12倍端到端加速,陈天奇创业公司OctoML提出克服二值网络瓶颈新方法
选自medium
作者:Josh Fromm
机器之心编译
机器之心编辑部
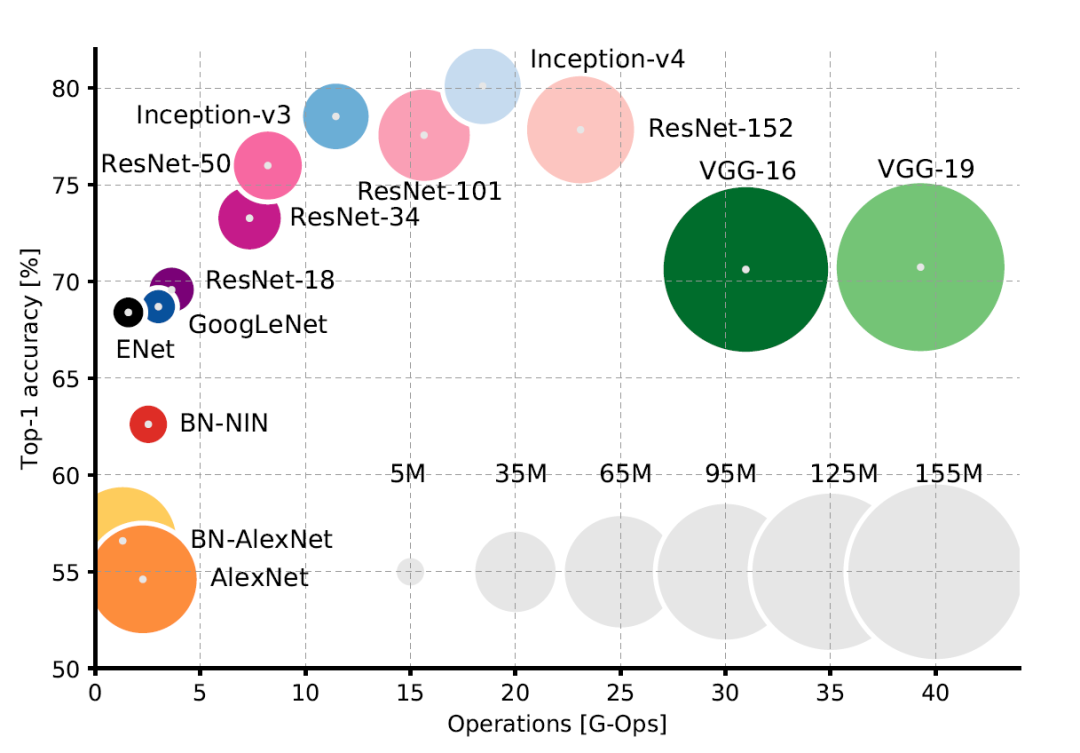
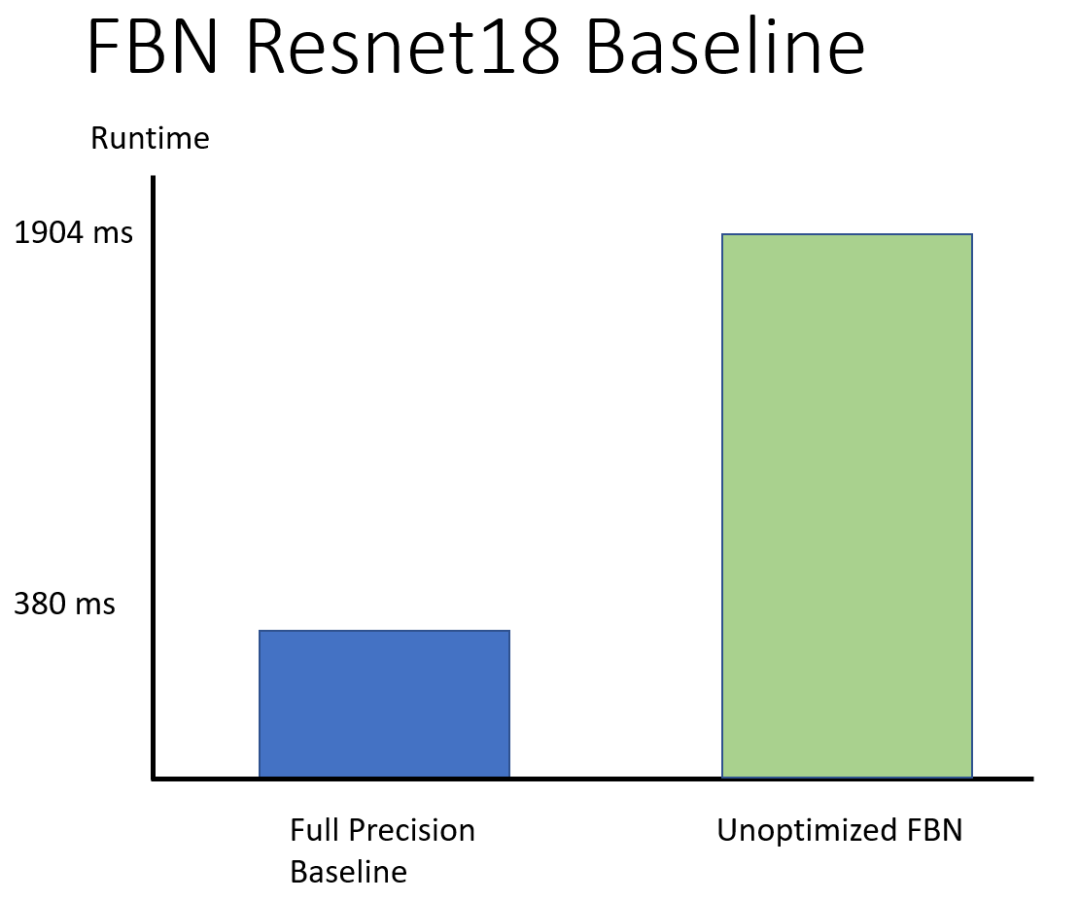
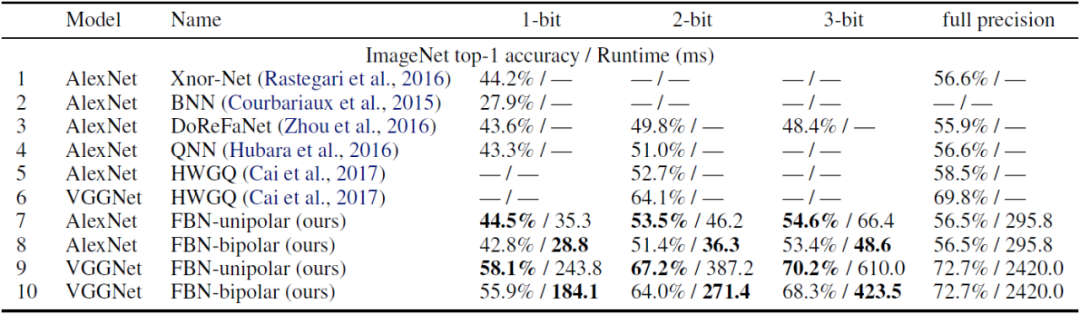
