变分推断(Variational Inference)最新进展简述

动机
变分推断(Variational Inference, VI)是贝叶斯近似推断方法中的一大类方法,将后验推断问题巧妙地转化为优化问题进行求解,相比另一大类方法马尔可夫链蒙特卡洛方法(Markov Chain Monte Carlo, MCMC),VI 具有更好的收敛性和可扩展性(scalability),更适合求解大规模近似推断问题。
当前机器学习两大热门研究方向:深度隐变量模型(Deep Latent Variable Model, DLVM)和深度神经网络模型的预测不确定性(Predictive Uncertainty)的计算求解都依赖于 VI,尤其是 Scalable VI。
其中,DLVM 的一个典型代表是变分自编码器(Variational Autoencoder, VAE),是一种主流的深度生成模型,广泛应用于图像、语音甚至是文本的生成任务上;而预测不确定性的典型代表是贝叶斯神经网络(Bayesian Neural Network, BNN)。
当前 DNN 的一大缺陷是预测“过于自信”,“不知道自己不知道什么”,对于安全性要求很高的任务来说,难以胜任,而 BNN 不仅给出预测值,而且给出预测的不确定性,从而使得模型“知道自己不知道什么”,BNN 广泛应用于探索与利用(Exploration & Exploitation, EE)问题(比如:主动学习、贝叶斯优化、Bandit 问题)和分布外样本检测问题(比如:异常检测、对抗样本检测)等。
本文以最经典的 VI 方法 Mean Field VI (MFVI) 为基础,从以下几个角度依次简述 VI 方法的最新进展:
如何更好地度量变分后验分布和真实后验分布之间的差异?
如何使用更复杂的先验分布来描述参数信息?
如何使用更复杂的后验分布簇来降低 VI 方法的 bias?
如何通过随机梯度估计方法来提升 VI 方法的 scalability?
问题定义
考虑一个一般性的问题, x 是 n 维的观测变量,z 是 m 维的隐变量,贝叶斯模型中需要计算后验分布,如下:

其中,p(z) 是先验分布,p(x|z) 是似然函数, p(x)=∫p(z)p(x|z),称为 evidence,通常 p(x) 是一个不可积的多重积分,导致后验分布 p(z|x) 无法获得解析解,同时因为 p(x) 只与确定的观测变量有关,在计算时可认为是一个常数。
VI 假设后验分布用一个变分分布 q(z;θ) 来近似,通过构造如下优化问题:

来求解使得两个分布距离最小的变分分布参数 θ,从而得到近似后验分布。
因为真实后验分布是未知的,直接优化公式(2)是一件比较有挑战的事情,VI 巧妙地将其转化为优化 ELBO 的问题。推导过程如下:

等号两边移动一下可得:

由 KL Divergence 的定义可知, KL(q(z;θ)||p(z|x;ф))≥0,同时 logp(x;ф) 是个常数,所以求优化问题(2)等价于求如下优化问题:

这里的目标函数 ELBO 称为 Evidence Lower BOund (ELBO),继续推导如下:

ELBO 的形式推导可由 Jensen 不等式直接推导出,如下:

公式(6)和公式(7)是一致的,所以求变分后验分布与真实后验分布 KL Divergence 的最小化等价于求 ELBO 的最大化,而 ELBO 的具体形式如(6)(7)所示,进一步整理可得:

其中第一项可以理解为基于变分后验分布的重建似然函数,第二项是变分后验分布与先验分布的 KL Divergence。
ELBO 的形式推导是 VI 的基础,也是后续各种VI 方法的前提,大多数 VI 方法都旨在解决高效求解 ELBO 优化的问题。从 ELBO 的形式可以看出,待优化的目标函数是一个函数的期望,如何高效估计出目标的梯度是解决问题的关键。本文将从最经典的 MFVI 讲起,然后依次从几个改进角度来综述 VI 的研究进展。
Mean Field VI (MFVI)
MFVI 最早应用于统计物理,假设变分后验分布是一种完全可分解的分布,如下式:

将公式(9)代入公式(7),同时只考虑第 j 个分布,可得:

其中,是指除掉第 j 项的所有项,
是指与第 j 项无关的常数项。
公式(10)可以看作是一个负 KL Divergence 项,为使得 ELBO(j) 最大,所以负 KL Divergence 为 0, 可得到:

进一步整理得到:

可以利用坐标上升法(Coordinate Ascent, CAVI)来迭代求解该优化问题,具体算法参见下图:

改进MFVI的几个角度
如何更好地度量变分后验分布和真实后验分布之间的差异?
从公式(2)的目标函数可以看出,VI 将近似推断问题转化为了优化问题,使用的是最基础的分布距离度量方法 KL Divergence,因为 KL Divergence 是一个非对称的度量方法,即 KL(q||p)≠KL(p||q) , 因此这里存在几个值得深入研究的点。
是否可以用 KL(p||q) 来度量变分后验分布和真实后验分布的距离?
是否可以用其他度量方法来度量两者之间的距离?
本小节中的 Expectation Propagation 旨在回答第一个问题,f-Divergence 和 Stein Disparency 旨在回答第二个问题。
Expectation Propagation
从广义上讲,凡是基于一个分布簇进行优化参数来逼近真实后验分布的,都可以归为 VI 方法;从狭义上讲,本文开始定义的问题和思路是最经典的 VI 方法。EP 将公式(2)的目标函数更改如下:

EP 也是一个非常活跃的研究领域,由于本文旨在介绍狭义的 VI 方法,因此对 EP 不作详细介绍,感兴趣的同学可以去看这个页面的内容https://tminka.github.io/papers/ep/roadmap.html 。
α-Divergence
KL Divergence 是一种特殊的 α-Divergence,一种常见的 Renyi 定义如下:

同时要求,α>0,αneq1,|Dα|<+∞。

而 α Divergence 是一种特殊的 f Divergence,形式如下:

同时要求 f 是凸函数,且 f(1)=0 。
除了 Renyi 的定义,还有很多不同的定义,有的定义会恰好可以统一VI 和 EP 两种方法,如下图所示,当 α=0 时,该 Divergence 等价于 KL(q||p),相当于是 VI 方法;当 α=1 时,该 Divergence 等价于 KL(p||q),相当于是 EP 方法。

接着 Renyi 的定义,考虑公式(3)的形式:

用 Renyi α-Divergence 来代替公式(16)中的 KL Divergence,定义Variational Renyi Bound(VR Bound,Rényi Divergence Variational Inference),将公式(14)代入可得:

从而推导出 VRBound 如下:

公式(18)的最后一步时根据 Jeson 不等式得来的,它是公式(7)(8)中ELBO 的一般形式,当 α=0 时,VRBound 将降阶为 ELBO。可根据一般 VI 方法的思路来设计 VRBound 的优化算法,将其应用于各种类型的近似推断任务中。
Stein Disparency
Stein Disparency 是近几年比较热门的一种度量两个分布之间距离的方法,定义如下:

其中,F 表示一系列光滑的函数。两个分布越相似,Stein Disparency 就越小。
公式(19)中的右边一项包含了未知的真实后验分布 p(z|x) ,无法计算。如何构造一些合适的 f(z) 可以使得 Ep(z|x)[f(z)]=0 ,从而消除掉未知分布的影响。Stein 的方法给出了一类合适的 f(z) ,如下:

代入到 Ep(z|x)[f(z)] 中可以得到:

令其等于 0,得到:

当找到合适的 f(z) 使得公式(19)右边的一项为 0,只需要计算前面的一项。近几年有一些工作将此方法应用到了 VI 中,其中具有代表性的是 Stein Variational Gradient Descent 和 Operator VI,前者用了 kernel 的方法来计算,后者用了 GAN 的思路来求解。
如何使用更复杂的先验分布来描述参数信息?
先验分布通常是专家经验的一个量化途径,将专家对领域的知识表示为一个先验分布,先验越复杂,表明融入的知识会越多,对后验推断会有较大的影响,为简化计算,先验通常选为高斯分布或者混合高斯分布。近些年的一些研究工作表明,先验分布的复杂度以及超参数的选择对于深度生成模型和贝叶斯神经网络的效果影响很大,本小节简单对先验分布的一些相关工作进行介绍。
AISTATS 2018 一篇来自 Max Welling 组的工作,提出了一种新的复杂先验分布 VampPrior(Variational Mixture of Posteriors Prior),并且在 VAE 上进行了实验测试,相比标准的高斯分布先验和混合高斯分布先验有更好的 Log Likelihood 和表示学习效果。思路如下:
将公式(8)改写为以下形式:

公式(23)中第一项是重建的似然函数,第二项是变分后验分布的熵,第三项是负的变分后验分布和先验分布的交叉熵。
为了保证 ELBO 最大化,需满足第三项也最大化,问题在于如何找到一个合适的先验分布 ,描述参数为 ,使得其拉格朗日乘子表达式最大:

该问题的最优解为:

如果用公式(25)的分布作为先验会导致计算量非常大,同时带来过拟合的风险。因此,这个工作基于此考虑,用下式来代替(25):

这里需要优化的参数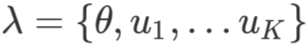

由上图可见,VampPrior 比标准的正态分布和混合高斯分布有着明显的提升,同时因为 Prior 的复杂化和 Posterior 的复杂化是解耦的,如果后验分布采用更加复杂的 Normalized Flow,可能会有更好的效果。
ICLR 2019 一篇来自 Max Welling 参与的工作 Deep Weight Prior,提出了一种 implicit prior distribution 来提升 prior 的复杂度。implicit distribution 大概的定义是,无法得到该分布的 pdf,但可以从该分布中进行采样、估计期望和梯度。这个工作的思路如下:

其中,p(w) 是一个显式分布密度函数,作为先验分布 p(z) 的先验分布,p(z|w;α) 是一个显式的参数分布密度函数,由参数 α 描述。

为统一符号,本文采用了与原文不同的符号表示,但示意图原理一致。从图中可以看出,BNN(Bayesian Neural Network)权重的先验分布可以通过构造一个 VAE 进行学习,而学习的数据则来自相似任务中具有相同网络架构的模型。
具体地讲,本文在 cifar10 数据集上用两层的 5 * 5 和 7 * 7 卷积核作为网络结构,分别训练了 CNN,从中获取了这两类网络架构的权重值作为数据进行学习。学习得到权重的implicit distribution 之后,作为具有同样结构的Bayesian CNN 的权重的 prior 来应用。

上图中左图为学习到的卷积核,而右图为从隐分布中 sample 出来的卷积核。基于复杂的隐先验分布,这篇工作测试了 BCNN 在小样本数据集上的效果,如下图:

从上图中可以看出,本文的方法 dwp 比标准正态分布和均匀分布作为先验有更好的效果。
如何使用更复杂的后验分布簇来降低VI方法的bias?
变分分布是用来替代真实后验分布的,两者的差异越大,后验推断的系统偏差就会越大。有研究结果表明,变分后验分布簇的选择对变分推断效果的影响非常大。
经典的 VI,会基于简单的平均场(mean-fifiled)假设,用可分解的高斯分布或者一些简单结构的分布来作为变分分布;现在的 VI,需要解决的是数据规模更大、维度更高的问题,经典 VI 的变分分布难以满足。因此,最近几年有一系列工作来研究如何构造一系列更加复杂且方便计算的复杂后验分布来解决这一问题。

上图中,最右边表示分布簇表达能力最弱的 MF,最左边表示表达能力最强的真实后验,中间方法都是对 MFVI 的改进,通过复杂化后验分布来降低 bias。
Copula方法
大多数的 VI 方法都基于 Mean-Field 的思路,假设变分后验分布中隐变量之间相互独立,这个假设太强,对结果有一定的影响。
NIPS 2015 一篇 David M. Blei 组的工作 Copula Variational Inference 尝试用统计学的经典方法 Copula 来解决 MF 中隐变量的独立假设问题。这篇工作的动机非常简单,就是找到一种既考虑隐变量之间的关联性同时也容易进行大规模计算的方法。思路如下:

其中公式中的前半部分是 Mean-Field,而后半部分正是所谓的 Copula。
将公式(28)代入到公式(8)得到 Copula VI 的 EBLO,剩下的工作就是推导 ELBO 的梯度估计式,利用随机优化算法更新参数,不同于一般的 VI,Copula VI 有两种参数,一种是描述变分分布的参数,另一种是描述 Copula 的参数,在训练时,固定其中一种来训练另外一种。梯度估计的公式推导在下一小节会有详细介绍,这里不再赘述。

从上图中可以看出 Copula VI 比 MFVI 离真实后验分布更近,bias 更小。Copula 是统计学中的经典方法,对此感兴趣的读者可以去找相关资料进行学习。
辅助变量法

辅助变量法的思路比较简单,它认为隐变量 z 背后还有隐变量 w,是一种层次化建模的思想。即:

图中 r(w|x,z) 正是所谓的辅助变量。将公式(29)代入到公式(8)中可以得到该方法的 ELBO,推导过程类似,这里不再赘述。这种引入辅助变量的方法,其实也是令变分后验分布成为一种表达能力更强的隐分布。
Normalized Flow 归一化流
实际应用中的真实后验分布往往是非常复杂的多模态分布,如何构造出一个复杂的分布簇来逼近多模态分布十分重要。本节介绍的归一化流正是解决这个问题的合适方法。归一化流是一系列分布变换操作,可将简单的高斯分布变换成任意形状的分布。
归一化流的基础是随机变量分布的变换:

其中,p(y) 是 y 的分布,p(x) 是 x 的分布,这里 y=f(x),J 是指雅可比矩阵,即多元函数一阶导数矩阵。
归一化流以及其基础版 pathwise derivative(下一节介绍),核心都在解决一个问题,能否找到一个合适的双射(one-to-one mapping)保证正向映射过程可以很容易 sampling,同时容易计算其雅可比行列式;反向过程,容易计算 inverse function。如果可以解决上述两个问题,就可以将非常简单的分布,比如:均匀分布和高斯分布,通过一系列的变换(Flow)生成出复杂的分布和预期的分布,如下图。

如果初始分布经过 K 次变换如下:

其概率密度函数 pdf 如下:

可以进行如此推导的依据是 law of the unconscious statistician (LOTUS) ,在 pathwise derivative 一节也会提到。
Rezende 和 Mohamed 在 2015 年的 ICML 上提出了用归一化流作为变分后验分布,并给出了两种 baseline 分布变换,一种是 Planar (一种线性变换):

这里 h 是一个光滑的非线性函数,先求公式(32)中的行列式:

其中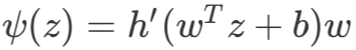

一种是 Radial(一种极性变换):

以 Planar 为例,将归一化流代入到EBLO 中可以得到:


基于归一化流的 VI 方法在求解时和一般的 VI 没太多区别,这里不再赘述。上图是基于归一化流做的一个分布逼近实验,从结果中可以看出通过 32 次分布变换之后,可以准确地逼近左图中给出的复杂分布。
除了文章中介绍的归一化流方法,最近几年学术界提出了很多种 Flow 的方法,比如:NICE、Masked Autoregressive Flow(MAF)、Inverse Autoregressive Flow(IAF)等。感兴趣的同学可以去看Stanford CS236 Deep Generative Models Course。
如何通过随机梯度估计方法来提升VI方法scalability?
从变分推断的优化目标函数 ELBO 中可以看到,需要优化的是一个函数的期望,而非确定性的函数。相比于其他优化算法,基于梯度的随机优化算法在解决大规模数据、高维度问题中有着巨大的优势,因此,如何准确估计出函数期望的导数是核心问题。机器学习中,常用的随机梯度估计方法包括:score Function 和 pathwise derivative。
Score Function (SF)
所谓的 score function 是 ,score function 的期望为 0,证明如下:

这样会带来非常多的便利,比如:一种降低估计方差的思路,将代价函数 f(x) 改造为 f(x)-b ,其中 b 是所谓的 baseline。因为 score function 的期望为 0,所以:
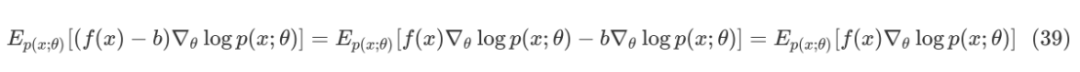
ELBO 推导出的优化问题如下:

其中,x 是观测变量,z 是隐变量,q(z) 是变分分布,λ 是变分分布的参数。
计算 L(λ) 的梯度如下:

公式(41)倒数第三行到导数第二行的推导利用了 score function 的期望为 0 这一性质,基于公式(41)就可以利用蒙特卡洛采样进行梯度估计,然后利用随机优化算法进行参数的更新。算法流程图如下:

参数估计除了要保证无偏之外,还希望估计的方差要尽量小。在此基础上,本节介绍一种经典的降低方差的方法 Control Variates,也会用到 score function 的一些性质。
这里,假设一个估计是 f,希望可以找到一个新估计,使得:

控制变量法是构造一类估计函数,定义如下:

其中,a 是一个标量,h 是一个函数。由公式(43)容易得到, 和 f 的期望相同,方差如下:

直观上讲,Cov(f,h) 越大,新估计的方差越小,控制变量效果越好。令:

可得:

最优参数值是协方差和方差之比。为了方便计算,函数 h(z) 的选择是 score function,即:

所以,E[h(z)]=0。
用新的估计来替换公式(41)中的估计 f,如下:

基于蒙特卡洛采样对梯度进行估计,从上述推导中可以保证新的估计方差会更小。
Score Function 在使用时一般要满足以下条件:
代价函数 f(x) 可以是任意函数。比如可微的,不可微的;离散的,连续的;白箱的,黑箱的等。
这个性质是其最大的优点,使得很多不可微的甚至没有具体函数的黑箱优化问题都可以利用梯度优化求解。
分布函数 p(x;θ) 必须对 θ 是可微的,从公式中也看得出来。
分布函数必须是便于采样的,因为梯度估计都是基于 MC 的,所以希望分布函数便于采样。
SF 的方差受很多因素影响,包括输入的维度和代价函数。
另外,SF 还有一些其他的名称,Likelihood Ratio,Automated Variational Inference,REINFORCE,Policy Gradients,在机器学习的很多领域中都有广泛的应用。
Pathwise Derivative (PD)
不同于 Score Function 对代价函数没有任何约束,PD 要求代价函数可微,虽然 SF 更具一般性,但 PD 会有更好的性质。PD 在机器学习领域有另一个名称是 reparameterization trick,它是著名的深度生成模型 VAE 中一个重要的步骤。
PD 的思路是将待学习的参数从分布中变换到代价函数中,核心是做分布变换(即所谓的 reparameterization,重参数化),计算原来分布下的期望梯度时,由于变换后的分布不包含求导参数,可将求导和积分操作进行对换,从而基于 MC 对梯度进行估计。

如上述公式,从一个含参 θ 分布中采样,等同于从一个简单无参分布中采样,然后进行函数变换,并且此函数的参数也是 θ。变换前,采样是直接从所给分布中进行,而采用重参数化技巧后,采样是间接地从一个简单分布进行,然后再映射回去,这个映射是一个确定性的映射。其中,映射有很多中思路,比如:逆函数、极变换等方法。
PD 的一个重要理论依据是 Law of the Unconscious Statistician (LOTUS) ,即:

从定理中可以看到,计算一个函数的期望,可以不知道其分布,只需要知道一个简单分布,以及从简单分布到当前分布的映射关系即可。
基于 Law of the Unconscious Statistician (LOTUS) 对 PD 进行推导,如下:

利用 MC 可以估计出梯度为:

其中 。从推导中可以看出,分布中的参数 θ 被 push 到了代价函数中,从而可以将求导和积分操作进行对换。
分布变换是统计学中一个基本的操作,在计算机中实际产生各种常见分布的随机数时,都是基于均匀分布的变换来完成的。有一些常见的分布变换可参见下表:

▲ 图:常见分布变换
在使用 PD 时需要满足以下性质:
代价函数要求是可微的,比 SF 更严格
在使用 PD 时,并不需要显式知道分布的形式,只需要知道一个基础分布和从该基础分布到原分布的一个映射关系即可,这意味着,不管原来分布多么复杂,只要能获取到以上两点信息,都可以进行梯度估计;而 SF 则需要尽量选择一个易采样的分布
PD 的方差受代价函数的光滑性影响
另外,PD 还有一些其他名称,Stochastic backpropagation,Affiffiffine-independent inference 和 Reparameterisation Tricks 等。
应用
变分推断方法在深度学习中有两个非常典型而且热门的应用,一个是贝叶斯神经网络 BNN,一个是变分自编码器 VAE。后续会专门写两篇关于 BNN 和 VAE 的综述,这里简单介绍一下。
贝叶斯神经网络 BNN
贝叶斯神经网络不同于一般的神经网络,其权重参数是随机变量,而非确定的值。如下图所示:

假设 NN 的网络参数为 W,p(W) 是参数的先验分布,给定观测数据 D={X,Y},这里 X 是输入数据,Y 是标签数据。BNN 希望给出以下的分布:

其中:

这里 P(W|D) 是后验分布,P(D|W) 是似然函数,P(D) 是边缘似然。
从公式(53)中可以看出,用 BNN 对数据进行概率建模并预测的核心在于做高效近似后验推断,而 VI 是一个非常合适的方法。
BNN 不同于 DNN,可以对预测分布进行学习,不仅可以给出预测值,而且可以给出预测的不确定性。这对于很多问题来说非常关键,比如:机器学习中著名的 Exploration & Exploitation (EE)的问题,在强化学习问题中,agent 是需要利用现有知识来做决策还是尝试一些未知的东西;实验设计问题中,用贝叶斯优化来调超参数,选择下一个点是根据当前模型的最优值还是利用探索一些不确定性较高的空间。比如:异常样本检测,对抗样本检测等任务,由于 BNN 具有不确定性量化能力,所以具有非常强的鲁棒性。
变分自编码器 VAE
深度生成模型中两个最有名的模型是 GAN 和 VAE,有工作介绍过GAN 和 VAE 从 VI 的视角是可以统一起来的。这类简单介绍一下VAE,VAE 是一种隐变量模型(Latent Variable Model, LVM)和深度学习巧妙结合的产物。如下图:

模型中由两个部分构成,一个是观测数据 x 到隐变量 z 的映射模型,称为 encoder,另一个是从隐变量 z 到观测数据 x 的映射模型,称为 decoder。encoder 相当于是求一个后验分布,这里用 VI 的方法,假设用一个高斯变分分布 qф(z|x) 来代替真实的后验分布,并用 DNN 来近似逼近这个高斯分布的均值和方差。
从上图中可以看到,经过encoder 和decoder 的映射,输入是观测数据 x,期待的输出数据也是 x,不需要对样本进行标注。VAE 在 loss function 推导时需要用到随机梯度估计一节提到的 Pathwise Derivative,在这里叫做 Reparameterization Trick 来估计梯度。VAE 是一个非常有趣的模型,从结构上来看,隐变量空间相当于是一个原数据的降维表示,在很多地方将会有非常有趣的应用。
VI 除了应用在 BNN 和 VAE 之外,还在 Policy Gradient、AutoML 和 PGM 等领域被广泛使用。
总结
本文是对 VI 方法进展的一个简述,主要思路是从 VI 经典方法和相关的几个问题来展开,包括:分布测度、复杂先验、复杂后验、VI 的可扩展性以及应用来叙述。
由于 VI 是一大类方法,每年新增的研究工作不计其数,近二年与 MCMC 的结合和统一催生了一批新的高效方法和理论分析,实在难以覆盖所有工作。希望通过本文介绍的思路,读者可以快速地了解这个领域,做应用的同学可以找一些合适的方法来解决应用问题,准备做机器学习理论研究的同学可以参考本文的思路,有针对性地寻找到感兴趣的方向。
参考文献
[1] Zhang, Cheng, et al. “Advances in Variational Inference.” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 8, 2019, pp. 2008–2026.
[2] Blei, David M., et al. “Variational Inference: A Review for Statisticians.” Journal of the American Statistical Association, vol. 112, no. 518, 2017, pp. 859–877.
[3] Wainwright, Martin J., and Michael I. Jordan. Graphical Models, Exponential Families, and Variational Inference. 2008.
[4] Rezende, Danilo Jimenez, and Shakir Mohamed. “Variational Inference with Normalizing Flows.” ArXiv Preprint ArXiv:1505.05770, 2015.
[5] Kingma, Diederik P., et al. “Improving Variational Inference with Inverse Autoregressive Flow.” ArXiv Preprint ArXiv:1606.04934, 2016.
[6] Tran, Dustin, et al. “Copula Variational Inference.” NIPS’15 Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2, 2015, pp. 3564–3572.
[7] Ranganath, Rajesh, et al. “Operator Variational Inference.” NIPS’16 Proceedings of the 30th International Conference on Neural Information Processing Systems, 2016, pp. 496–504.
[8] Liu, Qiang, and Dilin Wang. “Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm.” Advances in Neural Information Processing Systems, 2016, pp. 2370–2378.
[9] Atanov, Andrei, et al. “The Deep Weight Prior.” ICLR 2019 : 7th International Conference on Learning Representations, 2019.
[10] Tomczak, Jakub M., and Max Welling. “VAE with a VampPrior.” ArXiv Preprint ArXiv:1705.07120, 2017.
[11] Yin, Mingzhang, and Mingyuan Zhou. “Semi-Implicit Variational Inference.” ICML 2018: Thirty Fifth International Conference on Machine Learning, 2018, pp. 5646–5655.
[12] Ranganath, Rajesh, et al. “Black Box Variational Inference.” Journal of Machine Learning Research, vol. 33, 2014, pp. 814–822.

点击以下标题查看更多往期内容:

10.31-11.1 北京智源大会

🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐





