毕彦超:物体识别与物体知识表征的认知神经基础| VALSE2017之八
点击上方“深度学习大讲堂”可订阅哦!
编者按:大脑是一个神奇的存在,它定义了你是谁,它赋予了你认知,它决定了你理解这个世界的方式。如果能够理解人脑的认知机制,理解从人脑的角度如何加工物体,将有助于加深理解神经网络。今天,脑认知神经领域专家,毕业于哈佛大学的毕彦超教授,将带给大家物体识别及物体知识表征域的认知神经基础。文末,大讲堂特别提供文中提到所有文章的下载链接。


人脑识别 = 如何识别 + 人脑的正确反应
机器视觉对这些图片识别正确率已经非常高了。而对于人脑来说我们关心的不仅仅是识别率,特别关心的人脑特征是:怎么识别,识别的目的是什么。在人看到这些图片时,识别同时伴随的是人脑产生对它的正确反应。
举几个栗子

在图中,我们看到左边的草莓,判断是要吃它;看到第二张中的锤子是要用它,抓起来锤东西;见到第三张里的蛇,会意识到有危险要规避它;最后一个人看起来比较亲切想去握手或者拥抱。
关于这几个栗子
那么大家想一想:如果你要去拿起来第三张里的蛇,觉得是个长的想要用它,把它当成绳子去用?或者拥抱第二个东西,甚至第三个东西,大家认为这是当然是不可能的事情。
这个例子说明:对于人脑识别物体其实是伴随着去提取它存储的非视觉的语义信息,然后做出相应的反应,以适应于人的生存。

人脑中先验知识的重要性
1. 再举个栗子

首先跟大家介绍个我们和华山医院郭起浩医生合作过的病人案例:这个病人原来是大学俄语系教授,后来下海经商,人非常聪明。他太太带他过来看病,说这个人有些糊涂。表现是:让他买苹果,他买回来香蕉;让他买茄子,他买回来西红柿。我们给他做了神经心理测查:给他看鹿的图片问他这是什么?他说:“这是一个动物吧,我们家附近老有,经常陪我买菜。” 他们家住在上海静安区,绝对没有这种动物陪他逛街。左图是他照着画的图,右边是给他名字让他凭记忆画的图。他记忆中动物的样子都是一个脑袋、四条腿、一条尾巴。
2. 还是这个栗子
这种病非常少见,是一个很典型的语义痴呆案例。随着从大脑颞叶前部逐步扩散的萎缩,他慢慢失去对客观世界各种语义知识的记忆。所以及时他的视觉和听觉感知系统没有问题,但仍然伴随着不能够正确识别这些物体,不能够听懂别人的语言,以及不能正确使用一些场景中的工具。在晚期或者有一种”失用症“的病人,失去物体使用的知识,给他梳子他会当作叉子来用。
3. 结论
所以这个例子表明,我们完整物体识别过程其实是非常依赖我们大脑中存储的相关知识。

