【LeCun再怼阿里】NIPS机器学习炼金术之争,Twitter机器学习研究员参战

新智元报道
编辑:胡祥杰
【新智元导读】LeCun阿里炼金术战火再升级:俩人在Facebook上展开了直接的对话,火药味甚浓。Twitter机器学习研究员发表了见解:机器学习需要什么样的研究方法?

2017NIPS "Test of Time"论文大奖获得者Ali Rahimi (阿里·拉希米)在长滩现场的演讲中把机器学习称为“炼金术”(Alchemy)引起的机器学习界大讨论仍在蔓延。
昨天,著名的深度学习领军人物 Yann LeCun 在自己的主页上回应阿里,他说自己完全不同意阿里的说法,还说,It's Insulting, yes. But Never Mind: It's Wrong。
这事还没完,阿里随后晒出了自己在NIPS现场的合影,并称“A NIPS rigor police reuinion”(NIPS 严谨警察聚在一起),LeCun随后转发并评论:Rigor 警察没引起 Rigor Mortis(死后的第三阶段,也就是尸体变硬)。
看来LeCun老人家也是够毒舌。
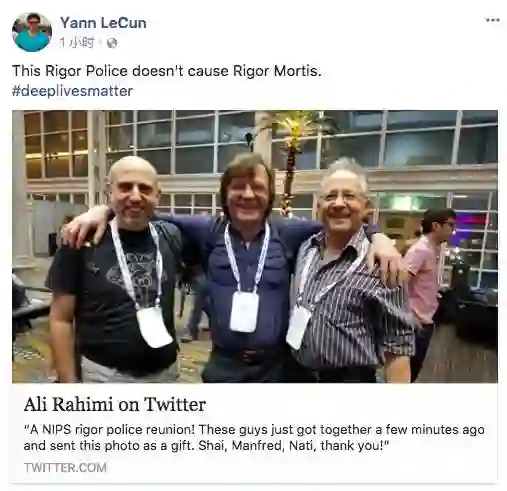
早些时候,两人还在Facebook上直接过招:
一石激起千层浪,今天,网络上出现了更多机器学习界的代表发声,其中较为有代表性的便是Twitter机器学习资深研究员 Ferenc Huszár。 Ferenc 此前是Magic Pony的首席科学家,去年Twitter出资1.5亿美元收购这家位于伦敦的初创企业后, Ferenc 加入Twitter。
Ferenc说,和你们中的许多人一样,我从头到尾看完了阿里·拉希米(Ali Rahimi)的NIPS演讲,很享受。
如果你还没有,我建议大家看看。(视频在文末)
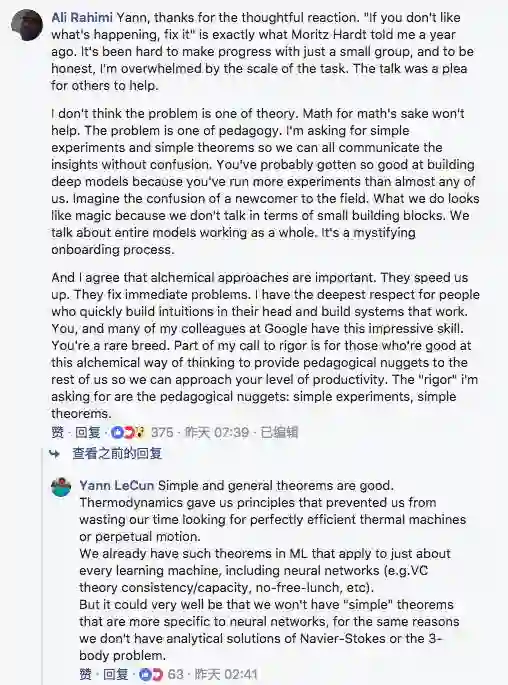
我也读了 Yann LeCun 对阿里演讲内容的反驳。他说阿里所指的“炼金术”实际上是工程学。虽然我认为LeCun实际上反对东西阿里在演讲中并没有提到,但是他提到了一些很重要的点:Tricks、经验证据和理论分别在工程中扮演什么角色?
