体的每个数字的。这种做法是有效的。

不过这种做法也有两个问题。第一个问题是,我们人类的视觉并不是直接拿到一整张图像然后处理它,而是有一个很小的中央凹,然后要选择用它来看什么。 所以我们看东西其实是一个采样的过程,我们看到的东西并不都是高分辨率的。
另一方面,人类的视觉也依赖于观察点。我一直坚信我们看到的形状的同时也看到了一些背景环境。所以会有各种的视觉错觉,可能是一个花瓶,也可能是两张脸。所以如果从心理学角度看,视觉是在某个背景下观察某个图形的话,这个胶囊模型也就是对图形的感知的建模,而不是对背景的感知的建模;想要对背景建模的话,就需要材质建模之类的东西,而且也不需要把整个物体解析成不同的部件。一个变分自编码器就可以很好地完成任务。
所以,如果要解释有纹理的背景下的 MNIST 的数字的话,Sarah 训练了层叠胶囊自编码器+变分自编码器的组合,效果要比只使用变分自编码器对背景建模好多了。虽然它的表现还是比不上完全没有背景的情况,但我觉得如果想要解决有背景的问题,这就是正确的理论。就像人一样,在有背景的时候,我们就把背景只看作背景,不用高层次的、基于部件的模型对背景建模,因为这些模型是留给形状建模用的。

另一个问题是,刚才讨论这些都是二维的情况,而我们真正需要处理的是三维的图像。Sarah 之前设计的一个版本的胶囊网络在 Yann 设计的三维图像数据上做了尝试,试试看是否能够不借助等高线,直接处理真正的三维图形。
想要按这个思路做出来的话,我们需要让前端的、也就是最基础的胶囊表示物体的可感知的部件。把视觉看作计算机图形的反向工程的话,图形里先建立整个物体,然后部件、部件的部件、部件的部件,一直到三角形,最终进行渲染。所以用反向工程的思路处理,就只让最底层的胶囊处理光线的属性、反射率之类的东西,而高层次的胶囊负责的就是几何形状。我在这里谈到的也主要关注的是处理几何形状的层次。
现在我们在研究的就是反向渲染,从像素提取到可感知的部件。我们设计了很多不同的方法,可以用表面 mesh,也可以参考已知的几何形状,或者用半空间截面,等等,有很多方法。

最后的结论:
对于坐标系变换和解析树的先验知识可以很容易地集成到一个简单的生成式模型中。把知识放在一个生成式模型中有个有趣的好处,就是你的认知模型、你的编码器的复杂度不会干扰到生成式模型的复杂度。你可以把编码器做得特别特别复杂,但描述长度最短可以有多短,是由你的生成式模型的复杂度决定的。
所以,设计一个带有一定结构的生成式模型,然后把反向(识别)的流程丢给那个很大的套 Transformer。如果你的套 Transformer 模型足够大、有足够多的层、在足够多的数据上训练,得到好的表现可以说是十拿九稳了。

(演讲结束)
Hinton 苦思冥想、反复念叨这么多年的胶囊网络终于有了一个不错的答案,演讲结束时老爷子脸上也露出了欣慰的笑容。
接下来 AI 科技评论还会整理三驾马车的圆桌讨论内容,敬请期待。更多 AAAI 2020 的会议内容报告欢迎继续关注我们。






