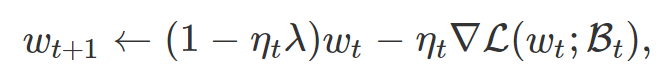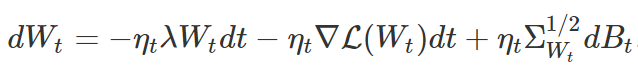![]()
从事机器学习方面相关研究的人都了解,网络模型的最终性能少不了优化。其中损失函数扮演了非常重要的角色,而随机梯度下降算法(SGD)由于其良好的收敛性,常常被用来进行梯度更新。为了加快收敛速度,缩短训练时间,同时为了提高求解精度,采用随机梯度下降算法应该注意学习率(Learning Rate, LR)等参数的调整。那么 LR 的大小对现代深度学习与传统优化分析的是怎样的呢?下面通过一篇论文进行解答。
该论文就是《Reconciling Modern Deep Learning with Traditional Optimization Analyses: The Intrinsic Learning Rate》,指出了归一化网络与传统分析之间的不兼容性。在深入研究这些结果之前,先回顾一下权重衰减(又名ξ2 正则化)训练归一化网络。则随机梯度下降 (SGD) 的第 t 次迭代为:
![]()
λ表示权重衰减 (WD) 因子(或者ℓ2 - 正则化系数),ηt 表示学习率,Bt 表示 batch,∇L(wt,Bt)表示 batch 梯度。
在比较理想的假设下(即在随机初始化期间固定顶层不会影响最终准确度),用于训练此类归一化网络的损失函数尺度不变,这意味着 L(wt ; Bt)=L(cwt ; Bt), ∀c>0。
尺度不变性的结果就是:对于任意 c>0,∇wL|w=w0=c∇wL|w=cw0 以及∇2wL|w=w0=c2∇2wL|w=cw0。
传统观点(Conventional Wisdom, CW)
CW1:当 LR 降至零时,优化动态收敛到一条确定的路径(梯度流),沿着该路径训练损失显著减小。
回想一下,在解释传统(确定)梯度下降中,如果 LR 小于损失函数平滑度的倒数,那么每一步都会减少损失。SGD 是随机的,在可能的路径上都有分布。但是,极小的 LR 可以看作是 full-batch 梯度下降(GD),它在无穷小的步长范围内接近梯度流(GF)。
上述推理表明,
极小的 LR 至少可以减少损失,那么更高的 LR 也可以。
当然,在深度学习中,我们不仅关注优化,还关注泛化。在这里小的 LR 是有危害的。
CW2:为达到最好的泛化能力,LR 在几个 epoch 之后必须迅速地变大。
这是一个经验发现:
从一开始使用太小的学习率或太大的批量(所有其他超参数固定)会导致更糟糕的泛化。
对这种现象的一个普遍解释是,在 SGD 过程中梯度估计中的噪声有利于泛化(如前所述,当 LR 非常小的时候,这种噪声会趋于平均)。许多研究者认为,噪声之所以有帮助,是因为它使轨迹远离尖锐极小值(sharp minima),而这些极小值让泛化变得更差,尽管这里有一些不同的意见。
Yuanzhi Li 等人在论文《Towards Explaining the Regularization Effect of Initial Large Learning Rate in Training Neural Networks》中给出一个示例,一个简单的双层网络。其中,由于 LR 小而导致的泛化结果更差在数学上得到了证明,同时也得到了实验验证。
CW3:用随机微分方程(Stochastic Differential Equation, SDE)在固定高斯噪声的连续时间内对 SGD 进行建模。也就是说,可以把 SGD 看做是一个扩散过程,它在训练过的网络上混合一些类吉布斯(Gibbs-like)分布。
SGD 是带有噪声项的梯度下降,它具有的连续时间近似可以描述为以下扩散过程:
![]()
其中,σWt 为随机梯度∇L(Wt;Bt)的协方差,Bt 为适当维数的布朗运动(Brownian motion)。一些研究采用了 SDE 观点,对噪声的影响进行了严格的分析。
在本文中,SGD 变成了一个环境中的几何随机游走,原则上可以更深入地探索环境。例如,偶尔采取增加损失的步骤。但是,由于缺乏对损失情况的数学描述,分析起来很困难。
各种文献假设 SDE 中的噪声是各向同性高斯分布(isotropic Gaussian),然后根据常见的吉布斯分布导出随机游走平稳分布的表达式。由于噪声的大小(与 LR 和 batch 大小有关)控制着收敛速度和其他特性,这种观点直观地解释了一些深度学习现象。例如,在论文《Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour》中,SDE 近似意味着线性扩展规则。
这就引出了一个问题:
SGD 是否真的像一个在损失环境中混合的扩散过程?