那么,我们大脑中存储的什么样的知识呢?
对于左上这个图形,投射到我们视网膜上仅仅是特别简单的线条、明暗的对比,但我们知道这个东西背后长什么样子,它会发出什么样的声音,它在什么地方出现,对我们人有什么功能,还有特定的人会给它的标签,抽象的特征比如说它很可靠,很忠厚,很强壮等等。我们大脑是如何存储这些知识,而这些知识的存储是如何影响我们去识别物体呢?
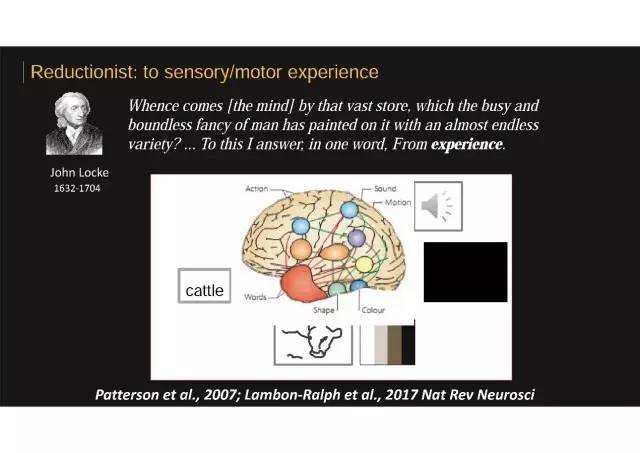
目前主流理论:大脑中丰富的信息源自于经验
在出现磁共振技术后,我们可以在活体上看人大脑的反应,促使了认知神经科学的诞生。认知神经科学一个主要进展之一,就是我们对知识表征的脑基础有了一定理解。
1. 经验主义哲学理论
关于知识表征有很多不同的哲学思潮。比如哲学家洛克,几百年前关于如何实现“busy and boundless fancy of man”-大脑中如何有这么丰富的信息--“To this I answer, in one word ,from experience”。提出这些知识来自于我们实际的经验,我们看它的经验,去摸它的经验,感受它的经验。
2. 经验主义对知识表征的解释
这种经验主义理论把一个基本物体的知识,比如关于它视觉的知识,它长什么样子,它有什么颜色,它会发出什么样的动作,就来源于我们以前不断看它的经验,而相应存储在视觉皮层相关感知觉经验模式区域。而它会发出什么样的声音的知识来源于我们以前听它的经验。
大脑中不同的区域与认知的关系
为什么这种经验主义理论在认知神经科学的知识概念表征研究中受到如此主流的认可?
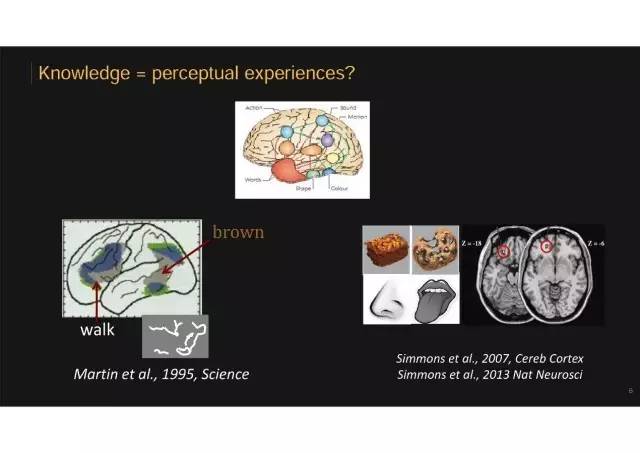
一方面是我们大脑本来已经有现成的感知觉经验生理基础,比如我们有视觉系统,听觉系统,有相关的神经元分别对视觉信号和听觉信号反应。最早看语义信息加工的功能影像经典研究之一,发表在Science,让人在磁共振机器中看到物体时回答它一些不同方面的问题,比如听到牛这个词或看到这个黑白线条图,分别让被试者去想,它有什么样的颜色,它会发生什么样的动作?被试者需要想它是棕色,或者它耕地会走路。
大家会发现对于同一个物体,在回答不同问题时,会激活不同的大脑区域。
1. 颜色与梭状回和舌回区域:回答颜色问题时候所激活的区域是梭状回和舌回,它是用于大脑加工颜色的脑区。
2. 动作与额叶区域:回答动作问题的时候会发现额叶区域被激活,这些区域在人们观察动作和实际做动作时候也会激活。
3. 味觉与脑岛区域:人们看到好吃东西的图片和看一些桌子椅子比较无味的图片进行比较,好吃东西的图片会更强激活脑岛,包含味觉加工的区域。
这些实验结果直观地表明,人在看一个物体的时候,不仅仅是分析视觉特征,同时还会伴随着非常多其他方面信息的提取和推论。
以上是物体语义知识脑基础的主流理论所做的介绍,即分布存储在不同经验的表征当中。我们自己对这个理论框架的近年思索集中在两个我认为核心的问题:
某个特定方面知识与实际经验之间的关系。此处将以视觉皮层为例去看物体视觉识别经验与视觉方面知识之间的关系
脑结构和功能连接对物体识别的作用
关于简单的物体,它不同方面的知识,需要多个不同脑区共同参与,它是如何组合在一起来表示同一个物体的。而这种组合方式在识别物体过程中有什么样的影响。
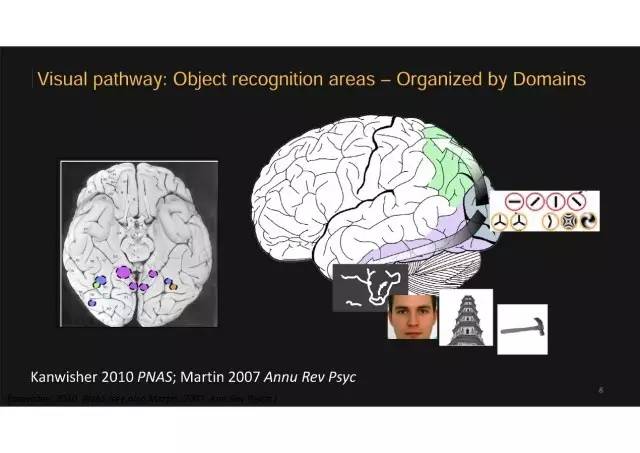
腹侧视觉通路:脑中用于识别物体的区域
切入到人的大脑视觉皮层,我们视觉通路上,有腹侧-ventral和背侧-dorsal 通路。其中腹侧皮层(ventral pathway)是识别物体的主要通路。
视觉皮层经典发现是它具有层级结构:
一、初级视觉皮层是识别特别简单的视觉特征,比如说:朝向、颜色。
二、而高级视觉皮层就是以物体为单元。过去二十年对人和灵长类动物高级视觉皮层研究的一个很重要发现就是物体类别组织,用不同的区域来处理不同的物体信息:
处理场景信息:左侧图上淡紫色的圆形区域,用于处理场景信息,人看到某个地方或者某个场景时,这个地方会激活特别强烈;
处理面孔信息:蓝色的区域是处理面孔,看到面孔时就激活很强。还有附近的区域对动物的图片特别敏感、另一个区域对文字特别敏感;
处理工具信息:还有偏外侧一处对工具图片特别敏感。
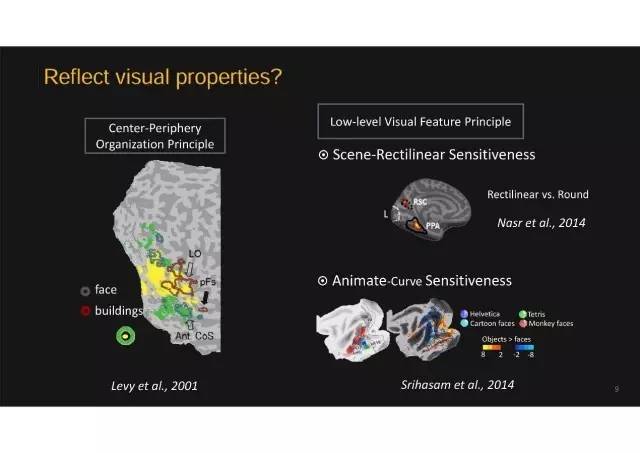
为什么大脑的高级视觉皮层按照这个物体类别纬度进行组织?
这是争论非常多的一个问题。目前比较主流的一种思想是从多种类型的(自下而上)视觉特征去分析这个问题。比如:
一、 不同类别物体的视野特征是不一样的
比如人看面孔的时候,经常落在视野中心,而看场景的时候是外周视野参与很多,视觉地图中这些不同位置信息会投射到高级皮层不同区域;
二、动物类物体有更多的曲线而场景类有更多的直线
比如2014年Livingstone组的一篇文章通过灵长类动物皮层单细胞电信号记录发现,学习新的视觉符号如果含有弯曲线条会引起特定脑区神经元放电,可能解释对动物类型的喜好。这些理论假设的共性就是不同物体类别的脑区分布基础是由于不同视觉特征所引起的。
