分享Google发表在NeurIPS 2020的关于数据增强的一篇文章
《RandAugment: Practical automated data augmentation with a reduced search space》。从标题可知,提出的自动数据增强方法相比以往减少了数据增强的搜索空间,具有工程实用性。
import numpy as np transforms = ['Identity', 'AutoContrast', 'Equalize', 'Rotate', 'Solarize', 'Color', 'Posterize', 'Contrast','Brightness', 'Sharpness', 'ShearX', 'ShearY', 'TranslateX', 'TranslateY']def randaugment(N, M):'''Generate a set of distortions.Args:N: Number of augmentation transformations to apply sequentially. M: Magnitude for all the transformations.'''sampled_ops = np.random.choice(transforms, N)return [(op, M) for op in sampled_ops] if name == 'main':print(randaugment(2,3))
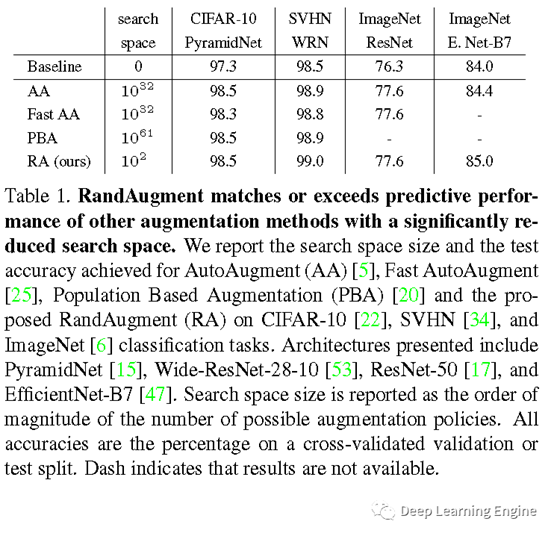
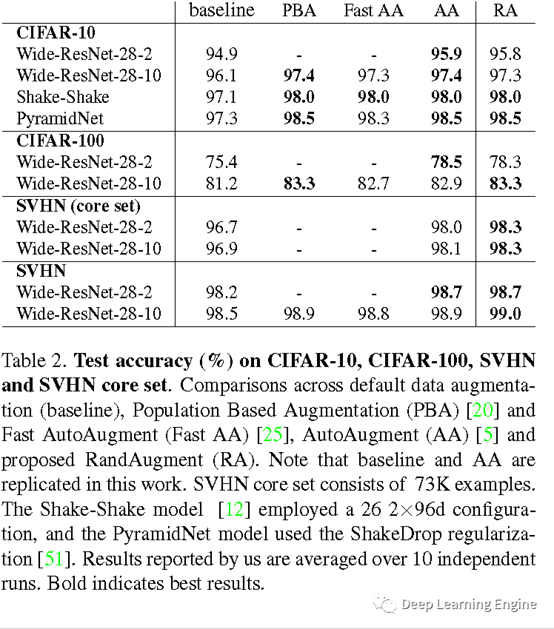
作者分别在CIFAR-10, CIFAR-100,SVHN, ImageNet 以及COCO数据集上进行了分类和目标检测等实验验证。
A. 多种数据增强方式的对比
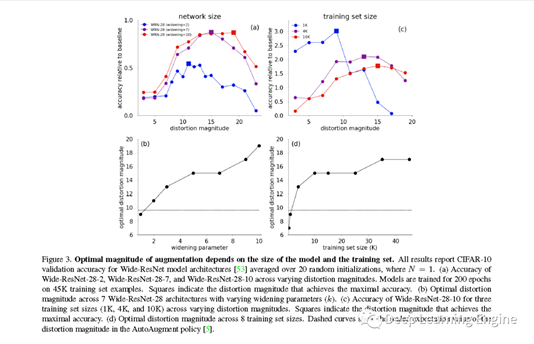
B. 模型和数据集大小与形变程度的关系
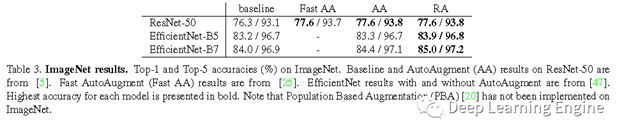
C. ImageNet数据集实验结果
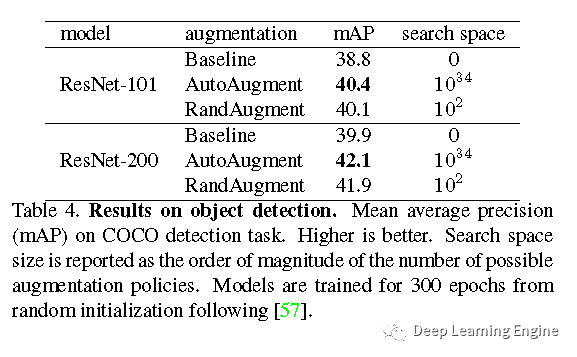
D. 目标检测任务实验结果
E. 增加数据增强方式对性能的提升
F. 不同增强方式对性能的影响
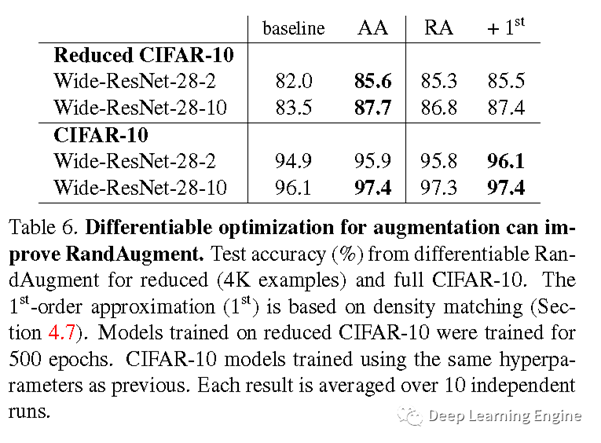
G. 数据集大小对数据增强性能的影响
H. 不同数据增强强度方式对准确率的影响
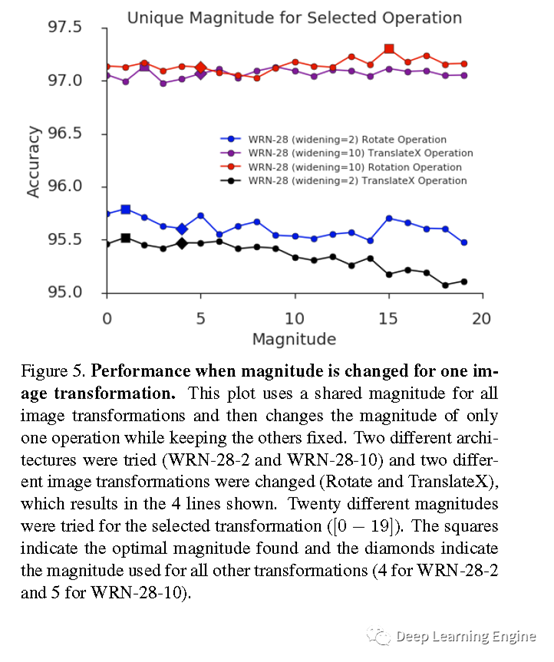
I. 不同Magntitude对准确率的影响
作者的实验目标:
展示设计的方法相对于以前的数据增强方法的收益。
结论梳理汇总:
1、首先证明通过在小数据集上训练代理任务(子任务)模型,然后在迁移到目标任务上的策略不是最优的。网络模型和数据集越大,需要进行更大的数据扭曲增强。
2、学习型的数据增强方法可以学习更适合的代理任务(子任务)增强的强度,而不是更大的目标任务。
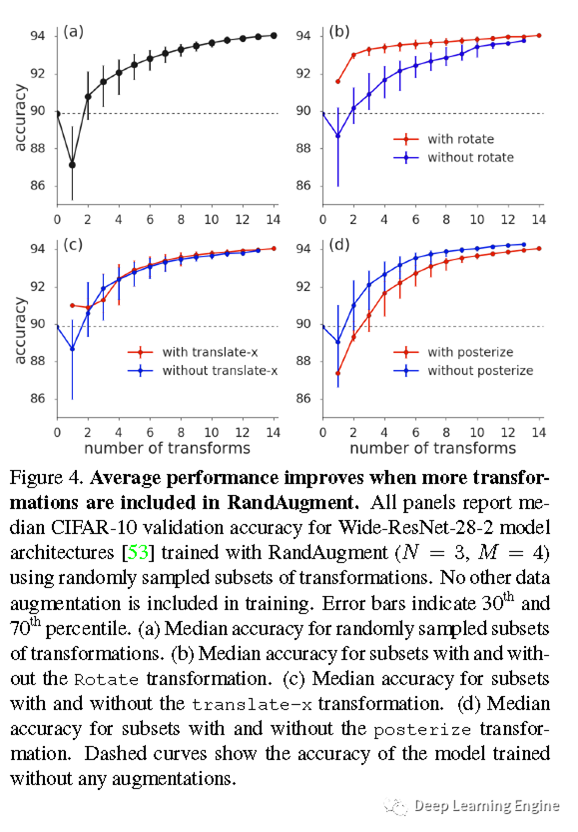
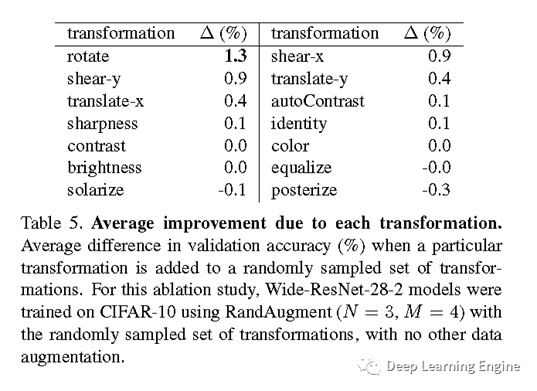
3、通过设置两个超参N(选择数据增强方式的类别个数)和M(每种数据增强方式进行图像扭曲变形的强度),与其他增强方法进行对比分析。通过实验对比发现,在不同的任务上RandAugment均达到SOTA。这些实验也表明了RandAugment对数据类别极不敏感。为进一步研究其数据敏感性,作者在CIFAR-10训练WideResNet-28-2,并在14种数据增强的方法中随机删除了flips, pad-and-crop,or cutout等。实验发现数据增强方式的增多,将有助于进一步提升模型的准确率。即使用两种数据增强方式,模型的准确率也提升了1%。为进一步验证,作者分别对每种数据增强方式进行单独的评估,发现旋转的提升是最大的,色调分离似乎有副作用。
4、实验中,选择每种数据增强的方式的概率是相等的。那就存在一个开放的问题,
每种数据增强方式被选择的概率是否对模型性能的提升有影响?作者通过设计的实验发现其有略微的影响。但这种方式的成本较高,也给大家留下一个开放的研究问题。