读了那么多GANs的原理,还是不懂怎么用!两个案例教教你

编译|AI科技大本营(rgznai100)
参与 | 尚岩奇、周翔
生成式对抗网络(GANs)是一类用于解决无监督学习问题的神经网络,它们可以完成各种任务,例如通过描述生成图像,利用低分辨率图像还原出高分辨率图像,预测哪种药物可以治疗某一疾病以及检索包含某一给定模式的图像等。


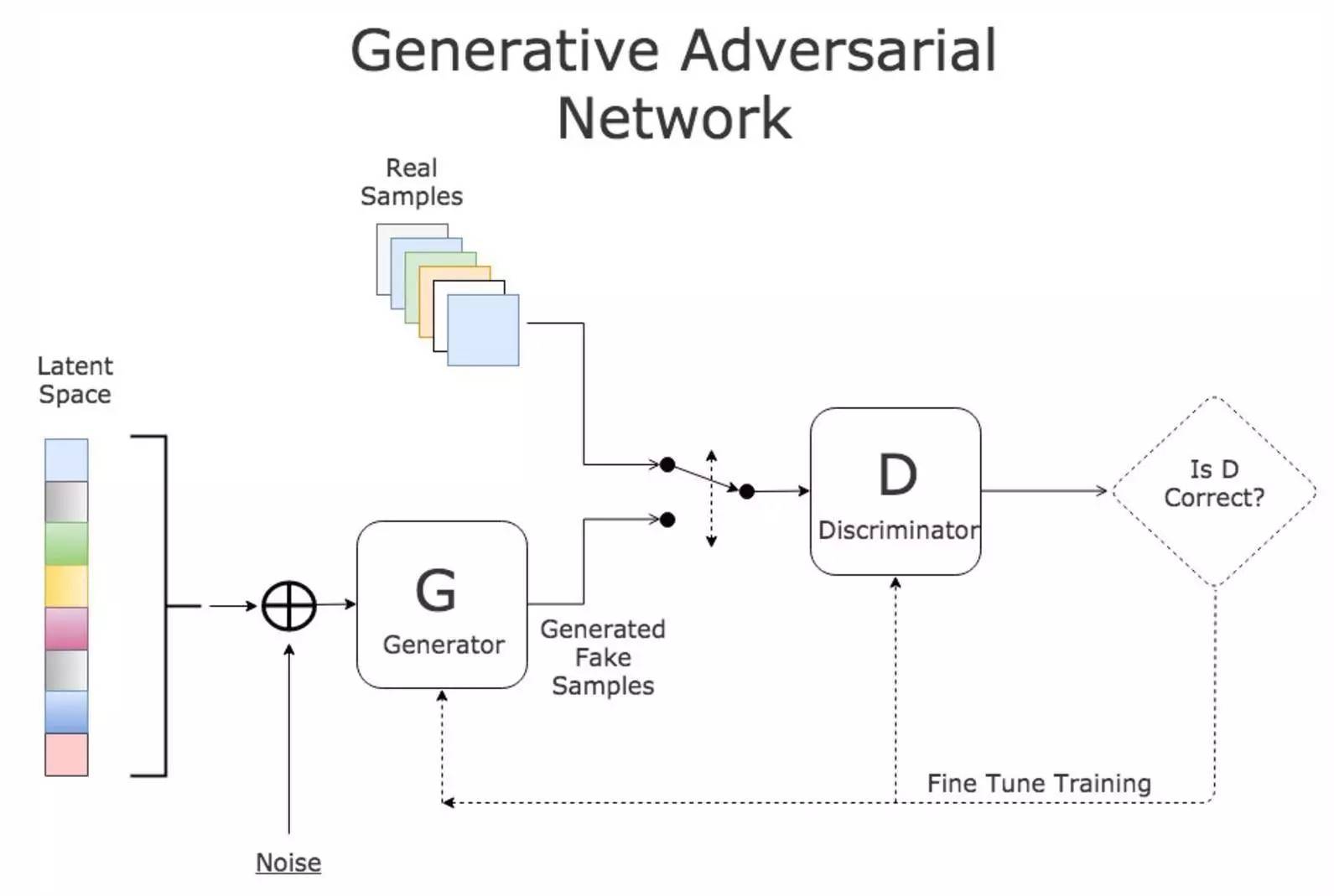
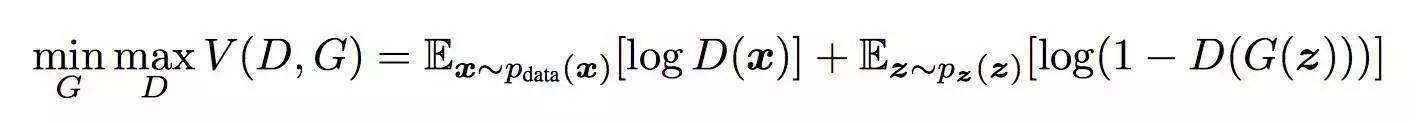
换句话说——生成器加大力度欺骗判别器,而判别器则为了不被生成器欺骗变得更加挑剔:

需要大量标记图像;
商家标志无对应的标签;
标志未从数据集分离出来。
