论文导读 | DeepXplore:深度学习系统的自动化白盒测试

更多干货内容请关注微信公众号“AI前线”,(ID:ai-front)
你如何知道已经做了足够多的测试了呢?代码覆盖率显然不是一个有用的指标:即使是一个输入或非常少的 DNN输入就可能达到 100%的代码覆盖率。作为替代,本文的作者们定义了一个神经元覆盖指标(neuron coverage metric),去查看在执行测试套件(test suite)期间被激活的神经元百分比。
或许更根本的问题是,你怎么知道在一个给定的测试案例中正确的输出是什么?使用手动标记的现实测试数据很难获得良好的覆盖率。作为替代,DeepXplore使用了差分测试(differential testing),一种比较多个不同系统并查看它们对应输出差异的概念。虽在这篇论文中没有提到,但这种测试与集成(ensemble)的想法非常接近,不同的是在这里我们是去找集成中不吻合的案例。当我们使用一个集成时,我们本质上就是在说:“我知道任何一个模型在任何地方都是可能产生变化的,所以我使用一系列模型和多数投票法(majority voting)来提高整体的准确性。”不同模型之间在一些输入上的差异被认为是正常和符合预期的。 DeepXplore以不同的方式看待事物:如果其他模型都对给定的输入做出一致的预测,而只有一个模型对此做出了不同的预测,那么这个模型就会被判定有一个漏洞。
当你用上述的测试方法去测试目前最先进的(state-of-the-art)DL模型时又会发生什么呢?
DeepXplore有效地在目前最先进的 DL模型上发现了数千个不正确的极端案例行为(corner-case behaviors,比如说自动驾驶汽车撞向护栏、恶意软件伪装成好软件),这个结果是基于在五个流行的数据集上训练的数千个神经元,其中包括来自 ImageNet数据和 Udacity 自动驾驶的数据。对于所有经过测试的 DL模型,即使是在一台普通的商品笔记本电脑上运行,DeepXplore从生成一个测试输入到显示结果错误的平均用时也不到一秒。
这一点值得重点再强调一下:把你最训练有素、最先进的深度学习系统给我,我能够在一秒钟以内用我的电脑中找到让这个模型崩溃的办法!
论文发现的以下的测试案例很好地突出了这为何会是一个问题:

令人遗憾的是,尽管 DL系统功能令人印象深刻,但由于训练数据偏差、过度拟合和模型不足等原因,在极端案例(corner cases)中经常会出现意外或不正确的行为。因此,对于人员安全和网络安全都至关重要的 DL系统就像传统软件一样,必须系统地测试不同的极端案例,以检测和修复任何潜在的缺陷或事与愿违的行为。
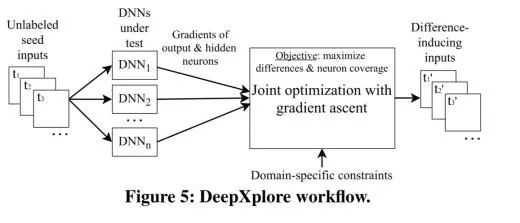
(图 5:DeepXplore的工作流程)
因为 DeepXplore是基于差分测试(differential testing),所以它至少需要两个具有相同功能的 DNN。 取决于你想要做什么,DNN的数量可能是一个限制因素。“但是,我们的评估显示,对于一个给定的问题,在大多数情况下,多个不同的 DNN很容易获得,因为开发人员为了定制化和提高准确性,通常会定义和训练他们自己的 DNN。”给定两个或更多的模型,DeepXplore从一组测试输入开始探索模型空间(model space):
DeepXplore将未标记的测试输入作为种子(seeds),并生成覆盖大量神经元的新测试(即将其激活为高于可定制阈值的值),同时使测试过的 DNN生成不同的行为。
在生成新测试的同时,DeepXplore试图最大限度地提高神经元的覆盖率(neuron coverage)和尽可能多地揭示出让 DNN产生行为区别的测试。这两个目标都是通过完整的测试来发现错误的极端方案所必需的。在这个过程中,也可以对 DeepXplore进行自定义约束,以确保生成的测试案例(test cases)保持在给定范围内(例如,图像像素值必须介于 0和 255之间)。
考虑一个简化后的例子,两个深度神经网络用于将图像分类为汽车或者人脸。最开始我们可能会遇到这样的情况,即两个网络均把给定的图像以高概率归类为汽车:
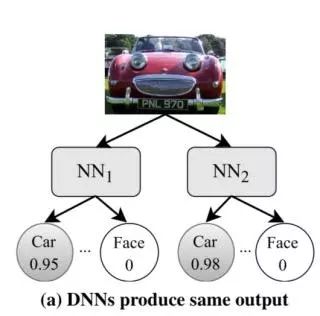
然后,DeepXplore会试图通过修改输入以使一个神经网络继续将输入的图像归类为汽车,而另一个 DNN则会认为它是一个面孔,从而最大化发现差异化行为的可能性。
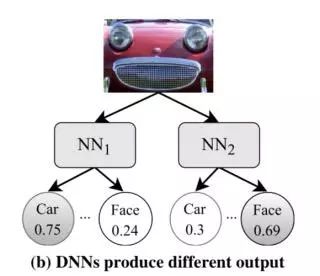
本质上,这种测试是在探测输入空间(input space)介于不同 DNN决策边界(decision boundaries)的部分:
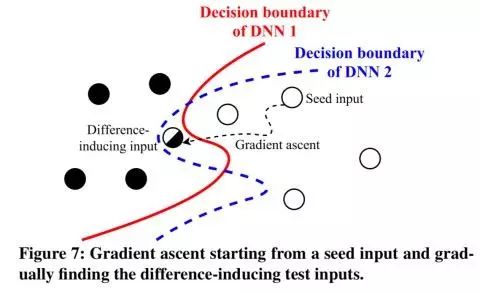
需提醒的一点是,此时的神经网络已经被训练过了,所以权重(weight)是固定的。DeepXplore使用了梯度上升法( gradient ascent)来解决神经元覆盖和差异行为最大化的联合优化问题(joint optimisation problem):
首先,我们将输出值作为变量,权重参数作为常量,计算出输出层(output layers)和隐藏层(hidden layers)中神经元输出的梯度。对于大多数的 DNN而言,相关的梯度都可以被有效的计算...接下来,我们通过迭代执行梯度来修改测试的输入,以最大化连接地联合优化问题的目标函数(objective function)...
联合目标函数如下所示:
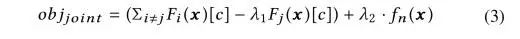
在函数的第一项,我们试图在其他模型保持当前预测的情况下改变一个模型的输入方向,从而让其做出区别于其他模型的预测。用超参数 (hyperparameter)平衡了这两个因素的相对重要性。
在函数的第二项,我们试图最大限度地激活一个不活跃的神经元,把它推到阈值 t 以上。
λ2 超参数平衡了这两个目标的相对重要性。

完整的算法如下所示:

完整的实现(implementation)包含基于 Keras和 TensorFlow的 7086行 Python代码。
DeepXplore在 3个 DNN上进行了测试,每个 DNN又有 5个不同的数据集。
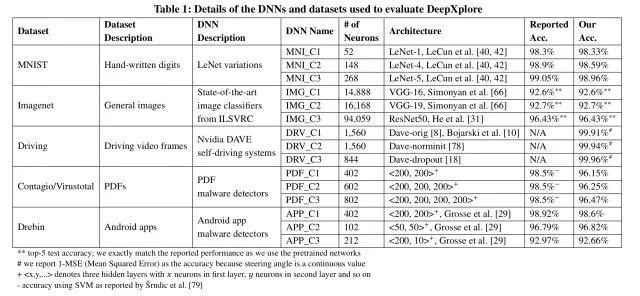
在基于图像的问题领域,探索了三种不同的约束:
第一个约束模拟不同照明条件下的效果:DeepXplore可以使图像变暗或变亮,但不能改变内容。 在下图中,上面一行显示的是原始种子输入,下面一行显示的是 DeepXplore发现的差异诱导测试输入。箭头指向表示自动驾驶汽车决定转向的方式。