他说在混战中,我也想补充一点自己的见解和经验,以下内容为Ferenc的观点:
我们可以将机器学习的知识作为一个图来思考,其中各种方法是一个个节点,线条则表示方法之间的连接或类比。
而创新指的是让图不断增长,这可以通过不同的方式来实现:
1. 增加新的节点
这是关于“跳出去”的思考,关于发行一些全新的、新奇的方法,当然,最好还是有用的。最近这种ML创新的例子包括Herding,目标噪声,批量规范,dropout和GAN。这就好像是你在图中增加了一个新的节点,可能与图的其他部分有些微弱的联系,但是一开始你并不能想所有人清楚地解释自己的逻辑。
2. 在既有的节点中发现新的连接
这其实指的为新的方法提供解释。比如,将k-means解释为期望最大化,dropout解释为变分推理,随机梯度下降解释为变分推理,GANs作为f-GANs,蝙batchnorm作为自然梯度,降噪自动编码器作为分数匹配等。这些都是有着巨大影响力的工作,在机器学习中,我们非常需要这类工作,因为这些连接经常使我们能够改进或扩展技术,从而取得更可预测的进展。
3. 完成模式
这指的是类比推理。您注意到图中有很多不完整的模型,并通过完成模式推断出一些节点必须存在。在NIPS 2010的Sam Roweis研讨会上,我记得Zoubin Ghahramani开玩笑说他和Sam如何一起通过完成超立方体(hypercubes)写了一大堆基本上免费的论文,就像下面的那样。长期以来,我的博客读者会知道,Sam和Zoubin的unifying review 是我最喜欢的论文之一。请注意,这种“模式完成”也发生在贝叶斯世界之外:请参阅双向卷积RNN或PixelGAN自动编码器。
这些创新模式中的每一个在建立知识和推动发展的过程中都是重要的。我们所在的社区倾向于看重#1,只要论文标题中出现标志性热词(比如DeepLearning)。从个人来看,我们被激励去写大量的论文,所以我们大部分时间都花在#3上,这可以说是风险最小的增量项目。我认为我们对2的奖励或鼓励还不够。在我看来,这是阿里谈话中的主要信息之一过多关注基准,数据集和实证结果,我们实际阻碍了那些解释为什么方法起作用或不起作用的人们设下障碍。
今天大概没有多少人会记得最开始提出GAN的论文取得的结果是怎么样的。回到当时,那些效果真的不错,但是在今天,看起来却让人忍俊不禁。
GAN可以说是一个非常有影响力的、伟大的新想法。如果这篇论文是在今天,很肯定能是没有人接收的,因为照片看起来不够漂亮。 Wasserstein GANs是一个好的想法,坦率地说,认识到这是个好想法,我根本不需要看实验结果。
同样,Yann认为神经网络在90年代被不公平地抛弃,因为缺乏凸优化方法的收敛性保证,今天我们也在不公平地否定任何不产生最新或近SOTA结果的方法或思想。我曾经评审过一篇论文,其中一位评审员写道:“如果这种方法成为与现有方法相比最有效的方法,那么这项工作可能是新颖的……”。这是错误的,至少没有比因为缺乏理论支撑而否定新创业正确多少。(这是顺便说一下,这不是阿里建议的)
就我而言,现在我习惯于使用非严谨的方法,或者理论框架不完善或者根本不存在理论框架的方法。但是,对于任何评估不严格的论文,任何人都不应该叫好。
在GAN论文中,我们展示了漂亮的图片,但是我们绝对没有严格的方法来评估样本的多样性,或者是否发生了任何形式的过度拟合,至少不是我所知道的。从我的经验来看,让一个足够新颖的深度学习理念起作用,整个过程是非常脆弱的:一开始,没有任何东西起作用,然后开始工作但不会收敛,然后收敛了,但是却得到错误的东西。整个事情偶是行不通的,而且往往还不清楚具体是什么工作的,直到某一天忽然一切忽然好起来。这个过程类似于多个假设检验。你可以跑无数的实验,并报告那些看起来最好并按照你预期的方式行事的结果。但是,根本问题是,我们是将实施一种方法所需的软件开发过程与手动超参数搜索和结果挑选相结合得到的结果。因此,我们所报道的“经验证据”可能比人们所希望的更加具有偏向和不可靠性。
我同意Yann所说,在理论或严谨的分析变得可行之前,开始采用技术是有好处的。然而,一旦理论洞察变得可用,关于经验表现的推理往往继续超越严谨。
让我告诉你我遇到过几次的事情(你可能会说我只是为此而苦恼)。
具体是:有人提出了一个想法,他们表明,使用一个非常大的神经网络和大量的技巧,加上大概几个月的手动调整和超参数搜索,一些大的、复杂的问题可以得到很好的解决。
我发现这个方法有个理论上的问题。
但是人们说:在实践中仍然运作良好,所以我没有看到问题。
这是我提出对“定期抽样”和“弹性权重合并”批评后得到的回复。在这两个例子中,批评者指出这些方法在“现实世界的问题”上工作得很好,而在“定期抽样”的例子中,人们评论说“毕竟这个方法在基准评测中是第一位的,所以必须是正确的”。不,如果一个方法有效,但是却是出于错误不同于作者给出的原因,这里还是有问题。
你可以把“对数据集进行深度学习的方法”作为一个统计测试。我认为实验的统计力量是非常弱的。我们做了很多事情,比如提前停止,手动调整超参数,运行多个实验,只报告最好的结果。我们大概都知道在测试假设时我们不应该做这些事情。然而,在ML论文中报告实证结果时,这些实践被认为是很好的。许多人继续认为这些报道的实证结果在支撑某一种方法时,是“有力的经验证据” 。
我想感谢阿里发表这个演讲。是的,这是一种对抗。侮辱(Insulting,LeCun用词)?我觉得挑衅是一个更好的词。显然,这至少有点争议。它虽然,包含了几点我不同意的内容。但我不认为这是错的。
它触及了很多我认为应该得到社区认识和赞赏的问题。 严谨指的不是学习理论、收敛保证、边界或定理证明。 智力上的严谨适用于所有机器学习,无论我们是否已经完全开发出用于分析的数学工具。
严谨意味着彻底,详尽,细致。它包括良好的实践,如诚实地描述方法的潜在弱点、考虑可能出现什么问题、设计突出和分析这些弱点的实验、对某些算法的行为做出预测,并凭经验证明其行为满足预期、拒绝使用不合理的评估方法、接受和处理批评。
所有这些应该适用于机器学习,不管它们是不是深度学习,实际上它们都适用于整个工程。
阿里·拉希米(Ali Rahimi)的NIPS演讲:
LuCun回应的地址:https://www.facebook.com/yann.lecun/posts/10154938130592143