从盲人实验看视觉经验对物体识别的作用
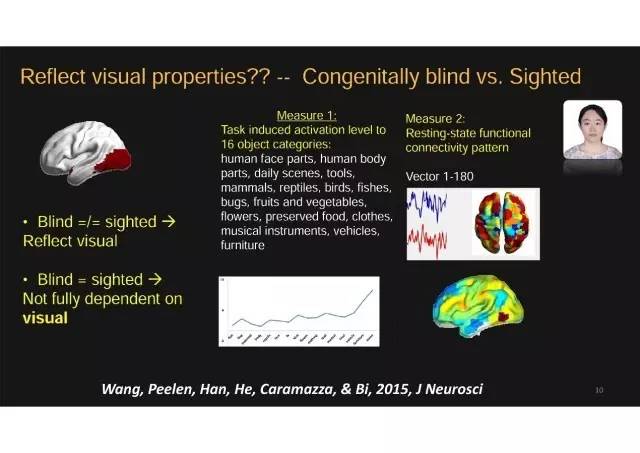
我们课题组近年做了一系列研究工作,从另外一个极端去思考这个问题。我们特别关注先天盲人的情况。研究先天盲人可以非常直接地检验视觉经验的作用。如果是视觉的特征去驱动物体分类,先天盲人从来没有过视觉经验、从来没有从视觉上分析过物体,他/她的情况会是什么样子呢?
我们在一系列实验中检验了先天盲人在这个脑区对物体反应的模式。王效莹博士等人这篇研究是最为系统的一篇,对整个腹侧视觉皮层我们从两个方面去观测每一个体素的情况。磁共振扫描并不能看到单个神经元的活动,我们可以看到的是2*2*2或3*3*3毫米的一个脑区单元上的活动强度或者模式。
对每个体素,我们选用两种指标:
一方面去看对不同类别物体的反应模式:我们让受试者去看很多不同类型物体的图片(控制组)或听他们的名字(盲人组、控制组都做),比如人脸的不同器官、不同类型的动物、不同类型的工具,不同类型的场景等等。我们会获得每个体素对这些类别物体的反应强度,作为它的类别反应模式,可以看成一种功能反应指纹(functional fingerprints);
另一方面测量大脑自发特点,寻找体素与大脑的连接模式:人们在不做任何任务时候大脑的反应并不是随机的或静态的,而是有一定的自发活动模式。我们可以去测量这种大脑自发特点,把每个体素与大脑其他地方的连接模式,看跟谁的连接更强,作为它的连接指纹(connectional fingerprints)。
如何应用这两种指标:对这两种指标,我们比较先天盲人和控制组在每个体素是像还是不像。思路很简单:
-
如果一个地方的特点完全是靠视觉驱动的,先天盲人和正常人应该表现不一样;
-
而如果并不完全靠视觉驱动,由其他因素决定,就有可能他们是一致的。
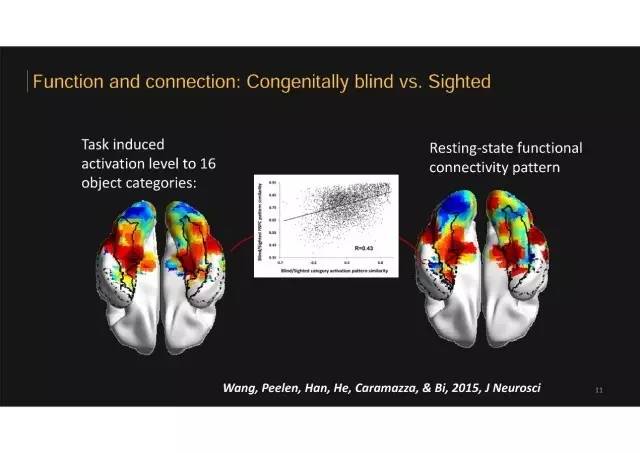
从模式图谱看先天盲人与普通人控制组的异同
所以在这个实验当中,我们获得了两个大的图谱,反映先天盲人和控制组相似性的情况。
任务反应模式图谱:左边是任务反应模式图谱,计算的是每个被试者看到或者听到不同类别的物体图片或名字,他/她的反应模式是什么样子。
连接模式图谱:右边是连接模式图谱。
图谱上颜色深浅来表示相似程度。
最红色的表示先天盲人和正常人相似程度非常高、几乎无法区分;
而最蓝色的地方,表示先天盲人和正常人的情况非常不同。
图中所示是从腹侧(就是大脑底部)往上看的视角,头的最后边,是初级视觉皮层,可以看到:
-
初级视觉皮层盲人有很强的重组,即没有视觉输入经验造成这部分脑区的功能和连接模式都发生了改变;
-
而往前的部分是盲人和正常人比较一致,相对独立于视觉经验的影响。
我们仔细去看这个图内部,会发现其实所谓的高级视觉皮层,比如黑色的中间框出来的梭状回,是客体识别的经典脑枢,有很多不同的情况,有的地方在两组被试中像、有的地方不像。为什么呢?
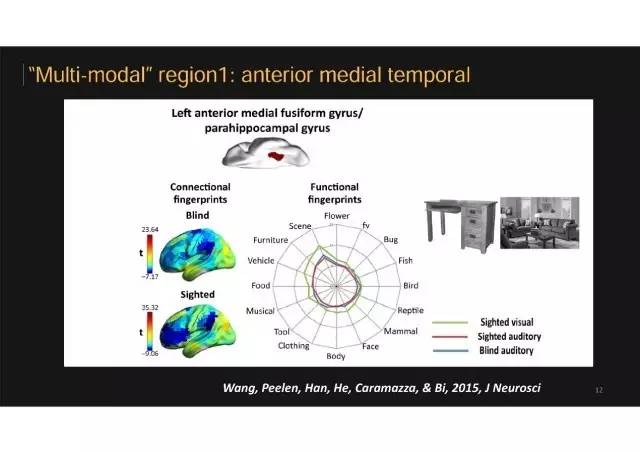
盲人 VS 普通人:相似脑区1
我们取出来几个极端的脑区进一步看它们的特点。图中给出了某一盲人和正常人模式相同的脑区,用不同颜色的线来区分人群及给予的刺激。
蓝色的线,是盲人听见物体名字的数据结果。
-
绿色的线,是普通人看图片的数据。
-
红色的线,普通人听见物体名字的数据结果。
盲人和正常人实验中,这个脑区都喜欢这几类物体——场景、家具、大的东西,还有交通工具。这个脑区与其他脑区连接模式在不同人群中也非常相似,都与一些参与空间导航的脑区连接更强。
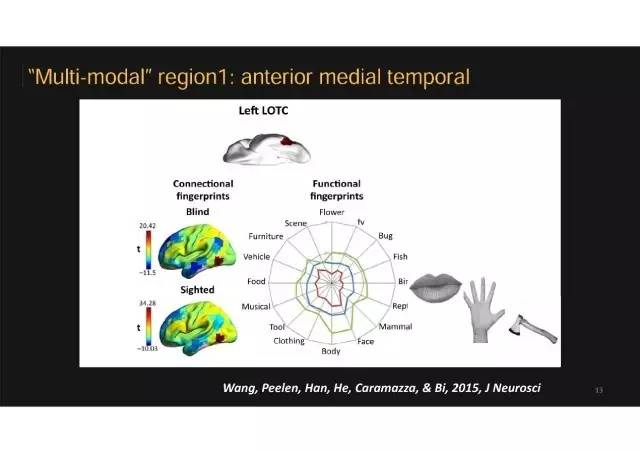
盲人 VS 普通人:相似的脑区2
上图给出了另外一个盲人和正常人特别相似的脑区。盲人和正常人的这个脑区都特别喜欢工具和身体组成部分,比如手臂、腿,看到这些图片或者听到它们的名字就激活更强。在静息状态下,这个脑区与额顶网络,这些脑区被发现参与加工人的动作。
一个推测
所以我们推测,这个脑区可能喜欢的涉及人的动作、肢体运动的信息。而工具的重要信息是对它进行操作和使用。
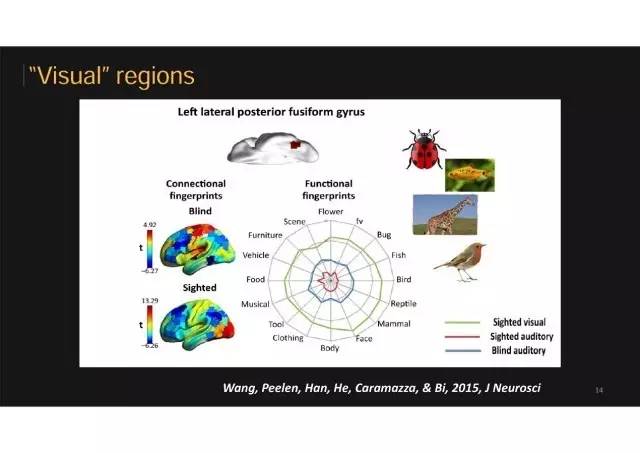
盲人 VS 普通人:视觉区域的不同
另外一个极端的脑区是正常人和盲人最不一样的地方。这个脑区,在正常人看图片时候特别喜欢所有的动物,包括哺乳动物、昆虫、鱼、鸟、爬行动物等等。正常人看到动物的图片这个脑区激活就非常强。但是盲人和正常人在听词的时候就完全没有这种偏好。就是说这个地方对动物图片特异性信号是完全靠图片的视觉特征驱动的。
带给我们的困惑
这个结果让我们困惑了很长时间。因为如果这种物体识别脑区的机制是完全应该靠视觉特征驱动,盲人就不应该有同样的模式;而如果认为这些脑区比较抽象和高级,加工物体的某些抽象特征,盲人和正常人应该相似。
而为什么我们发现对某些物体类别图片偏好的脑区相似,有些类别的脑区不相似呢?为什么针对动物的脑区,特别依赖于视觉呢?

