如何应对大数据分析工程师面试Spark考察,看这一篇就够了

作者丨斌迪、HappyMint
来源丨大数据与人工智能(ID:ai-big-data)
【导读】本篇文章为大家带来spark面试指南,文内会有两种题型,问答题和代码题,题目大部分来自于网络上,有小部分是来自于工作中的总结,每个题目会给出一个参考答案。
为什么考察Spark?
为什么考察Spark?
Spark作为大数据组件中的执行引擎,具备以下优势特性。
高效性。内存计算下,Spark 比 MapReduce 快100倍。Spark使用最先进的DAG调度程序、查询优化程序和物理执行引擎,实现批量和流式数据的高性能。
易用性。Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建多样的应用。
通用性。Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。这对于企业应用来说,就可使用一个平台来进行不同的工程实现,减少了人力开发和平台部署成本。
兼容性。Spark能够跟很多开源工程兼容使用。如Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且Spark可以读取多种数据源,如HDFS、HBase、MySQL等。对于任何一家已经部署好Hadoop基础集群的企业来说,在不需要进行任何数据迁移和处理的情况下,就可以快速使用上Spark强大的数据处理和计算能力。
可以说Spark几乎是企业搭建大数据平台必备组件,作为数据分析工程师在工作中执行程序、调试程序、查询数据都会和Spark打交道,所以对Spark知识的考察也就顺理成章了。
怎么去准备Spark的面试?对于概念类的知识点可以在面试前突击一下,阅读类似本文的面试指南,对于代码类的或者涉及项目类的考题更多的是需要平时工作和学习的积累,多写一些代码并加上自己的思考。
精选考题
基本概念
1、Spark支持的编程语言有哪几种?
Spark 同时支持Scala、Python、Java 、R四种应用程序API编程接口和编程方式, 考虑到大数据处理的特性,一般会优先使用Scala进行编程。
2、Spark有什么特点,处理大数据有什么优势?
Spark为我们提供了一个全面、统一的框架,能够适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询和流处理。
Spark相比于MapReduce的运行速度提升几十到几百倍。
Spark提供了丰富的开箱即用算子工具,让开发者可以快速的用Java、Scala或Python编写程序。它本身自带了一个超过80个的高阶操作符集合。
3、Spark中Worker的主要工作是什么?
主要功能:管理当前节点内存和CPU的使用状况,接收master分配过来的资源指令,通过ExecutorRunner启动程序分配任务,worker就类似于包工头,管理分配新进程,做计算的服务,相当于process服务。
需要注意的是:
1)worker不会汇报当前信息给master,worker心跳给master只有workid,它不会发送资源信息给mater。
2)worker不会运行代码,具体运行的是Executor,worker可以运行具体appliaction写的业务逻辑代码,操作代码的节点,它不会运行程序的代码的。
4、Spark Driver的功能是什么?
答:1)一个Spark作业运行时包括一个Driver进程,也是作业的主进程,具有main函数,并且持有SparkContext的实例,是程序的人口点;2)功能:负责向集群申请资源,向master注册信息,负责作业的调度,负责作业的解析,生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
5、Spark是如何容错的?
一般来说,分布式数据集的容错性有两种方式:数据检查点和记录数据的更新。
面向大规模数据分析,数据检查点操作成本非常高,需要通过数据中心的网络连接在机器之间复制庞大的数据集,而网络带宽往往比内存带宽低得多,同时还需要消耗很多其它的存储资源。因此,Spark选择记录更新的方式。可是,假设更新粒度太细太多,那么记录更新成本也不低。故RDD仅仅支持粗粒度转换,即仅仅记录单个块上运行的单个操作,然后将创建RDD的一系列变换序列(每一个RDD都包括了他是怎样由其它RDD变换过来的以及怎样重建某一块数据的信息。因此RDD的容错机制又称“血统(Lineage)”容错)记录下来,以便恢复丢失的分区。
Lineage本质上非常相似于数据库中的重做日志(Redo Log),只是这个重做日志粒度非常大,是对全局数据做相同的重做进而恢复数据。
6、说说SparkContext和SparkSession有什么区别和联系?
SparkContext是使用Spark功能的入口点。SparkSession是Spark2.x后引入的概念。在2.x之前,对于不同的功能,需要使用不同的Context,比如
创建和操作RDD时,使用SparkContext
使用Streaming时,使用StreamingContext
使用SQL时,使用SQLContext
使用Hive时,使用HiveContext
在2.x中,为了统一上述的Context,引入SparkSession,实质上是SQLContext、HiveContext、SparkContext的组合。
7、hadoop和spark的都是并行计算,那么他们有什么相同和区别?(优势在哪里,只写区别)
两者都是用mr模型来进行并行计算,但机制不同。hadoop的一个作业称为job,job里面分为map task和reduce task,每个task都是在自己的进程中运行的,当task结束时,进程也会结束。
Spark用户提交的任务称为application,一个application中存在多个job,每触发一次action操作就会产生一个job。这些job可以并行或串行执行,每个job中有多个stage,stage是shuffle过程中DAGSchaduler通过RDD之间的依赖关系划分job而来的,每个stage里面有多个task,组成taskset,由TaskSchaduler分发到各个executor中执行,executor的生命周期是和application一样的,即使没有job运行也是存在的,所以task可以快速启动读取内存中的数据并进行计算;
hadoop的job只有map和reduce操作,表达能力比较欠缺而且在mr过程中会重复的读写hdfs,造成大量的io操作,多个job需要自己管理关系;而spark则提供了丰富的算子,可以实现常用的各种数据处理操作。
spark的迭代计算都是在内存中进行的,API中提供了大量的RDD操作如join,groupby等,而且通过DAG图可以实现良好的容错。
8、Spark有哪些组件,每个组件有什么功能?对应到什么场景?
1)Spark core:是其它组件的基础,spark的内核,主要包含:有向循环图、RDD、Lingage、Cache、broadcast等,并封装了底层通讯框架,是Spark的基础。
2)SparkStreaming:是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kafka、Flume、Twitter、Zero和TCP 套接字)进行类似Map、Reduce和Join等复杂操作,将流式计算分解成一系列短小的批处理作业。
3)Spark sql:Shark是SparkSQL的前身,Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行外部查询,同时进行更复杂的数据分析。
4)SparkR:是一个R语言包,它提供了轻量级的方式使得可以在R语言中使用Apache Spark。在Spark 1.4中,SparkR实现了分布式的dataframe,支持类似查询、过滤以及聚合的操作,但是这个可以操作大规模的数据集。
5)MLBase是Spark生态圈的一部分专注于机器学习,让机器学习的门槛更低,让一些可能并不了解机器学习的用户也能方便地使用MLbase。MLBase分为四部分:MLlib、MLI、ML Optimizer和MLRuntime。
6)GraphX用于图和图并行计算。
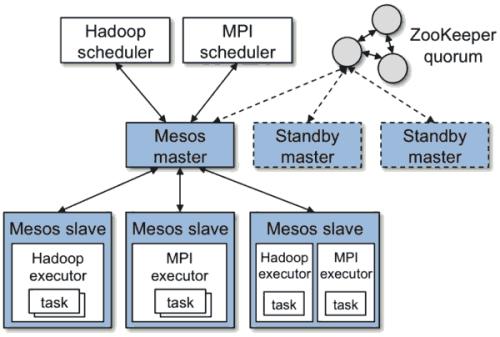
9、Spark有几种部署模式,每种模式特点?
local(本地模式):常用于本地开发测试,本地还分为local单线程和local-cluster多线程;
standalone(集群模式):典型的Master/Slave模式,Spark支持ZooKeeper来实现Master HA;
on yarn(集群模式):运行在 yarn 资源管理器框架之上,由 yarn 负责资源管理,Spark 负责任务调度和计算;
on mesos(集群模式):运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算;
on cloud(集群模式):比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon的 S3,Spark 支持多种分布式存储系统:HDFS 和 S3等。
10、spark有哪些存储级别?
1)MEMORY_ONLY:数据保存在内存中,如果内存不够,数据可能就不会持久化;
2)MEMORY_AND_DISK:数据优先保存在内存中,如果内存不够则会存到磁盘中;
3)MEMORY_ONLY_SER:和MEMORY_ONLY类似,区别是会将RDD中的数据进行序列化,这种方式更加节省内存;
4)MEMORY_AND_DISK_SER:和MEMORY_AND_DISK类似,区别是会将RDD中的数据进行序列化,这种方式更加节省内存;
5)DISK_ONLY:将数据全部写入磁盘文件中;
6)MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等:这种有后缀_2的,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。
11、RDD的优势是什么?
1)高效容错机制
RDD没有checkpoint的开销,想还原一个RDD只需要根据血缘关系就可以,而且基本不涉及分区的重计算,除非分区的数据丢失了,重算过程在不同节点并行进行,不需要将整个系统回滚。
2)数据本地性
任务能够根据数据本地性(data locality)被分配,意思是优先将任务分配到数据存储的节点,从而提高性能。
3)优雅降级 (degrade gracefully)
读取数据最快的方式当然是从内存中读取,但是当内存不足的时候,RDD会将大分区溢出存储到磁盘,也能继续提供并行计算的能力。
12、DataFrame的特性?
1)大数据量级:支持从KB到PB级的数据量
2)多种数据源:支持多种数据格式和多种存储系统
3)代码优化:通过Catalyst优化器进行先进的优化生成代码
4)通用性:通过Spark无缝集成主流大数据工具与基础设施
5)多种开发语言:API支持Python、Java、Scala和R语言。
13、RDD中关于转换(transformation)与动作(action)的区别?
transformation操作会产生新的RDD,而action不会,但是它会触发运算,将RDD上某项操作的结果返回给程序。无论发生多少次transformation操作都不会触发运算,只有action操作才会触发运算。
14、RDD中有几种依赖?有什么作用?
有窄依赖(narrowdependencies)和宽依赖(widedependencies)两种。窄依赖是指父RDD的每个分区都只被子RDD的一个分区所使用。相应的,那么宽依赖就是指父RDD的分区被多个子RDD的分区所依赖。例如,map就是一种窄依赖,而join则会导致宽依赖,主要是看有没有shuffle操作。
宽窄依赖的作用是用来划分stage。
15、rdd有几种操作类型?
1)transformation,rdd由一种转为另一种rdd;
2)action,触发具体的作业,对RDD最后取结果的一种操作
另外特殊的cache、persist,对性能效率和容错方面的支持。
16、cache和persist的区别?
它们都是用来进行缓存的。
1)cache是特定的persist,rdd中cache的缓存级别是MEMORY_ONLY,cache调用了persist;
3)persist可以设置不同的缓存级别。
ataSet?以及他们之间的区别
17、什么是RDD?什么是DataFrame?什么是DataSet?以及他们之间的区别?
RDD全称Resilient Distributed Dataset,弹性分布式数据集,它是记录的只读分区集合,是Spark的基本数据结构,见名释义:
弹性,表现在两个方面,一是当计算过程中内存不足时可刷写到磁盘等外存上,可与外存做灵活的数据交换;二是RDD使用了一种“血统”的容错机制,在结构更新和丢失后可随时根据血统进行数据模型的重建;
分布式,可分布在多台机器上进行并行计算;
数据集,一组只读的、可分区的分布式数据集合,集合内包含了多个分区,分区依照特定规则将具有相同属性的数据记录放在一起,每个分区相当于一个数据集片段。
理解了RDD,DataFrame理解起来就比较容易了,DataFrame的思想来源于Python的pandas库,RDD是一个数据集,DataFrame在RDD的基础上加了Schema(描述数据的信息,可以认为是元数据,DataFrame曾经就有个名字叫SchemaRDD)。
DataSet是DataFrame API的扩展。相较于RDD来说,DataSet提供了强类型支持,区别也是给RDD的每行数据加了类型约束。
共同点
RDD、DataFrame、DataSet全都是Spark平台下的分布式弹性数据集,为处理超大型数据提供便利。
三者都有惰性机制,在进行创建、转换等阶段,如map、filter等方法时,不会立即执行,只有在遇到Action如count、collect等时,才会真正开始运算。
三者都会根据Spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出。
三者有许多共同的函数,如filter、map等。
不同点
RDD不支持Sparksql操作,DataFrame与DataSet均支持Sparksql,比如select,groupby之类,还能注册临时表/视图,实现与sql语句的无缝操作。
DataSet和DataFrame拥有完全相同的成员函数,区别在于每一行的数据类型和字段类型是否明确。DataFrame也可以叫DataSet[Row],每一行的类型为Row,而DataSet每一行的数据类型是确定的。DataFrame只知道字段,但无法确定字段的具体类型,所以在执行这些操作的时候是没办法在编译的时候检查类型是否匹配的,比如你可以对一个String进行减法操作,在执行的时候才会报错,而DataSet不仅仅知道字段,还知道字段类型,所以有更严格的错误检查。
相比于RDD,DataFrame与DataSet支持一些特别方便的保存方式,比如保存成csv,且可以带上表头,这样每一列的字段名一目了然。
18、什么是广播变量?
广播变量允许开发人员在每个节点缓存只读的变量,而不是在任务之间传递这些变量。实际工作中,当我们需要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的内存资源,如果将这个变量声明为广播变量,那么只是每个Executor拥有一份,这个Executor启动的task会共享这个变量,从而节省了通信的成本和内存资源。
使用广播变量的注意事项:
广播变量只能在Driver端定义,不能在Executor端定义。
在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
不能将一个RDD使用广播变量广播出去,因为RDD是不存储数据的。可以将RDD在Driver端collect为一个集合再广播出去。
被广播的对象必须实现序列化。
19、什么是累加器?
在数据分析工作中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会在Driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式累加的功能。
我们可以通过分别调用SparkContext.longAccumulator()或SparkContext.doubleAccumulator() 累积Long或Double类型的值来创建数字累加器。然后,可以使用add方法对累加器进行增加。驱动程序可以使用其value方法读取累加器的值。
使用累加器的注意事项:
累加器在Driver端定义赋初始值,且只能在Driver端读取最后的值,在Excutor端更新。
在Driver端获取累计器值的时候需要一个Action操作来触发,才能拿到值。
累计器只能执行add操作。
20、rdd的弹性表现在哪几点?
自动进行内存和磁盘切换;
基于lineage的高效容错;
task如果失败会执行特定次数的重试,而且只计算失败的分片;
具备checkpoint(每次对RDD操作都会产生新的RDD,如果链条比较长,计算比较笨重,就把数据放在硬盘中)和persist (内存或磁盘中对数据进行复用)(检查点、持久化)特性;
数据调度弹性;
数据分片的高度弹性repartition。
基本操作
21、如何创建一个RDD?DataFrame?DataSet?
1)创建RDD
第一种在集合创建RDD,RDD的数据源是程序中的集合,通过parallelize或者makeRDD将集合转化为 RDD。
val num = Array(1,2,3,4,5)val rdd = sc.parallelize(num)//或者val rdd = sc.makeRDD(num)
第二种使用本地文件、HDFS创建RDD,RDD的数据源是本地文件系统或HDFS的数据,使用 textFile 方法创建RDD。
val rdd = sc.textFile("hdfs://hans/data_warehouse/test/data")2)创建DataFrame
DataFrame可以通过已存在的RDD进行转换生成或者直接读取结构化的文件(如json)生成DataFrame。
val df = spark.read.json("/data/tmp/SparkSQL/people.json")3)创建DataSet
可以使用case class创建DataSet,也可以将DataFrame转换成DataSet。
case class Person(name: String, age: Long)
// 通过case class创建DataSet
val caseClassDS = Seq(Person("Andy", 32)).toDS()// 将DataFrame转换成DataSetval path = "examples/src/main/resources/people.json"val peopleDS = spark.read.json(path).as[Person]
22、如何获取RDD?RDD的创建有哪些方式?
1).使用程序中的集合创建rdd;
2).使用本地文件系统创建rdd;
3).使用hdfs创建rdd;
4).基于数据库db创建rdd;
5).基于Nosql创建rdd,如hbase;
6).基于s3创建rdd;
7).基于数据流,如socket创建rdd;
23、map与flatMap的区别
map操作会对RDD中每条记录做处理,返回的是处理后的记录,记录数不变,而flatMap操作在map的基础上,将处理后的集合进行平展,并且会抛弃null值。
24、哪些代码在driver上执行,哪些代码在executor上执行?
概括来说,driver执行的就是main方法中除了RDD算子中的代码块以外的所有代码块,并且只执行一次。Spark的每个batch在执行的时候先执行driver中的代码,然后遇到action操作再去划分DAG图,将具体执行算子分发到各个executor上执行。
25、Spark配置的优先级?
通过SparkConf 对象配置的属性优先级最高;其次是提交作业时传入的命令行参数配置;最后是spark-defaults.conf文件中的默认配置。
26、哪些算子会产生shuffle。
去重:distinct
聚合:reduceByKey、groupBy、groupByKey、aggregateByKey、combineByKey
排序:sortByKey、sortBy
重分区:repartition、coalesce(增大分区数时)
集合或者表操作:intersection、subtract、subtractByKey、join、leftOuterJoin
27、Spark streaming 读取kafka数据的两种方式?
1.基于Receiver方式
需要使用单独的Receiver线程来异步获取Kafka数据。Spark Streaming启动时,会在Executor中同时启动Receiver异步线程用于从Kafka持续获取数据,获取的数据先存储在Receiver中(存储方式由StorageLevel决定),后续,当Batch Job触发后,这些数据会被转移到剩下的Executor中被处理。处理完毕后,Receiver会自动更新Zookeeper中的Offset。
2.基于Direct(No Receiver)方式
不需要使用单独的Receiver线程从Kafka获取数据。Spark Streaming Batch Job触发时,Driver端确定要读取的Topic-Partition的OffsetRange,然后由Executor并行从Kafka各Partition读取数据并计算。
执行过程
28、为什么要进行序列化?
序列化可以对数据进行压缩减少数据的存储空间和传输速度,但是数据在使用时需要进行反序列化,比较消耗CPU资源。
29、Spark如何提交程序执行?有哪些提交方式?
提交一个Spark任务使用spark-submit,加上相关的参数和主jar包进行提交。常用的参数如下:
master:指定Spark的master的IP和端口;
deploy-mode:Driver 程序运行的地方,client 或者 cluster,默认是client;
class:主类的路径;
jars:Driver 和 executor 依赖的第三方jar包,多个jar包使用逗号分隔;
spark-submit --master spark://node001:7077,node002:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar 1000030、Spark在提交程序的时候如何引入外部jar包?
有两种方法可以引入:
1)spark-submit --jars
在提交任务的时候指定--jars,用逗号分开。缺点是每次都要指定jar包,如果jar包少的话可以这么做,但是如果多的话会很麻烦。
命令:spark-submit --master yarn-client --jars xxx.jar,yyy.jar
2)extraClassPath
在spark-default中设定参数,将所有需要的jar包拷贝到一个文件夹里,然后在参数中指定该目录就可以了。
//参数
spark.executor.extraClassPath=/home/hadoop/work/lib/*spark.driver.extraClassPath=/home/hadoop/work/lib/*
31、RDD中reduceBykey与groupByKey哪个性能好,为什么?
reduceByKey会在结果发送至reducer之前对每个mapper在本地进行merge,有点类似于在MapReduce中的combiner。这样做的好处在于,在map端进行一次reduce之后,数据量会大幅度减小,从而减小传输,保证reduce端能够更快的进行结果计算。
groupByKey会对每一个RDD中的value值进行聚合形成一个序列(Iterator),此操作发生在reduce端,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。
所以相比之下reduceBykey的性能更好。
32、Spark为什么要持久化,一般什么场景下要进行persist操作?
持久化的目的是为了避免重算和提高效率。rdd出错后可以根据血统信息进行还原,如果没有对父rdd进行持久化操作就需要从源头重新计算;还有一种场景是某个rdd被重复使用,而这个rdd的生成的代价也不小,为了提高计算效率可以将这个rdd进行持久化操作,这样提高后续的计算效率。以下场景需要进行persist操作:
1)计算链条很长,一旦失败重新恢复代价太大;
2)计算复杂耗时长,避免重新计算;
3)checkpoint所在的rdd要进行persist;
4)比较大的shuffle之后最好做persist避免再次shuffle;
33、join操作如何优化?
1)对于大小表join的时候,使用map-side join替换join;
2)在join之前对表进行筛选,减少join的数据量
3)避免出现笛卡尔积,关联字段最好不要有重复的值,可以在join之前做去重处理。
4)某些场景下可以把join后聚合,优化为聚合后再join,减少join数据量
34、Spark性能优化主要有哪些手段?
1. 开发调优
- 避免创建重复的RDD
- 尽可能复用同一个RDD
- 对多次使用的RDD进行持久化
- 尽量避免使用shuffle类算子
- 使用map-side预聚合的shuffle操作
- 使用高性能的算子
- 广播大变量
- 使用Kryo优化序列化性能
- 优化数据结构
2. 资源参数调优
- executor内存和数量配置
- driver内存配置
- 并行度配置
- 数据本地化
- JVM/gc配置
35、Spark如何防止内存溢出?
1.driver端的内存溢出
可以增大driver的内存参数:spark.driver.memory (default 1g);
2.map过程产生大量对象导致内存溢出
这种溢出的原因是在单个map中产生了大量的对象导致的,针对这种问题,在不增加内存的情况下,可以通过减少每个Task的大小,以便达到每个Task即使产生大量的对象Executor的内存也能够装得下。具体做法可以在会产生大量对象的map操作之前调用repartition方法,分区成更小的块传入map。
3.数据不平衡导致内存溢出
数据不平衡除了有可能导致内存溢出外,也有可能导致性能的问题,解决方法和上面说的类似,就是调用repartition重新分区。
4.shuffle后内存溢出
shuffle内存溢出的情况基本可以说都是shuffle后,单个文件过大导致的。在Spark中,join,reduceByKey这一类的过程,都会有shuffle的过程,在shuffle的使用,需要传入一个partitioner,大部分Spark中的shuffle操作,默认的partitioner都是HashPatitioner,默认值是父RDD中最大的分区数,这个参数通过spark.default.parallelism控制(在spark-sql中用spark.sql.shuffle.partitions) ,如果是别的partitioner导致的shuffle内存溢出,就需要从partitioner的代码增加partitions的数量。
5.standalone模式下资源分配不均匀导致内存溢出
在standalone的模式下如果配置了--total-executor-cores 和 --executor-memory 这两个参数,但是没有配置--executor-cores这个参数的话,就有可能导致,每个Executor的memory是一样的,但是cores的数量不同,那么在cores数量多的Executor中,由于能够同时执行多个Task,就容易导致内存溢出的情况。这种情况的解决方法就是同时配置--executor-cores或者spark.executor.cores参数,确保Executor资源分配均匀。
6.使用rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)代替rdd.cache()
rdd.cache()和rdd.persist(Storage.MEMORY_ONLY)是等价的,在内存不足的时候rdd.cache()的数据会丢失,再次使用的时候会重算,而rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)在内存不足的时候会存储在磁盘,避免重算,只是消耗点IO时间。
36、对于Spark中的数据倾斜问题你有什么好的方案?
通过WebUI或者具体执行机器的日志进行问题定位,是OOM还是执行缓慢。
可以从以下几个方面优化数据倾斜问题:
1)避免不必要的shuffle,如使用广播小表的方式,将reduce-side-join提升为map-side-join
2)处理异常值,如null值和空字符串
3)提高shuffle并行度,可能并行度太少了,导致个别task数据压力大
4)分阶段聚合,先局部聚合,再全局聚合
5)自定义paritioner,分散key的分布,使其更加均匀
程序题
37、如何使用Spark解决TopN问题?
假设这样的场景,我们有一张10个产品线URL的访问记录表,有两个字段:product、url,请模拟1000条数据然后统计各个产品线下访问次数前3的URL。
import org.apache.spark.SparkConfimport org.apache.spark.sql.SparkSessionimport scala.util.Random//初始化环境val config = new SparkConf()config.setMaster("local[2]")va spark = SparkSession.builder().config(config).getOrCreate()//模拟数据var data: List[String] = Nilfor (i <- 1 to 1000)data = data ::: "procuct" + Random.nextInt(10).toString + " url" + Random.nextInt(100).toString :: Nilimport spark.implicits._val rdd = spark.sparkContext.parallelize(data)val df = rdd.map(_.split(" "))//按照空格进行分割.map(row =>((row(0),row(1)),1)).reduceByKey(_+_)//将相同产品线和url聚合后求出访问次数.map(row => (row._1._1,(row._1._2,row._2)))//将产品线作为key.groupByKey().map(row => {val result =row._2.toList.sortBy(-_._2)//按照访问次数进行倒序排序.map(_._1).take(3)//取出前三个url(row._1,result)//返回结果})df.foreach(println)//执行结果(procuct5,List(url55, url85, url74))(procuct8,List(url80, url91, url95))(procuct6,List(url96, url25, url7))(procuct2,List(url67, url36, url35))(procuct7,List(url80, url93, url94))(procuct4,List(url99, url57, url98))(procuct1,List(url81, url68, url37))(procuct0,List(url14, url64, url86))(procuct3,List(url80, url28, url15))(procuct9,List(url44, url65, url34))
小结
本篇Spark面试指南,结合网络上的经典考题和工作中总结改编的题目一共37道,基本涉及了数据分析工作中常用的知识点,有概念类的也有操作类的,希望读者可以查漏补缺,完善Spark面试知识点。
参考文献
[1] 总结 | 最全的Spark基础知识解答,作者:aaronhoho - https://www.jianshu.com/p/03a0e267c24b
[2] Spark知识点总结,作者:身为风帆,要顺其自然 - https://blog.csdn.net/qq_33247435/article/details/83653584
[3] spark相关的面试题跟答案,作者:wangxiaojian - http://www.aboutyun.com/?mod=viewthread&action=printable&tid=24246
[4] Spark Worker内部工作原理,作者:张章章Sam https://blog.csdn.net/qq_16103331/article/details/53421002
[5] spark 如何防止内存溢出,作者:老子天下最美Samhttps://blog.csdn.net/Sunshine_2211468152/article/details/83050337
[6] Spark学习—— (4+) SparkSparkContext与SparkSession,作者:zhierzyc https://blog.csdn.net/qq_36153312/article/details/98963236
[7] Spark Streaming读取Kafka数据的两种方式,作者:wangpei1949 https://blog.csdn.net/wangpei1949/article/details/89419691
[8] RDD有哪几种创建方式,作者:weixin_33834075 https://blog.csdn.net/weixin_33834075/article/details/91731892
[9] 宽依赖与窄依赖,作者:05rjyzl11 https://www.iteye.com/blog/yangzhonglei-2433091
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!


推荐阅读
AI换脸软件ZAO刷屏,可我却不敢用了
只给测试集不给训练集,要怎么做自己的物体检测器?
还在抱怨pandas运行速度慢?这几个方法会颠覆你的看法
没有光芯片,何谈 5G 与 AI !
30 岁的程序员,我没有活成理想的模样,失败吗?
看懂“大数据”,这一篇就够了!
别让分析公司卖了你:一文读懂比特币的私密性及隐私保护