去年,TVM 开发团队陈天奇等人创建了 OctoML 公司,旨在「让机器学习可以部署在所有硬件上」。前段时间,该公司推出了第一个软件即服务产品 Octimizer,可以帮助开发者更方便、快捷地将 ML 模型部署到设备上。近日,该公司官方博客又介绍了一种快速端到端二值神经网络——Riptide,使用 TVM 进行优化时可以实现最高 12 倍的端到端加速。该公司机器学习系统工程师 Josh Fromm 在博客中介绍了 Riptide 的细节。

论文链接:https://proceedings.mlsys.org/static/paper_files/mlsys/2020/155-Paper.pdf
GitHub 项目:https://github.com/jwfromm/Riptide
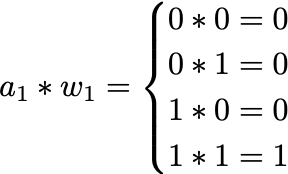
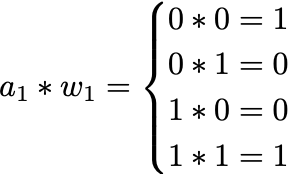

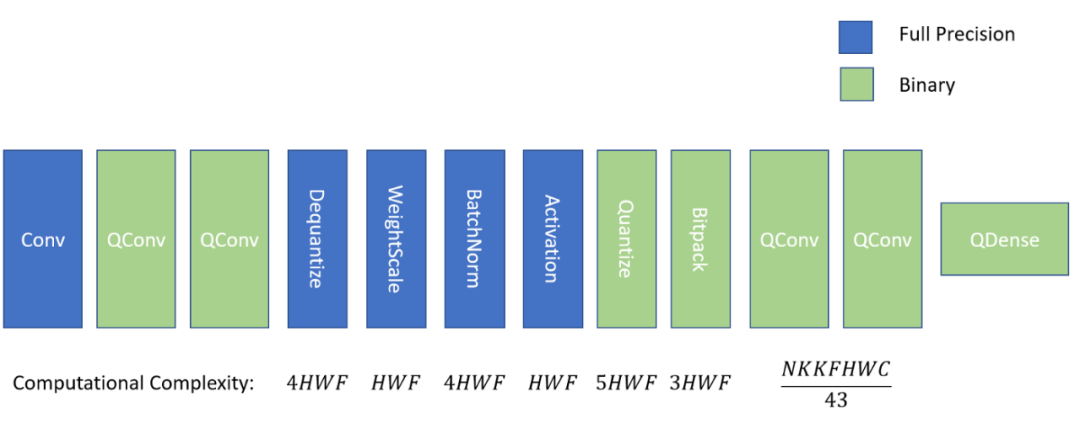