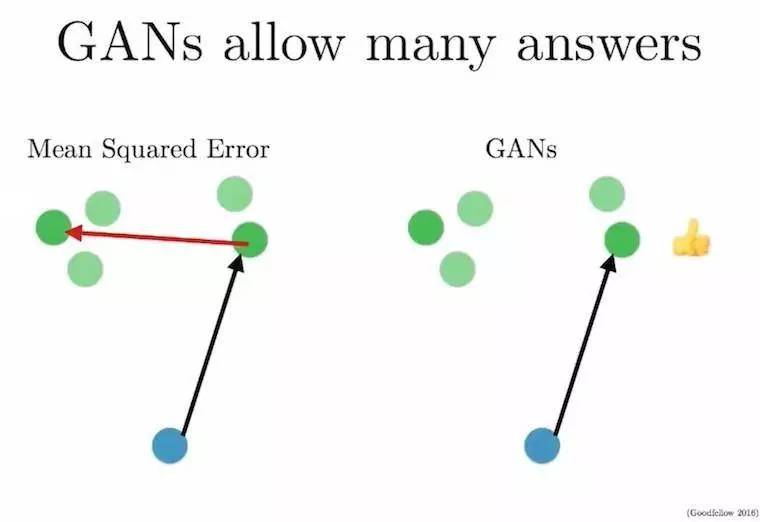
以下面这个任务为例,将蓝色输入圆点映射到绿色输出圆点上(绿色圆点是蓝色圆点可能输出的结果)。红色的箭头代表预测错误,意味着蓝色圆点在一段时间后会映射到绿色圆点的均值上——这正是导致我们试图预测的图像变得模糊的原因。

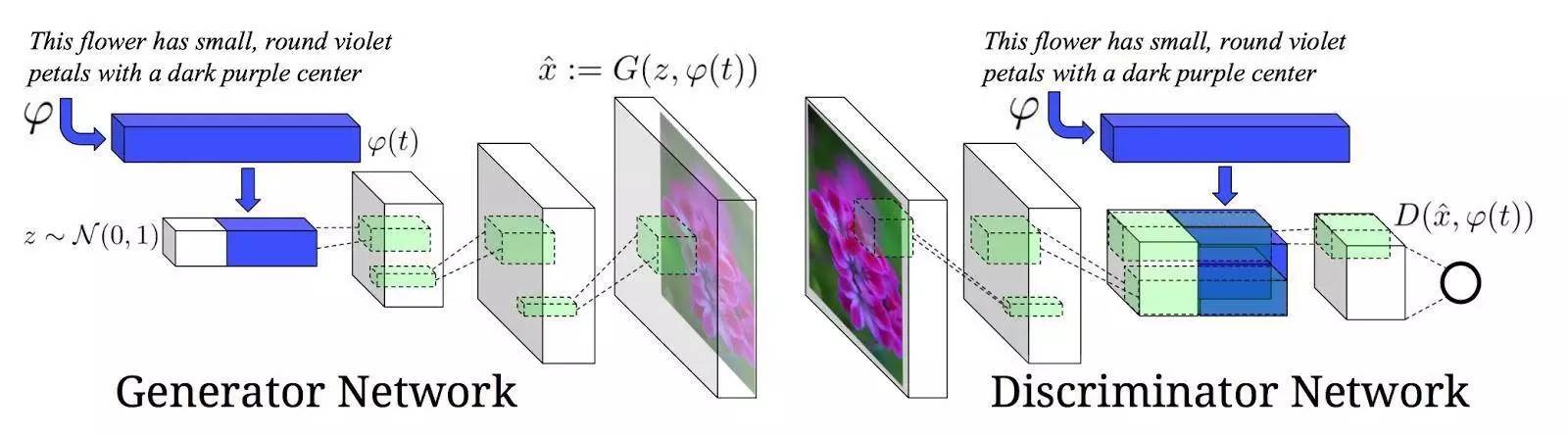
Caltech-UCSD-200–2011 是一个由 200 种鸟类的照片构成图像数据集,共有图像 11788张。
Oxford-102 Flowers 数据集由 102 种花卉的照片构成,每一种花的图像张数都在 40 至 258 之间。
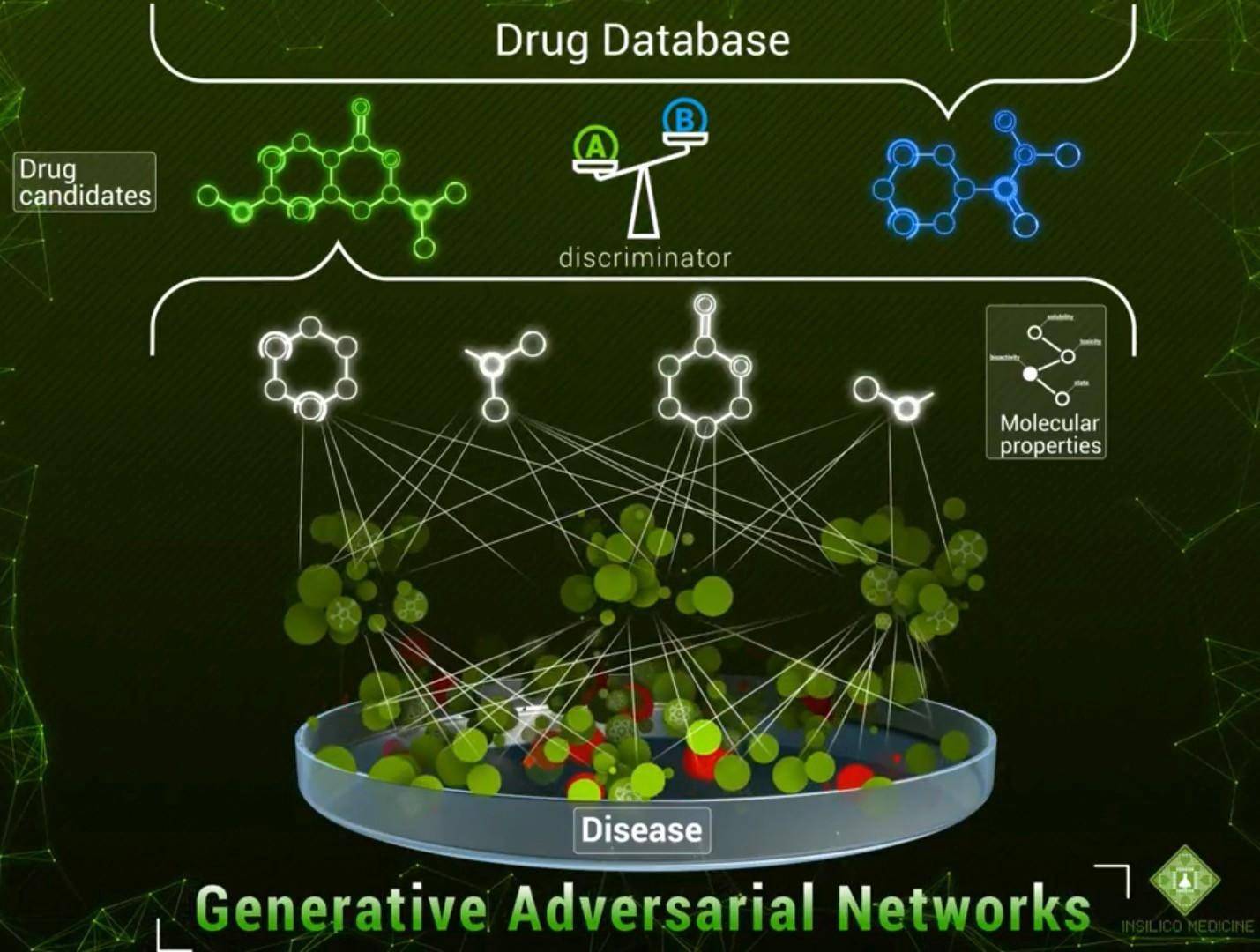
