ICLR 2020 | NLP 预训练模型的全新范式:对比学习
生成式模型有着其天生的优势,即学习到丰富的特征,但它也有广受诟病的确定。判别式目标函数——长期以来被认为是无用的。这是因为,判别式模型通常不是直接拟合原有的分布流形,学习到的特征较为单一。但是,最近一些工作的基于对比学习的自监督学习框架,表现十分出色。
长期以来,预训练语言模型(PTM)专注于基于最大似然估计(MLE)的目标任务,也就是采用的“生成式模型(Generative Model)”。例如 BERT 的目标任务就是一个典型的 MLE:
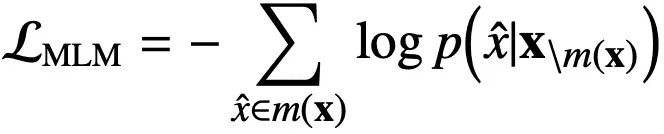
1. 学习到过于敏感而保守的分布:我们注意到,当p(x|m)趋近于零的时候,损失函数会趋近无穷大。这使得生成式模型对于稀有的样本极度敏感,并且因此使其学习到的分布变得保守
2. 目标的抽象层次低:注意到,目前的 Masked Language Model 的损失计算都是 token-level 的。然而,许多任务要求高层次的抽象理解,例如一个句子层面的语境理解。这是生成式的目标函数无法学习的
相比之下,另一个选择——判别式目标函数——长期以来被认为是无用的。这是因为,判别式模型通常不是直接拟合原有的分布流形,学习到的特征较为单一。但是,最近一些工作的基于对比学习的自监督学习框架,表现十分出色。在计算机视觉中,最出色的是 He Kaiming 组的 MoCo 和 Hinton 组的 SimCLR,取得了逼近监督学习的特征提取效果。在本届 ICLR 2020 中,也有两篇工作尝试将判别式的对比学习目标函数作为 NLP 预训练的目标,并取得了出色的成绩。
ELECTRA: Pre-training Text Encoders as Discriminators rather than Generators
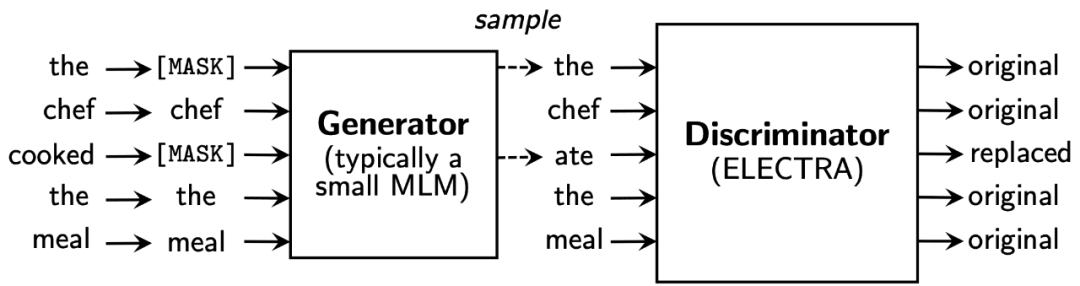
举一个例子:the chef cooked the meal(主厨烹饪了一餐饭)这个原句,经过 mask 和 generate 后,cooked 被替换为 ate,即“主厨吃了一餐饭”。虽然这个替换本身没有语法错误,但是从语境上判断,cooked 显然要和 chef 这个词关系更紧密,更符合语境。我们的目标,就是希望判别器也能学习到这些句子、乃至段落层面的语境理解,从而判断出 ate 是不恰当的替换。
值得注意的是,此处的生成器 generator 的 MLM 是一个小型的模型,而不能是 BERT 这样大参数的模型。这是因为,如果 generator 过于厉害,判别式模型就很难学好。