第二个约束模拟意外或故意用单个小矩形遮挡住的镜头。

第三个约束通过允许使用多个微小的黑色矩形进行遮挡来模拟透镜上多处被污垢覆盖后的影响。
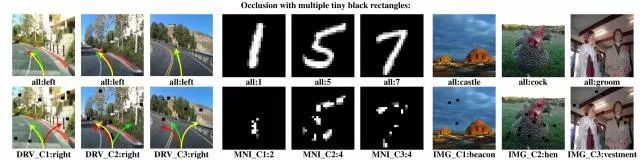
DeepXplore在所有测试的 DNN中发现了数千的错误行为。表 2(如下)总结了在用对应测试集中随机选取的 2000个种子输入(seed input)对 DNN进行测试时,DeepXplore在每个测试的 DNN中发现的错误行为的数量。
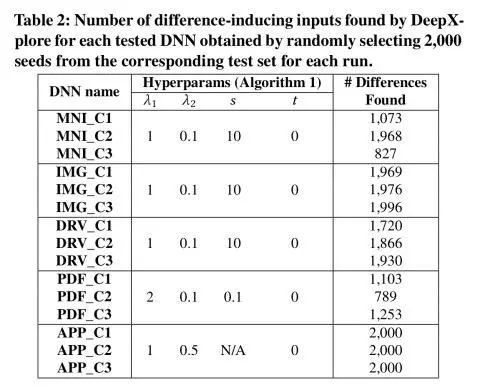
下表(Table 5)突出了将神经元覆盖纳入目标函数作为一种增加输入多样性的方式的重要性:
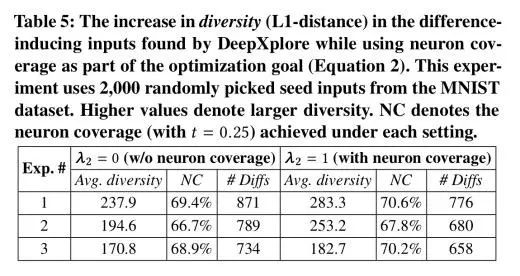
平均而言,DeepXplore的神经元覆盖率比随机测试(random testing)高 34.4%,比对抗测试(adversarial testing)高出 33.2%。
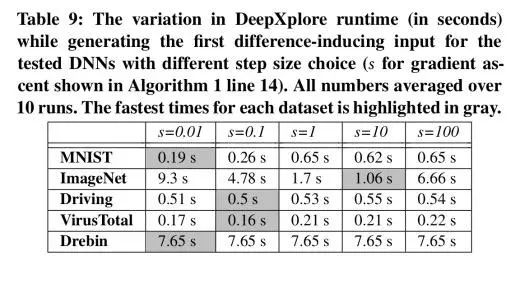
对于大多数模型,DeepXplore都可以在几秒钟内找到第一个引起差异的输入:
本文摘自文献:
DeepXplore: automated whitebox testing of deep learning systems Pei et al., SOSP’17
英文原文链接:
https://blog.acolyer.org/2017/11/01/deepxplore-automated-whitebox-testing-of-deep-learning-systems/
今日荐文
点击下方图片即可阅读

Jeff Dean出品:用机器学习索引替代 B-Trees,3倍性能提升,10-100倍空间缩小
给您推荐一堂运维体系管理课
应用运维体系如何建设?体系稳定性如何保障?云计算时代运维又该如何转型?十年运维“老司机”赵成现在极客时间开设“赵成的运维体系管理课”,聚焦分布式软件架构应用运维领域,分享对运维的痛点和问题深度思考。识别下方二维码即可查看详情。