现在对归一化网络的真实发现进行描述,这表明上述传统观点相当不合理。
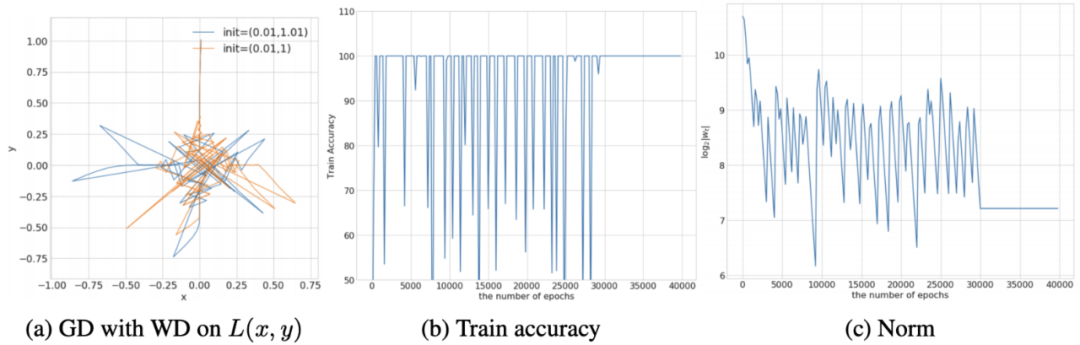
众所周知,如果 LR 小于光滑度的倒数,那么梯度下降的轨迹将接近梯度流的轨迹。但是对于归一化网络,损失函数的尺度不变,因此可以证明在原点附近是非光滑的(即平滑度变得无限)。这种非光滑性问题是非常真实的,并且在任何非零学习率下,使得全批次 SGD 的训练变得不稳定甚至混沌。这在经验上和可证明的情况下都会发生,并与一些 toy 损失有关。
![]()
注意,WD 在这种影响中起着关键作用,因为没有 WD,参数范数单调增加,这意味着 SGD 始终远离原点。
聪明的读者或许想知道使用较小的 LR 是否可以解决此问题。不幸的是,使用较小的 LR 将不可避免地靠近原点,这是因为一旦梯度变小,WD 将主导动力学,并以几何速度减小范数,从而在尺度不变的情况下导致梯度再次增加。只要梯度任意地缩小(现实中并不能降为零),就会发生这种情况。
实际上,这一点极好(也极罕见),即使正确地优化损失,也必须提前停止。
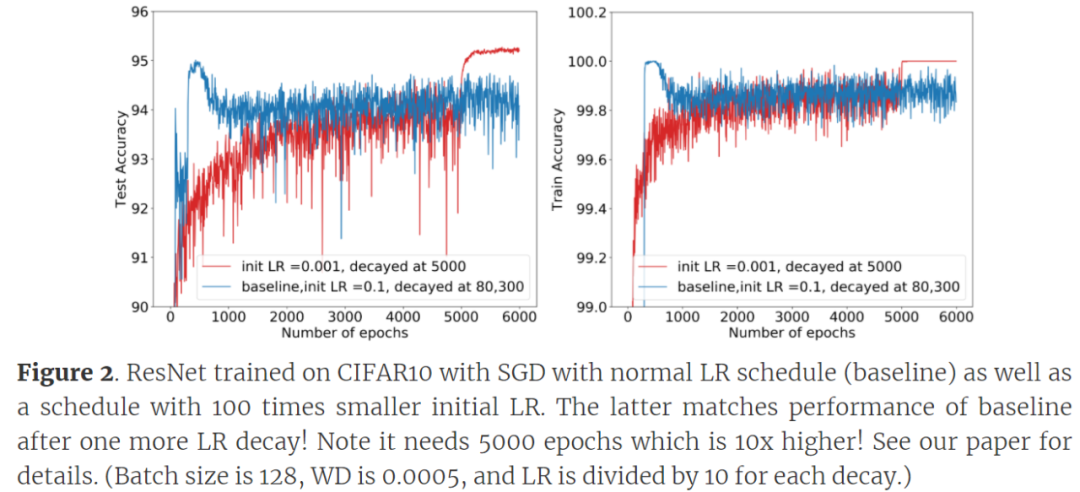
针对 CW 2:小 LR 可以与大 LR 一样好地泛化。
![]()
令人惊讶的是,即使没有其他超参数变化,泛化能力也不会受到太小 LR 的影响。论文《An Exponential Learning Rate Schedule for Deep Learning》中,研究者通过其他超参数的变化来补偿小 LR。
针对 CW 3:SGD 的随机游走和 SDE 视角差得很远。没有证据表明,这两种视角会像传统理解那样混合在一起,至少在标准训练时间内不会。
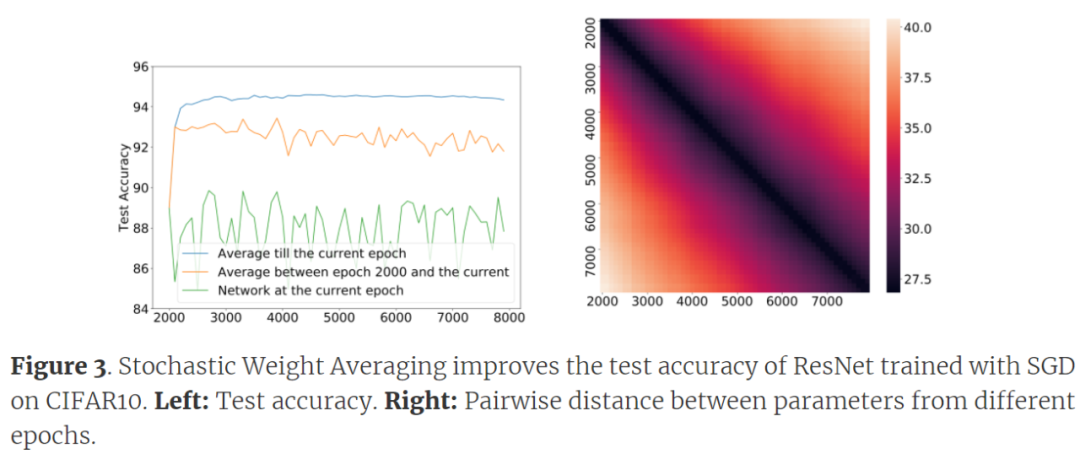
实际上,通过随机权重平均(Stochastic Weight Averaging, SWA)现象,就已经存在反对全局混合的证据。在 SGD 的轨迹上,如果来自两个不同 epoch 的网络参数进行平均化处理,那么平均测试损失会比任何一个小。
如下图 3 所示,通过平均值改进的运行时间比平时长 10 倍。然而,对于从不同初始化中获得的两个解,SWA 的准确度并没有提升。因此,检查 SWA 是否成立,可以区分从同一轨迹得出的解对和从不同轨迹得出的对,这表明扩散过程在标准训练时间内没有混合到平稳分布(这并不奇怪,因为混合的理论分析并不表明它发生得很快)。