动物 VS人造物:不同的进化意义和角色
我们最近两年有一个思路跟大家分享。人作为主体识别加工物体脑机制,与人的进化过程应该是非常相关的。不同类型的物体有很不同的进化意义。我们看到动物的图片和人造物的图片时候会有很多种不一样的推论和目的:
看到动物:动物的形状,它长什么样子我们人只能被动的接受。我们没有办法决定一个恐龙长什么样子,一个鱼长什么样子。我们只能去适应它,去学习它、去识别它。
看到人造物:但是人造物的出现是完全不一样的。人造物完全是人进化过程的产物。一个凳子它是这个样子,是因为我们人把它做成了这个样子,使得人可以去坐它;一个书包长什么样子,是因为我们人把它做成这个样子,使得它可以装东西;帽子是这个样子,是因为我们人把它做成这个样子,使得人可以去戴帽子。
所以这种人造物的形状本身就已经对应了我们想要使用它,识别它的目的。
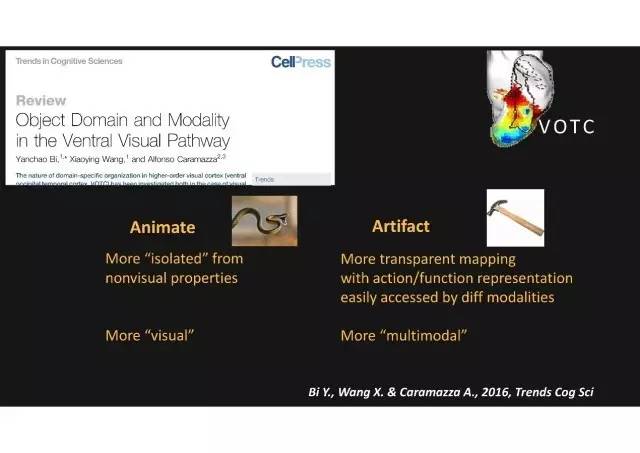
动物 VS人造物
这是去年我们发表的一篇理论综述文章对这个思路进行阐述:
-
识别动物:之所以对动物识别的脑区特点如此依赖视觉输入,是因为人去加工它的视觉输入跟对它的合适反应,是一个应该怎么适应接受的状态。
-
识别人造物:对于人造物来说,在进化过程当中,它的形状、人对它的反应和它的操作方法和功能是有直接的对应。工具创造和使用的进化过程可能对人大脑有很强的塑造。
一个演化小细节
人和其他灵长类动物一个重要区分时机,是从旧石器时代到新石器时代的演化过程。复杂工具的使用和发展伴随了人大脑的飞速发展、在这个时代过程中大脑体积迅猛增加,人们推测增加为三倍(tripled)。因此可能发展出来处理这种与操作方式和功能对应关系的人造物形状加工机制,以可以直接转化成我们对其非视觉特性的理解。所以加工人造物形状的脑区与非视觉特征有更好对应,使得通过视觉还是通过触觉或者其他感觉通道输入没有特别大的影响。
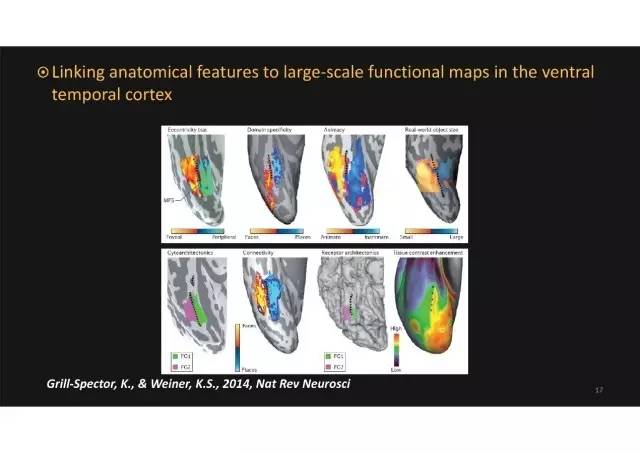
大脑皮层生理解剖特征与功能之间的联系
从大脑本身解剖特点来看,我们看下梭状回(Fusiform gyrus)这个物体识别的重要脑区。这个脑区以一个沟分成内侧和外侧。如刚才所介绍,已经非常多的研究发现,功能上内外侧有区别--外侧喜欢动物类,内侧是喜欢人造物和场景。同时,这两部分细胞的种类、构筑方式、连接模式都有区别。可能我们把不同物体放在这两类不同区域去处理,是因为他们不同类型的神经元适合处理不同的信息。也有可能反过来我们因为进化的需要发展出来这种不同的视觉子系统,专门去处理需要我们有不同反应的物体。

盲人VS 普通人:针对人造物的相似反应背后的原因
我们以特殊群体作为研究对象有一个经典问题:虽然发现了对于这种人造物先天盲人和正常人的反应是相似的,但是怎么知道它是因为同样的原因相似呢?会不会可能在盲人大脑里它有其他特点,但表现出同样的测试结果?所以我们在另外一个研究中更直接检验是否在两种人群种是在处理同样的信息表征。我们找了一些很常见的人造物材料,是盲人和正常人都比较熟悉的,然后专门去看相关脑区是对这些物体那些方面进行加工。
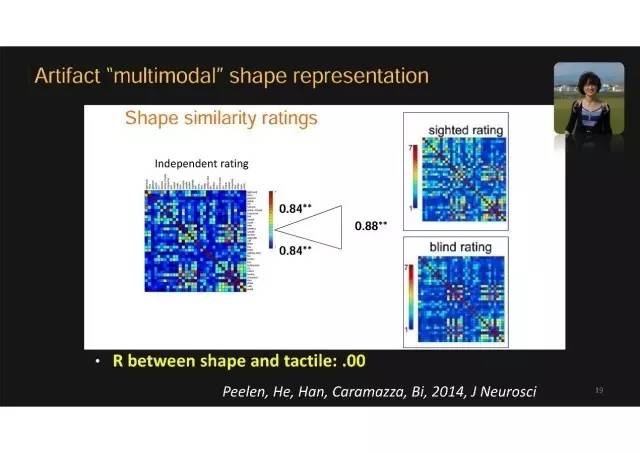
针对人造物相似反应的实验
在实验中我们首先让被试者去评定这些物体的形状特点。我们一共有33个物体材料,被试需要对每一对评在形状上有多么相似。这样我们可以形成一个33x33的矩阵,这个矩阵反映了他这些物体形状知识的表征空间。图上面是正常人对照组的物体形状表征空间、下面是先天盲人评定的物体形状表征空间。
有趣的行为结果
我们第一个有趣结果就是这两个空间是非常相似的。也就是说先天盲人虽然从来没有看到过这个东西,但是通过触摸或者其他渠道学习,对这个东西长什么样子的感觉跟大家是一样的。
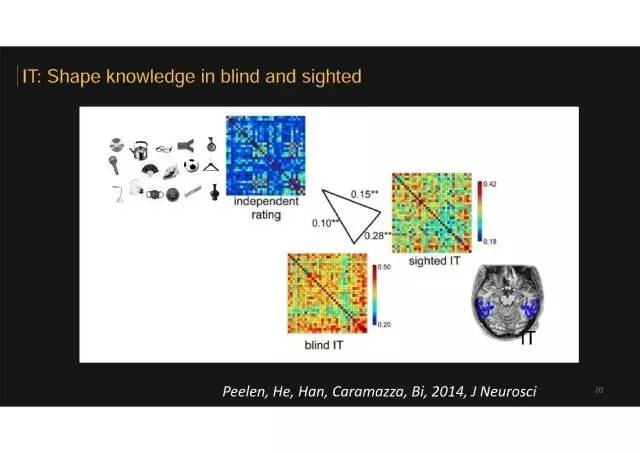
盲人 VS 普通人:如何识别形状
同样的方法我们也可以应用到大脑数据分析上。右边红色矩阵反映出来33个物体每两个之间在腹侧颞叶皮层(inferior temporal)反应模式的相似性,构建出一个33x33的矩阵,这就是神经反应模式空间。每个物体的神经活动模式我们是通过把颞枕皮层(右下角)所有体素的激活强度分布特点来计算的。我们把大脑高级视觉皮层的物体神经反应模式矩阵,与行为上的特定特征矩阵做相关,就可以推测这个脑区神经活动表征这种特征的程度。这种分析方法叫神经表征形似性分析方法,可以用来推测大脑所表征的信息内容。这个分析结果是先天盲人和普通人腹侧颞枕皮层的神经活动模式矩阵与物体形状矩阵都有显著相关。
又举个栗子具体解释下

左边矩阵偏红色的小格子,表明两个物体形状上比较相似(比如球和灯泡);右边矩阵红色的小格子,是表明两个物体所激活颞枕皮层整体模式比较相似。如果这两个矩阵对应,就表明人们看到形状相似物体图片或者听到他们名字时候,这个皮层激活模式也相似;而看到或听到形状不同物体刺激(如球和激光笔),激活模式也不相似。
栗子的结论
我们发现无论是先天盲人还是正常人,该区域的神经模式矩阵都是和他评定出来的形状相似矩阵相关的。也就是说,对于无论是先天盲人还是正常人,只要觉得两个物体形状相似,大脑中对这两个物体的神经活动模式就像;而对于两个觉得长的不像的物体,比如球和激光笔,该区域的神经活动模式就非常相同。
所以无论是健康人还是先天盲人该脑区的神经活动模式,都由物体形状所决定的,而这种形状表征可以不通过视觉经验形成。
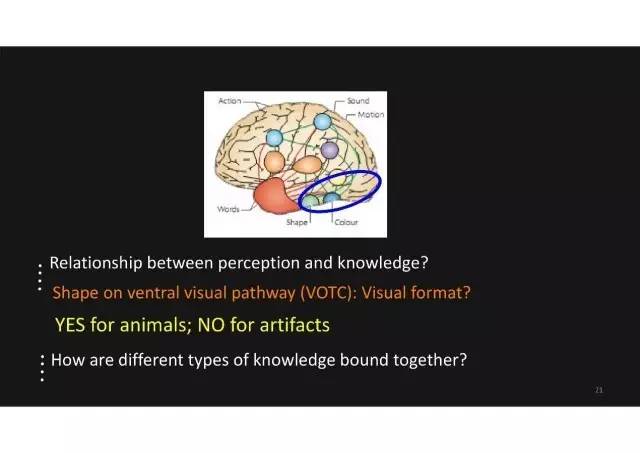
两个问题
1. 第一个问题的答案
我通过跟大家分享了两个先天盲人的实验,对刚才第一个问题进行回答:人对物体长什么样子的知识与实际视觉识别它的经验之间关系是非常复杂的,不是简单的是或者不是的答案,而是受到了不同物体类别的影响。对动物识别脑区来说是非常依赖视觉,但是对于许多其他类型物体,特别是人造物,识别脑区并不依赖于视觉经验。
2. 第二个问题
第二个大问题是,既然我们对于物体包括丰富的分布在大脑多个脑区的视觉与非视觉特征,这些特征如何融合到一起,这种融合对我们的物体识别又有什么影响呢?
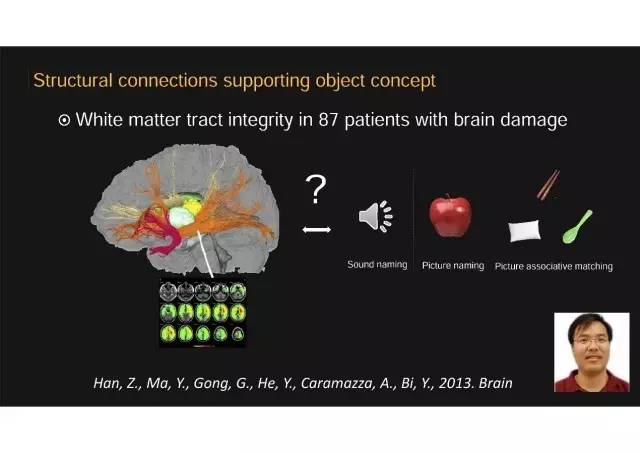
关于这个问题我有三个研究与大家分享。
第一个研究
第一个是我和韩在柱教授之前的一个合作,通过研究脑损伤病人看哪些大脑结构连接对物体的识别和理解更为重要。脑损伤病人研究大脑功能非常直接强大的研究手段,因为可以看到不同脑结构被破坏对认知行为的影响。我们与中国康复研究中心合作收了近一百个病人,分析了87个病人中大脑主要白质纤维束损伤情况与物体识别和理解障碍的关系。白质纤维束是神经传导的重要结构,是由大量大轴突形成的束(bundle)。
我们每个病人都获得两方面的数据:
-
脑数据:他在主要白质纤维束上是否有损伤,是否有病灶,病灶有多大;
-
认知行为数据:物体识别和理解的能力,比如他是不是认识这个东西是苹果,听到”喵”这个声音他知不知道是小猫?
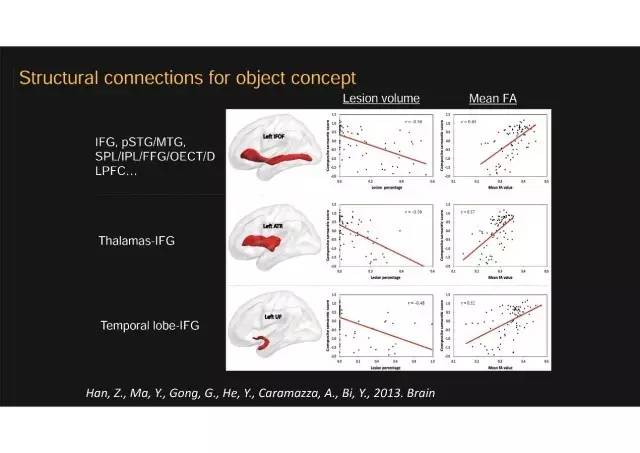
第一个研究的结论
我们把脑与认知行为数据做相关,发现了三个主要白质纤维束上有显著相关,也就是说这三条纤维束的完好对这种物体识别和理解不可或缺。上面这个我们叫下额枕束,散点图里每个点是一个病人,在这个白质束上损伤更严重,物体识别和理解障碍也越严重,比如看到苹果的图片可能会说叫桔子或者香蕉。下面这两条白质束也是相似的模式。这些结果说明物体识别和理解依赖于远程脑区之间的结构连接。
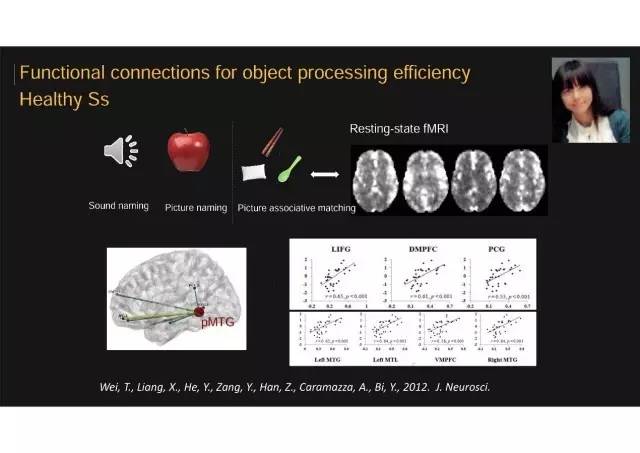
第二个研究
魏涛博士等人这个实验是在健康群体中观测人之间个体差异的情况。健康被试群体虽然这些物体都认识,但加工能力、效率也有区别。
第二个研究的结论
我们发现这种物体识别理解能力,与额叶和顶叶一些视觉和语义相关皮层之间静息状态(休息、不做特定任务)下功能连接的强度有关系。一个人这些在静息态脑功能连接强度可以某种程度上预测他/她在物体加工能力的强弱。具体来说,比如我们看这个后侧的颞叶脑区和额叶在静息状态下功能同步性的强弱,强度越高可能这个人在加工物体的时候速度就越快。
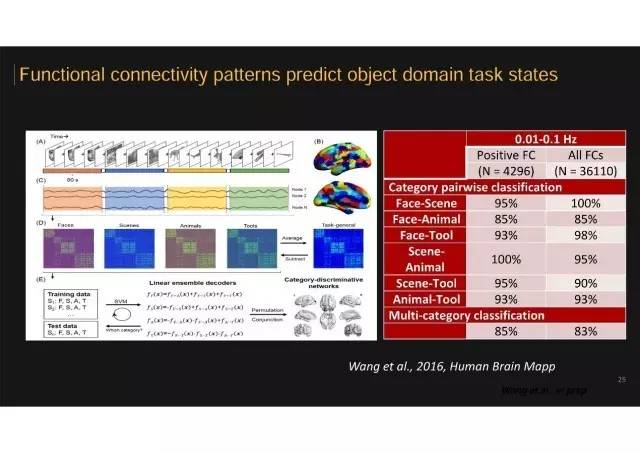
第三个研究
刚才的两个实验都是看人和人之间的差异,最后一个实验是看对同一个受试者来说,识别不同物体的时候大脑不同连接的模式,是不是可以预测出来这个人正在看什么样的物体。在王晓莎博士等人这个研究中,我们让受试者在磁共振机器中看不同类型的物体,有场景、面孔、工具、动物。然后我们把大脑不同脑区之间的活动连接强度作为特征,采用机器学习进行预测。
第三个研究的结论
1. 不同脑区之间连接模式状态可以非常准确地预测被试正在看什么类别的物体;
2. 如果我们把视觉皮层全或者物体特定类别选择性激活的脑区拿掉,剩下脑区之间的连接模式也可以对物体类别做有效的区分。也就是说不仅仅视觉皮层本身完成物体视觉识别,而是伴随了广泛的大脑多个系统间的对话和协作。

第二个问题的初步答案
所以我们对于第二个问题有些初步的回答:
1. 我们发现了很多连接远距离脑区的白质结构连接,静息态功能连接和任务态功能连接直接参与到物体识别和处理过程中。
2. 损伤这些连接会导致物体识别能力的障碍。
3. 他们的连接强度可以预测一个健康个体能力的强弱。
4. 同一个人脑区间连接模式的不同状态可以预测你在看什么类型的物体。

写在最后
我们回到物体识别这个主题,通过跟大家分享的这几个包括先天盲人、脑损伤病人、健康个体的实验,我希望说清楚的信息是,对于人脑来说,处理不同类型物体的过程和机制是非常不一样的,物体视觉识别的过程与我们如何与它进行交互、包括非视觉的交互,都密切相关。
柏拉图有个经典说法说一个成功的理论是:Carving the nature at its joints—对自然界的正确切分。我们觉得大脑成功点也在此——对自然世界的进行特定的切分处理。
我目前的想法是, Evolutions develops different templates for processing different object domains of evolutionary significance, through local and connections properties。对于人的进化有非常不同进化意义和目的的物体,大脑可能进化出了不同的模板去处理,而这种模板既包括视觉系统内部的特征,也包括视觉与非视觉系统的关系。
希望我们未来可以对这些模板和网络细节机制的理解不断获得新的进展。

谢谢我在北师大课题组的博士生、博士后进行的研究工作,也谢谢我们的合作者和基金资助。谢谢!
文中毕教授提到的所有引用文章下载链接为: https://pan.baidu.com/s/1slTTpCD
致谢:

本文主编袁基睿,诚挚感谢志愿者高春乐、范琦、李珊如对本文进行了细致的整理工作

该文章属于“深度学习大讲堂”原创,如需要转载,请联系 astaryst。
作者信息:



毕彦超,北京师范大学长江学者特聘教授, IDG /麦戈文研究所和认知神经科学与学习国家重点实验室团队负责人。毕教授于2006年获得哈佛大学心理学博士学位,目前的研究方向是语义记忆和知识表征认知神经基础的研究,工作获科技部973青年项目、中国国家自然科学基金(优秀青年基金)、中组部青年拔尖人才等项目支持。毕教授是Scientific Reports 和 Cognitive Neuropsychology的编委,是美国心理生理学Sackler scholar和Fullbright scholar,并被美国心理学会新星奖。
VALSE是视觉与学习青年学者研讨会的缩写,该研讨会致力于为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。2017年4月底,VALSE2017在厦门圆满落幕,近期大讲堂将连续推出VALSE2017特刊。VALSE公众号为:VALSE,欢迎关注。

往期精彩回顾
视频行为识别年度进展
VALSE2017系列之四:目标跟踪领域进展报告
深度学习大讲堂改版纪念:一个陌生女人的来信
VALSE2017系列之三:人体姿态识别领域年度进展报告
VALSE2017系列之二: 边缘检测年度进展概述



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站