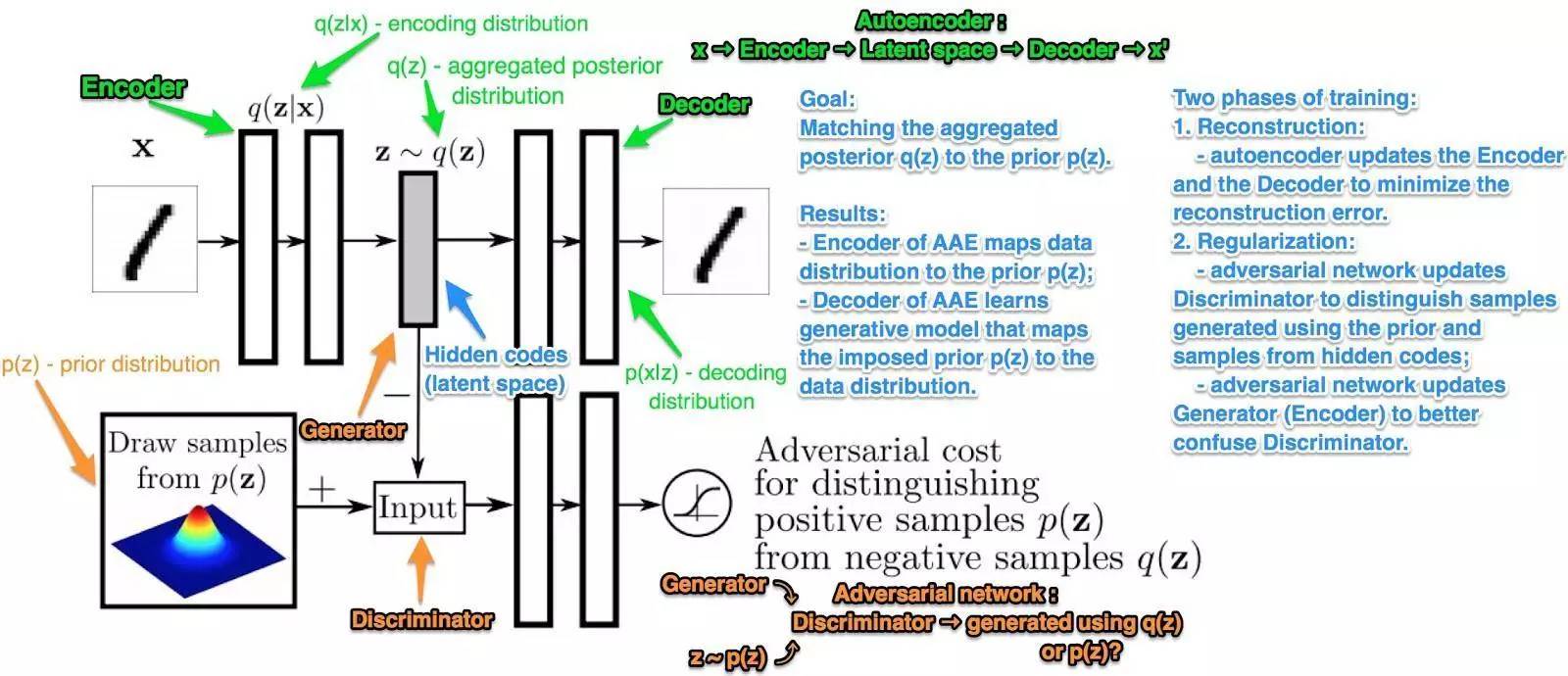
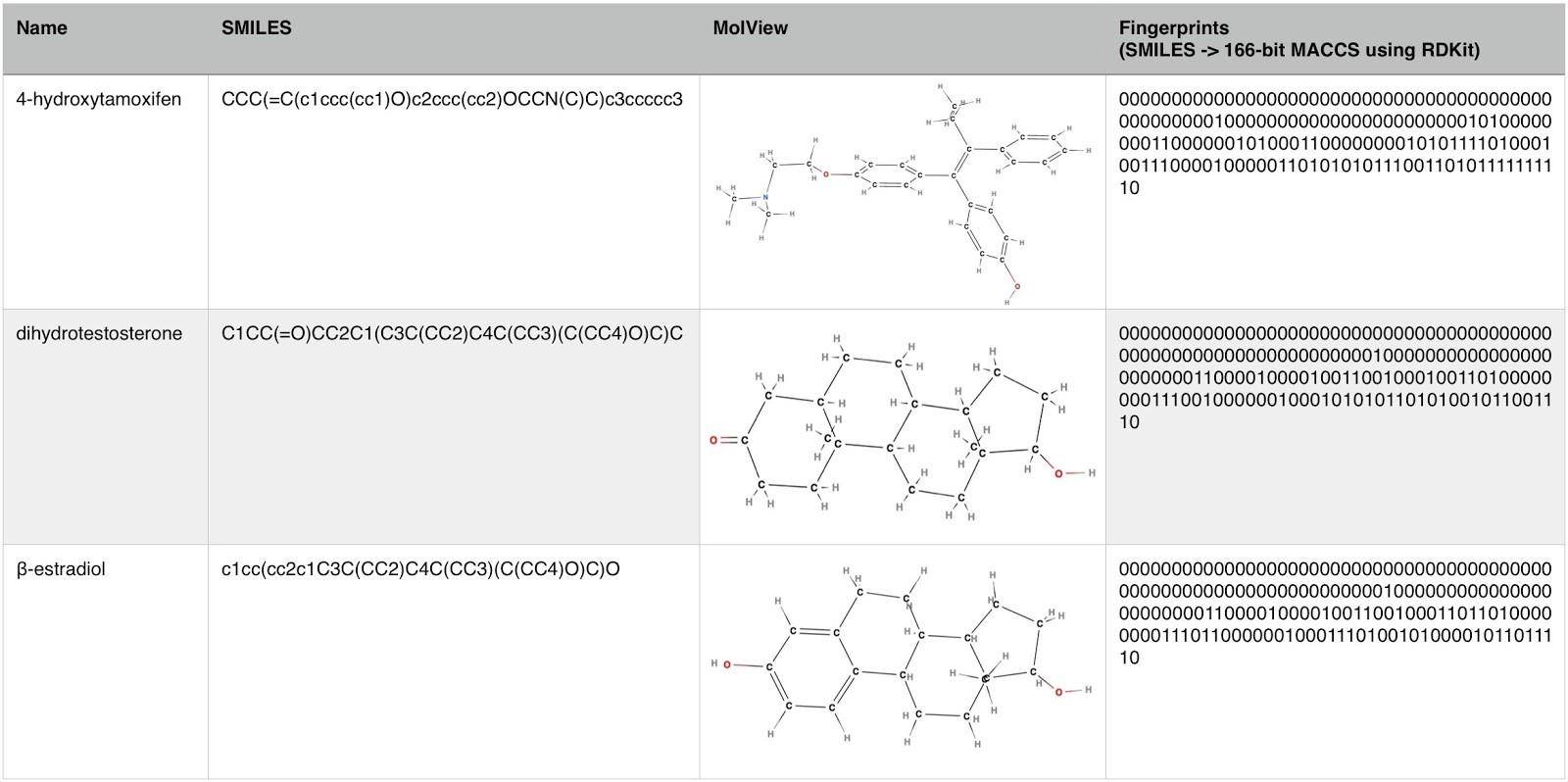
该公司将成长抑制(Growth Inhibition)百分率数据(从 GI 可以看出药物治疗后癌细胞数的减少量)、药物浓度和指纹图谱作为输入,训练对抗式自动编码器。
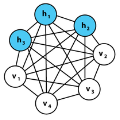
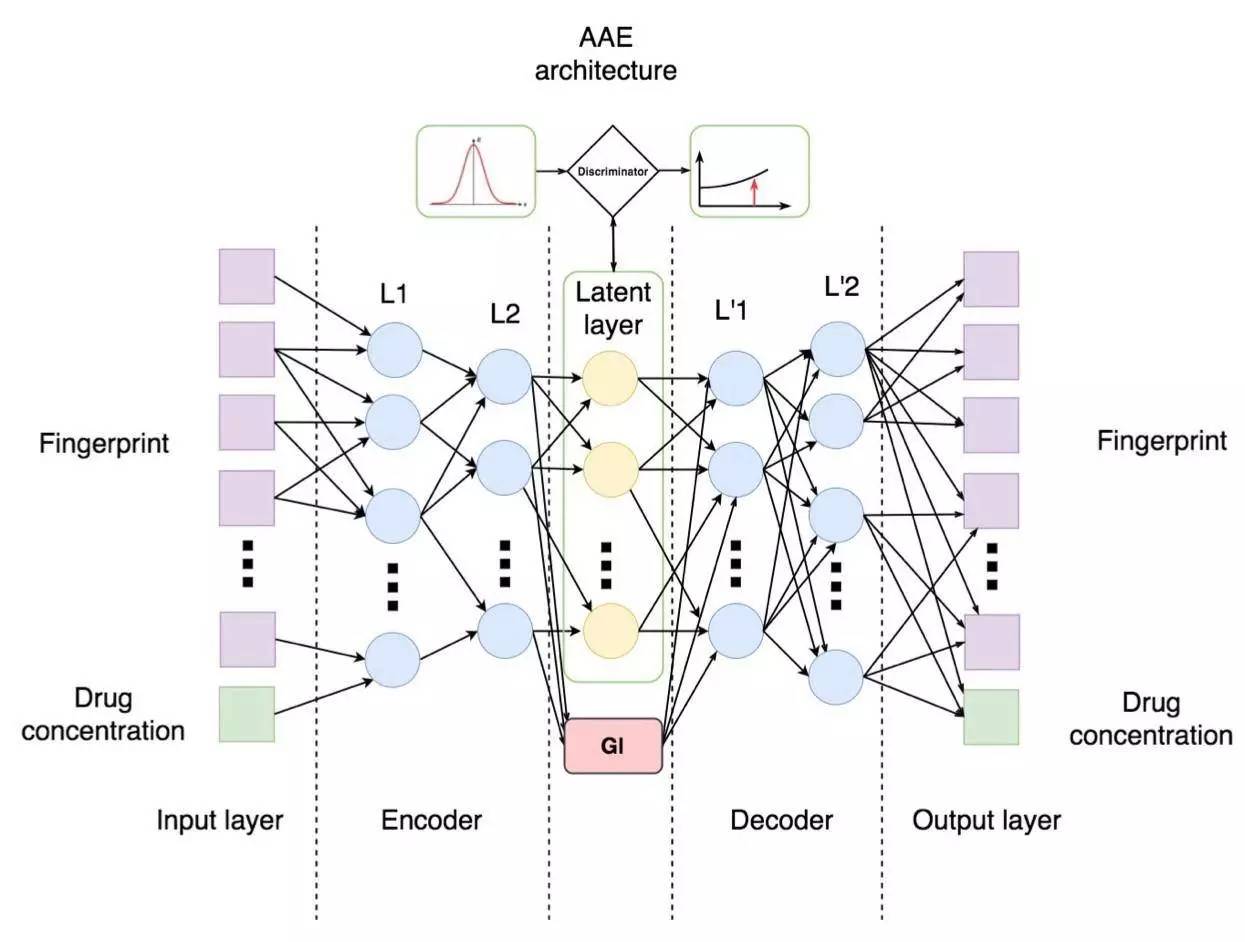
隐层( latent layer)由 5 个神经元构成,其中一个神经元负责 GI(抗癌细胞的效率),其余四个使用正态分布加以区分。编码器损失函数中添加有一个回归项,而且编码器只能将相同的指纹图谱映射到相同的 latent 向量,并且通过附加的多重损失独立地映射输入浓度。