![]()
实际上,Izmailov 等人在论文《Averaging Weights Leads to Wider Optima and Better Generalization》中已经注意到,SWA 排除了 SGD 是一个混合到单一全局均衡的扩散过程。他们认为,假设损失表面是局部强凸的,则 SGD 的轨迹可以很好地用局部极小值 W^* 邻域的多变量 Ornstein-Uhlenbeck(OU)过程来近似。由于对应的平稳点是局部极小值 W^* 邻域的多维高斯函数 N(W^*, Σ),这就解释了为什么 SWA 有助于减少训练损失。
但是,我们注意到 Izmailov 等人在论文《Averaging Weights Leads to Wider Optima and Better Generalization》中的建议也被以下事实所驳斥:来自 epoch T 和 T+Δ权重的ℓ2 距离随着每个 T 的Δ单调增加(如上图 3 所示),而在 OU 过程中,E[| W^T−W^T+Δ |^2]应作为 T, →+∞收敛至常数 2Tr[Σ]。这表明与 OU 过程中假设的不同,所有这些权重都是相关的。
这篇论文有一个新的理论(一些部分得到了严格的证明,另一些部分得到了实验的验证),表明
LR 并没有扮演大多数讨论中假定的角色。
人们普遍认为,LR η 通过改变噪声的大小来控制 SGD 的收敛速度,并通过改变噪声的大小来影响泛化。然而,对于用 SGD+WD 训练的归一化网络,LR 的作用更为微妙,因为它扮演两个角色:1)损失梯度之前的乘数;2)WD 之前的乘数。从直观上讲,人们认为 WD 部分是无用的,因为损失函数是尺度不变的,因此第一个角色更重要。但令人惊讶的是,这种直觉是完全错误的,事实证明第二个角色比第一个角色重要得多。进一步的分析表明,更好地衡量学习速度的方法是ηλ,研究者称之为内在学习率或内在 LR,用λ_e 表示。
虽然先前的论文注意到 LR 和 WD 之间存在密切的相互作用,但在论文《An Exponential Learning Rate Schedule for Deep Learning》中给出了数学证明,即如果 WD* LR,则λη是固定的,改变 LR 对动力学的影响相当于重新标定初始参数。据研究者所知,在现代体系架构上,SGD 的性能对于初始化的规模具有鲁棒性(通常独立于初始化),因此在保持固有 LR 不变的同时更改初始 LR 的影响也可以忽略不计。