看到这里,我们肯定还有一个问题:从 generator 到 discriminator,这个过程是一个离散的过程,backpropagation 会被阻断!我们该怎么解决这个问题?一个常见的方法,是利用策略梯度(policy gradient),正如强化学习是如何应对反向传播阻断的。但是,策略梯度实际应用中很不稳定。ELETRA 原文中的实验也表明,策略梯度效果不佳。
1. 预热生成器(generator)模型:在 generator 上采用传统的 MLM 目标训练一定的步数
2. 训练判别器(discriminator)模型:采用生成器模型的参数对判别器进行初始化,并冻结生成器模型的参数,使用判别式目标函数训练判别器模型。
最终的目标函数可以写成: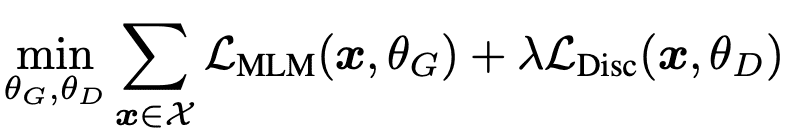
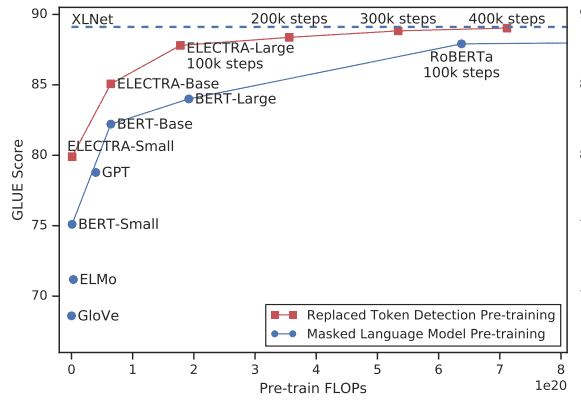
实验结果表明,ELETRA 能够在更少参数的情况下,取得和 BERT 匹敌的效果。这也充分证明了,判别式目标函数能够学习到高抽象层次的特征的同时,使用更少的参数。
本文的目标和 ELETRA 是类似的:我们希望语言模型能学习到更多高层次的抽象特征,而不仅仅是 token-level 的特征!如果我们将 ELETRA 归纳为 Replaced Token Detection(RTD)的话,这一工作(简写为 WKLM),则是采用的 Replaced Entity Detection,即利用维基百科,对 entity 进行替换,并设法让模型能够理解 entity-level 的特征。这对于许多下游任务,尤其是知识要求高的任务,如语言问答,实体提取等等是有极大的帮助的。
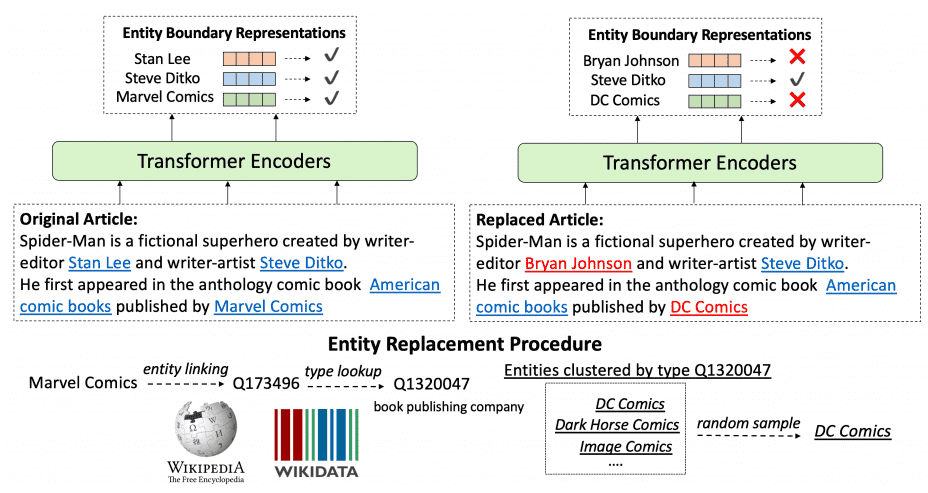
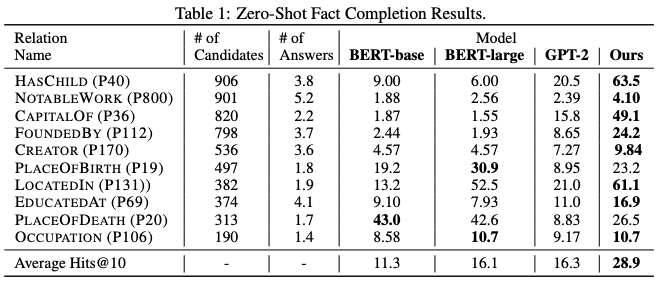
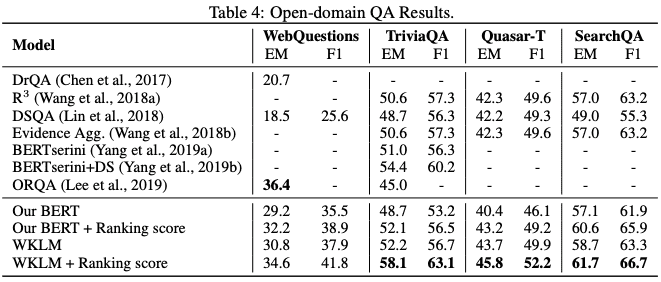
实验结果表明,WKLM 在诸多需要大量高层次知识的任务上,都取得了比传统方法高许多的表现。这也再次证明:判别式目标是值得众多自监督学习和无监督学习研究者们关注的方法,其对高层次抽象特征的学习能力值得我们关注。
近期精彩集锦(点击蓝色字体跳转阅读):
公众号对话框回复“2020科技趋势”,获取《2020科技趋势报告》完整版PDF!
公众号对话框回复“AI女神”,获取《人工智能全球最具影响力女性学者报告》完整版!
公众号对话框回复“AI10”,获取《浅谈人工智能下一个十年》主题演讲PPT!
公众号对话框回复“GNN”,获取《图神经网络及认知推理》主题演讲PPT!
公众号对话框回复“AI指数”,获取《2019人工智能指数报告》完整版PDF!
公众号对话框回复“3D视觉”,获取《3D视觉技术白皮书》完整版PDF!

点击阅读原文,一键直达 ICLR 2020 专题!