GAN 可以使模型理解某些问题可以有很多正确答案(即正确处理多模式数据);半监督学习:当已有的标记数据数量有限时,判别器或者推理网络(inference net)得出的特征可以改进分类器的性能;
对抗网络可以用来实现确定性多预测深度玻尔兹曼机的某一随机扩展;
将 c 同时作为生成器和判别器的输入添加到函数中,这样就可以得出一个条件生成模型p(x|c)。
继续阅读
What is a Variational Autoencoder?
https://jaan.io/what-is-variational-autoencoder-vae-tutorial/
Ian Goodfellow about GANs for Text on Reddit
https://www.reddit.com/r/MachineLearning/comments/40ldq6/generative_adversarial_networks_for_text/
“StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks” by Baidu Research
https://arxiv.org/pdf/1612.03242.pdf
“Generative Visual Manipulation on the Natural Image Manifold” by Adobe Research
https://arxiv.org/pdf/1609.03552v2.pdf
“Unsupervised Cross-Domain Image Generation” by Facebook AI Research
https://arxiv.org/pdf/1611.02200.pdf
“Image-to-Image Translation with Conditional Adversarial Networks” by Berkeley AI Research
https://arxiv.org/pdf/1611.07004.pdf
原文地址
https://blog.statsbot.co/generative-adversarial-networks-gans-engine-and-applications-f96291965b47
AI科技大本营
招实习生啦