论文《An Exponential Learning Rate Schedule for Deep Learning》通过对归一化网络的 SGD 提供新的 SDE 风格分析来深入了解内在 LR λ_e 的作用,得出以下结论(部分取决于实验):
在归一化网络中,SGD 确实会导致快速混合,但在函数空间(即网络的输入 - 输出行为)中不会。混合发生在 O(1/λ_e)迭代之后,与传统扩散游走分析在参数空间中保证的指数慢混合不同。
为了解释函数空间中混合的含义,研究者将 SGD(执行固定数量的步骤)视为从已训练网络分布中对已训练网络进行采样的一种方法。因此,来自固定初始化的 SGD 的最终结果可以看作是概率分类器,其在任何数据点上的输出都是 K 维向量,其第 i 个坐标是输出标签 i 的概率(K 是标签总数)。现在,如果两个不同的初始化都导致 SGD 对保留的数据点生成存在 5% 误差的分类器。那么先验者将想象在给定的保留数据点上,第一个分布的分类器与第二个分布中的分类器不一致。
但是,在函数空间中收敛到一个均衡分布并不意味着不一致的可能性近乎为零,也就是说,分布几乎不基于初始化而改变。这是研究者在实验中发现的,他们的理论也是围绕这一现象展开的。
![]()
原文链接:http://www.offconvex.org/2020/10/21/intrinsicLR/
Java工程师入门深度学习(三):轻松上手Deep Java Library
DJL是亚马逊推出的开源的深度学习开发包,它是在现有深度学习框架基础上使用原生Java概念构建的开发库。DJL目前提供了MXNet,、PyTorch和TensorFlow的实现。Java开发者可以立即开始将深度学习的SOTA成果集成到Java应用当中。
11月5日20:00
,魏莱(AWS算法工程师)将带来线上分享,介绍DJL主要模块并结合具体场景讲解各模块的使用方法、主要API的使用方法和注意事项、神经网络从训练到部署的基本流程并结合动手深度学习Java版讲解具体代码和实操展示。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com