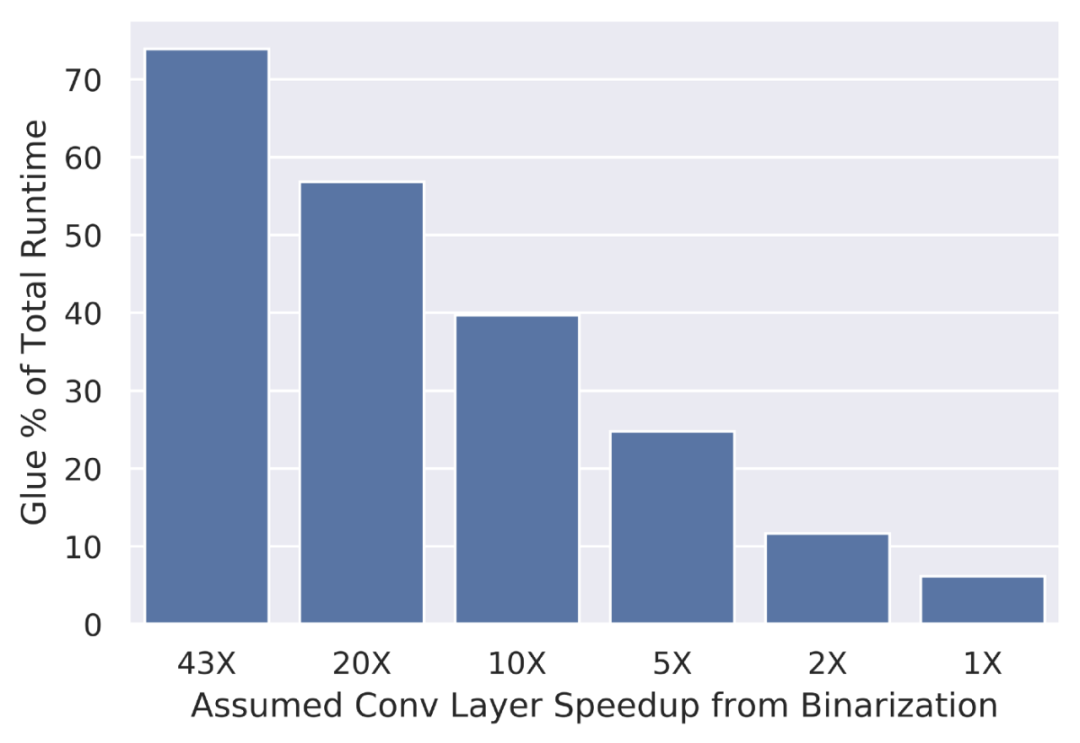
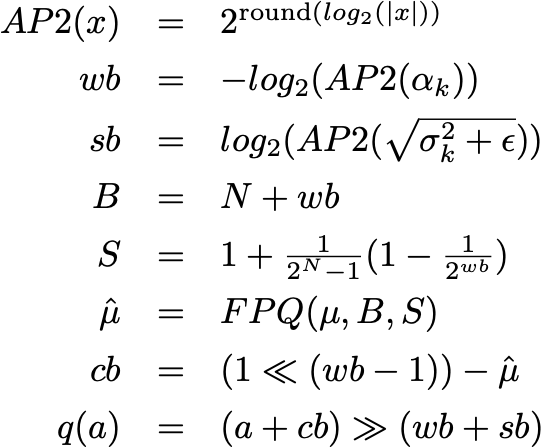
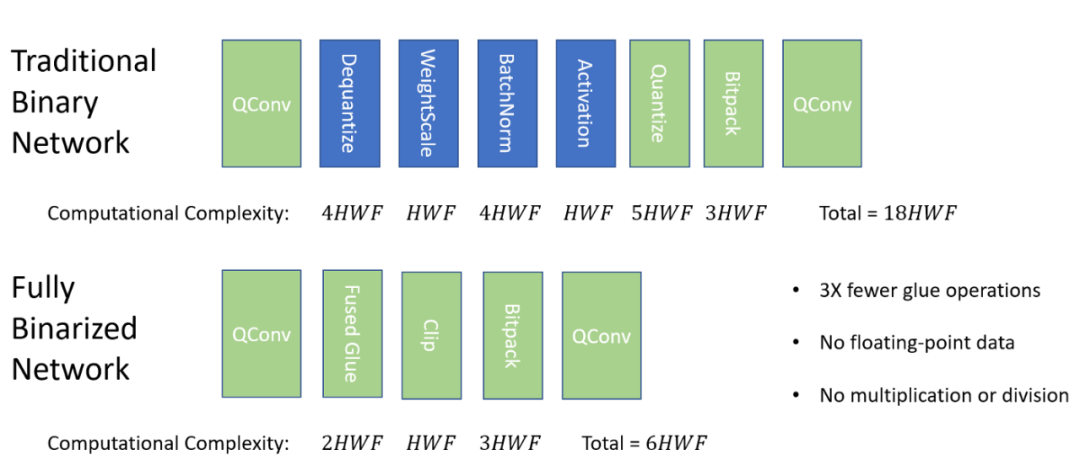
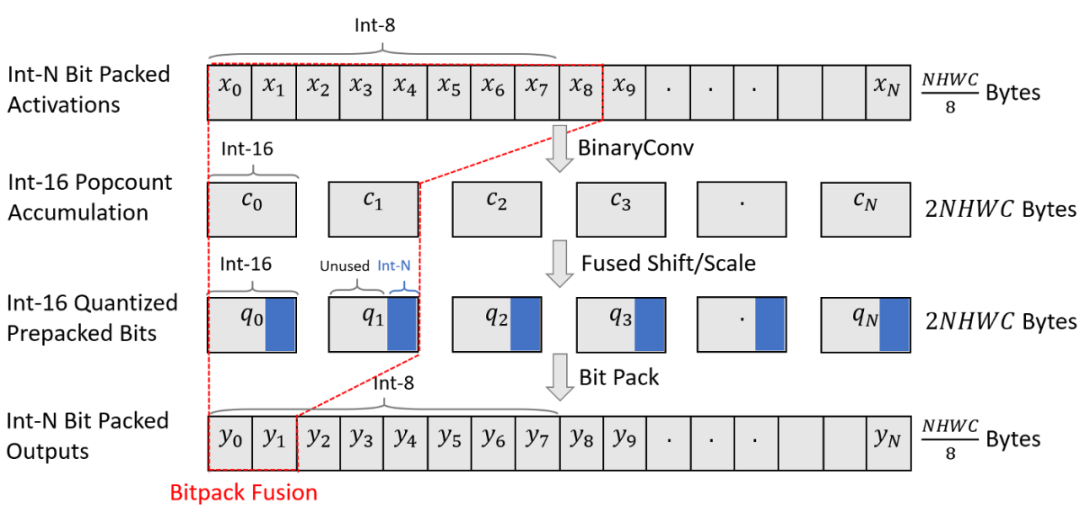
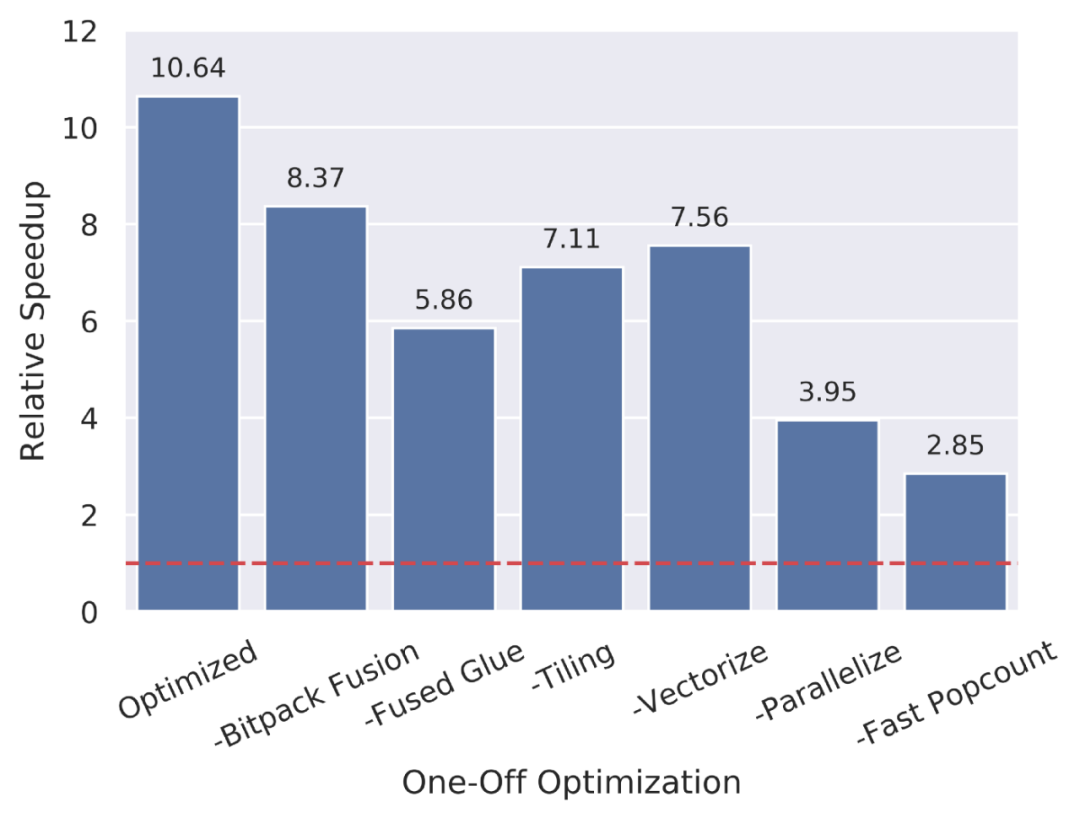
Tiling 将一个计算分解成多个块,以改善负载的内存局部性。
Vectorization 利用硬件 SIMD 指令来实现更高效的运算执行。
Parallelization 利用多核等 MIMD 设施。
Loop Unrolling 复制循环体来减少开销。
登录查看更多
相关内容
Arxiv
4+阅读 · 2018年1月11日

相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年1月11日