【机器学习】机器学习工业领域应用

机器学习算法逐渐潜入我们日常生活,但是工业应用却不如消费应用普及。Inductive Automation
为了把机器学习技术应用于工业,须先了解机器学习分成哪里些种类,有哪里些不同的算法,以及实际应用时有什么值得注意的地方。
据Automation World报导,机器学习算法逐渐潜入我们日常生活,但是工业应用却面临不少瓶颈,不如消费应用那么普及,Inductive Automation的Kathy Applebaum指出,综观目前工业采用机器学习技术的情况,以预测性维护(PM)为大宗,其次是品管、需求预测和机器人训练。
机器学习主要分成三大类型。首先是资料分析,Applebaum指出,诊断性分析(diagnostic analysis)是为了找出问题的原因,预测性分析(predictive analysis)则根据过去的资料预测未来,建议性分析以预测性分析为基础,建议该如何解决问题。
至于算法的种类,第一种是分群算法(k-means),Inductive Automation的Kevin McClusky指出,分群算法不清楚各个类别所代表的意义,只会计算每一个点到已设定的群集中心的最短距离,进而决定下一个群集中心,很适合进行资料分类,完成缺陷分析。
第二种算法称为决策树,Applebaum认为很适合预测性维护,也可以跟其它算法搭配使用。
第三种算法称为回归分析,McClusky认为适合调整工作流程和预测产量,例如依照目前的变量来预测产量。至于神经网络算法,则是模拟人脑的运行方式,工业最常见的应用是在视觉系统。
无论何种机器学习应用,都需要先收集优质的资料,首要之务便是找到适合的资料并加以处理,进而确保资料质量。McClusky也建议企业执行机器学习计画时,务必采用撷取、转换和载物(ETL)来取得资料,把资料收集流程自动化。Applebaum则建议勇于多尝试不同的算法,各家供应商皆有提供分群、神经网络、回归等各式各样的算法。
以数据驱动的自发性CIM系统
入人工智能到CIM(Computer Integrated Manufacturing)系统内,以产生更高的经济价值,已严然成为趋势,但元智大学工业工程系副教授锺云恭指出,因为机器学习过程中,学习结果的可塑性(Plasticity)及稳定性(Stability)很难同时满足,而使智能制造「聪明反被聪明误」,但若智能制造中的机器学习方式,慎用递增式学习(Incremental Machine Learning)的特性,将会使智能制造永续学习成为可能。
此外,物件式资料仓储(Object-Oriented Data Warehousing)的使用在递增式的学习中格外重要,因为相对于物件资料的关联资料,其相依性比物件资料还高,在资料的传递过程中,较易产生误传。另又知识库(Knowledge Base)也不可少,因为在制程上的过去制造经验必须被储存,才能确实做到持久性的自发制造,此乃因制程上的情况是不可预期或随时可变的。而递增学习中的可塑性就是要用来对付制程可变性,一遇变化就重塑学习系统,但重塑可不能重新再学习已学过的东西(Things),否则就可能会使既有的学习结果失去稳定性,而造成制造过程的误判(不永续)。
锺云恭以机器老鼠跑迷宫为例指出,若用非递增式的学习方式,就须要至少完整地跑过一次,让机器老鼠可以从错误经验中学习,但递增学习则是边跑边学,只要答案正确,就给予奖励,就会愈学愈好,希望第一次边跑边学就能成功,不需要重新学习,如AlphaGo Zero就是递增学习的成功典范。
锺云恭指出,在自发性制造系统中,架设知识库系统的目的是:要使智能机器另外再能具有自行解释的能力,所以制程定义面的知识也就十分须要,因而若光有当今众所周知的单一(深度)学习机制自非最好,且也非愈深愈好,因为愈深的架构,有时候也会使记得愈多的记忆内容搞混!因此,建构一套具有递增学习机制的深度学习算法,将会使机器的在线实时(On-line Real Time)学习能力,产生无限可能。
此外,一套好的学习系统又并非只有深度的单一因素考虑,它还有高度、宽度、记住度、学习度、结构度、资料维度与其它多种学习参数的因素。深度学习与浅层学习相对,两者都并非全新的学习架构与方法,早在1975年,就已被提出研究。
事实上早有研究指出,只要资料维度不高且训练有素的机器,亦即:学习对象的特征其质量要有够必要(具有代表意义),训练的样本数也很充份(具有统计意义),那只有两层的隐藏神经元(多少要控制好),即足以有很高的辨识率,象是手写邮递区号的辨识,甚至制程上在制品(WIP)的正体印刷字,其辨识率更高,而此两例在当今云层(Cloud)计算中,又被分配(Distributed)到云雾(Fog)层内。此暗示:难到到处都要用深度学习吗?
锺云恭指出,工厂的资料是否真正复杂到需要一套深度学习系统,是业者必须要考量的重点,但能使机器去自发学习制程状况的递增式学习,却是基本需求;而且光是单机能做到递增学习还不够,因为整个工厂内机具、设备、物料在制造过程中,彼此间的资料传递会互相影响著产品生产的时间排程、空间运送、质量高低等等,故以资料趋动的自发性制造必须考虑整厂布局(Deployment)的方式,象是设备OEE维护计算,若机器各自只被各自的加工资料趋动来运算,那是否只能顾及单一设备的状况,而仍无法自发性管控生产进程与瓶颈降低呢?
锺云恭以特斯拉电动车生产为例,它的Model3无法顺利交货,产生资金周转不灵,就因未顾及整厂生产在线,上下游制造之间互相的影响情况,产生制造瓶颈,而使WIP堆积所致。故分配式的自发性机器学习系统在整厂内必须布局好,且上下游之间的资料传递能透明化,以达到各设备与物料之间的自发性协同操作(Autonomously Collaborative Operations)不间断,也才能好好让在各设备上的递增学习无误地在线实时进行,如此方能依照生产条件的改变,使整厂具调适自发特性(Adaptive Autonomy),而可自行规划出一套合适的生产流程,进而使工业4.0中的智能制造成为可能。
连接性、智能分析与自动化 为汽车工业4.0三大支柱

虽然汽车产业在自动化领域遥遥领先,但在大规模实施方面却远不如其它产业。法新社
许多汽车制造商开始以不同方式探索工业4.0的应用,麦肯锡(McKinsey)分析指出,汽车产业进入工业4.0时代的三大支柱,第一是实践连接性,能够实时向正确的人提供正确的数据。第二是智能或高级分析,根据拥有的庞大数据,让工业4.0技术帮助人类提高决策质量。第三是贯彻灵活的自动化。
据Automotive News报导,在连接性方面,企业应该思考如何从仰赖人类的旧知识与意见来做决策,转化到更多以事实为基础的方式做到预测性分析,是工业4.0的第一个支柱。此外,企业可以利用大数据、人工智能(AI)与机器学习来发展预测性分析,以更加了解问题的根源。
麦肯锡认为,工业4.0与1990年代的精益制造有相似之处,工业4.0当中的数码连接和协作的应用,可将性能的潜力推进到下一个程度,消除浪费、缩短时间,提高生产率与资产的有效性。
随著汽车产业面临退休潮和几十年来发展知识的丧失,数码化可以编纂知识并为现场技术人员提供远距支持,不再需要仰赖某人头脑中的东西。
汽车产业大致处于工业4.0采用的中间阶段,虽然汽车业在自动化领域遥遥领先,但是在其它方面例如数码连接和分析,在大规模实施解决方案方面的发展速度,却远不如其它产业。
工业4.0的发展进程如同其它工业革命一样,科技不断在进步,目前还没有一种真正成熟的最佳方式可以从数码化制造中获取价值。不过汽车产业已经从对工业4.0的质疑,走向在小范围应用内发现价值。而现在是开始扩展并实现工业4.0的时候,前方还有很长的路要走。
成为顶尖机器学习算法专家需要知道哪些算法?
来源:云栖社区
本文为你介绍机器学习算法及其分类,助你成为机器学习领域的专家。

机器学习算法简介
有两种方法可以对你现在遇到的所有机器学习算法进行分类。
第一种算法分组是学习风格的。
第二种算法分组是通过形式或功能相似。
通常,这两种方法都能概括全部的算法。但是,我们将重点关注通过相似性对算法进行分组。
通过学习风格分组的机器学习算法
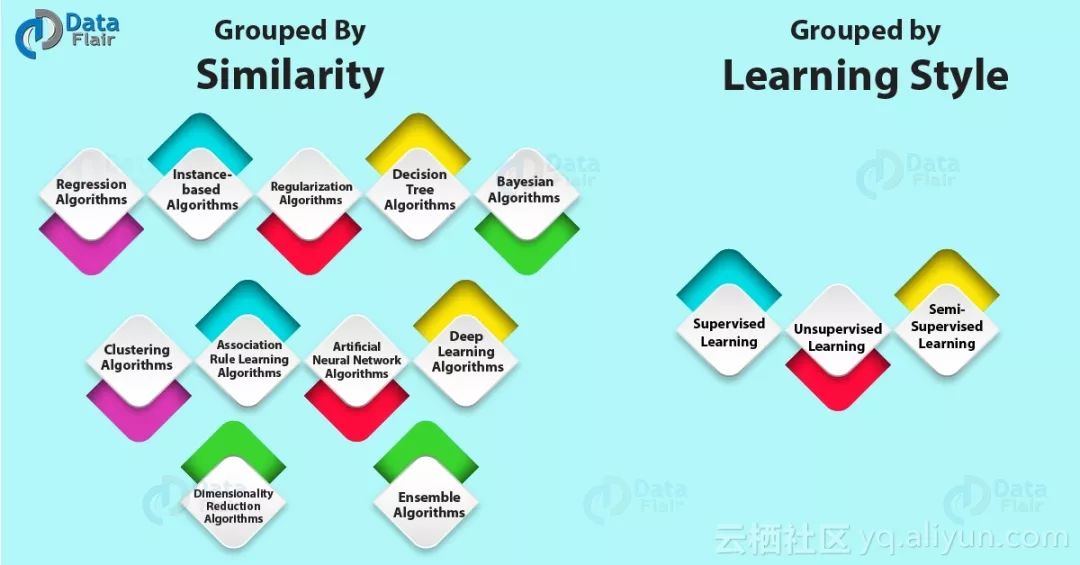
算法可以通过不同的方式对问题进行建模,但是,无论我们想要什么结果都需要数据。此外,算法在机器学习和人工智能中很流行。让我们来看看机器学习算法中的三种不同学习方式:
监督学习
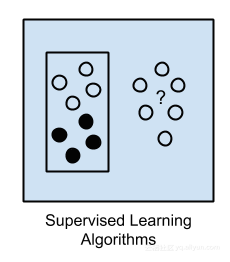
基本上,在监督机器学习中,输入数据被称为训练数据,并且具有已知的标签或结果,例如垃圾邮件/非垃圾邮件或股票价格。在此,通过训练过程中准备模型。此外,还需要做出预测。并且在这些预测错误时予以纠正。训练过程一直持续到模型达到所需水平。
示例问题:分类和回归。
示例算法:逻辑回归和反向传播神经网络。
无监督学习
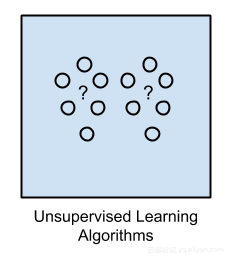
在无监督机器学习中,输入数据未标记且没有已知结果。我们必须通过推导输入数据中存在的结构来准备模型。这可能是提取一般规则,但是我们可以通过数学过程来减少冗余。
示例问题:聚类,降维和关联规则学习。
示例算法:Apriori算法和k-Means。
半监督学习
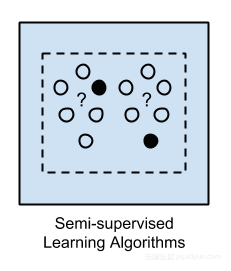
输入数据是标记和未标记示例的混合。存在期望的预测问题,但该模型必须学习组织数据以及进行预测的结构。
示例问题:分类和回归。
示例算法:其他灵活方法的扩展。
由功能的相似性分组的算法
ML算法通常根据其功能的相似性进行分组。例如,基于树的方法以及神经网络的方法。但是,仍有算法可以轻松适应多个类别。如学习矢量量化,这是一个神经网络方法和基于实例的方法。
回归算法
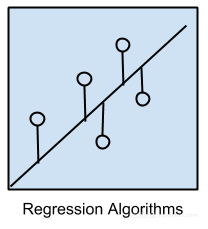
回归算法涉及对变量之间的关系进行建模,我们在使用模型进行的预测中产生的错误度量来改进。
这些方法是数据统计的主力,此外,它们也已被选入统计机器学习。最流行的回归算法是:
普通最小二乘回归(OLSR);
线性回归;
Logistic回归;
逐步回归;
多元自适应回归样条(MARS);
局部估计的散点图平滑(LOESS);
基于实例的算法
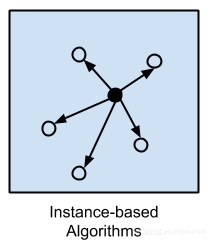
该类算法是解决实例训练数据的决策问题。这些方法构建了示例数据的数据库,它需要将新数据与数据库进行比较。为了比较,我们使用相似性度量来找到最佳匹配并进行预测。出于这个原因,基于实例的方法也称为赢者通吃方法和基于记忆的学习,重点放在存储实例的表示上。因此,在实例之间使用相似性度量。最流行的基于实例的算法是:
k-最近邻(kNN);
学习矢量量化(LVQ);
自组织特征映射(SOM);
本地加权学习(LWL);
正则化算法
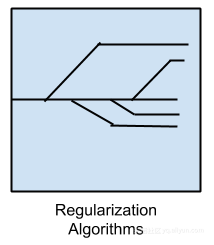
我在这里列出了正则化算法,因为它们很流行,功能强大。并且通常对其他方法进行简单的修改,最流行的正则化算法是:
岭回归;
最小绝对收缩和选择算子(LASSO);
弹性网回归;
最小角回归(LARS);
决策树算法
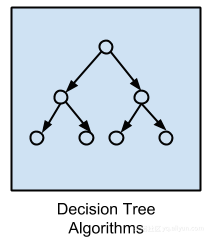
决策树方法用于构建决策模型,这是基于数据属性的实际值。决策在树结构中进行分叉,直到对给定记录做出预测决定。决策树通常快速准确,这也是机器学习从业者的最爱的算法。最流行的决策树算法是:
分类和回归树(CART);
迭代Dichotomiser 3(ID3);
C4.5和C5.0(强大方法的不同版本);
卡方自动交互检测(CHAID);
决策树桩;
M5;
条件决策树;
贝叶斯算法
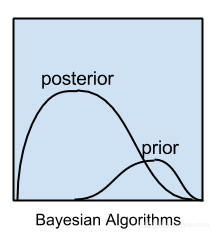
这些方法适用于贝叶斯定理的问题,如分类和回归。最流行的贝叶斯算法是:
朴素贝叶斯;
高斯朴素贝叶斯;
多项朴素贝叶斯;
平均一依赖估计量(AODE);
贝叶斯信念网络(BBN);
贝叶斯网络(BN);
聚类算法
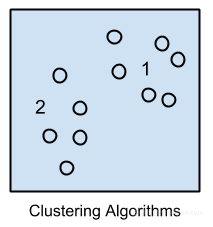
几乎所有的聚类算法都涉及使用数据中的固有结构,这需要将数据最佳地组织成最大共性的组。最流行的聚类算法是:
K-均值;
K-平均;
期望最大化(EM);
分层聚类;
关联规则学习算法
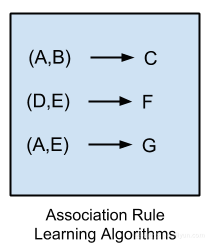
关联规则学习方法提取规则,它可以完美的解释数据中变量之间的关系。这些规则可以在大型多维数据集中被发现是非常重要的。最流行的关联规则学习算法是:
Apriori算法;
Eclat算法;
人工神经网络算法
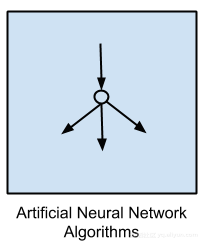
这些算法模型大多受到生物神经网络结构的启发。它们可以是一类模式匹配,可以被用于回归和分类问题。它拥有一个巨大的子领域,因为它拥有数百种算法和变体。最流行的人工神经网络算法是:
感知机;
反向传播;
Hopfield神经网络;
径向基函数神经网络(RBFN)
深度学习算法
深度学习算法是人工神经网络的更新。他们更关心构建更大更复杂的神经网络。最流行的深度学习算法是:
深玻尔兹曼机(DBM);
深信仰网络(DBN);
卷积神经网络(CNN);
堆叠式自动编码器;
降维算法
与聚类方法一样,维数减少也是为了寻求数据的固有结构。通常,可视化维度数据是非常有用的。此外,我们可以在监督学习方法中使用它。
主成分分析(PCA);
主成分回归(PCR);
偏最小二乘回归(PLSR);
Sammon Mapping;
多维缩放(MDS);
投影追踪;
线性判别分析(LDA);
高斯混合判别分析(MDA);
二次判别分析(QDA);
费舍尔判别分析(FDA);
常用机器学习算法列表

朴素贝叶斯分类器机器学习算法
通常,网页、文档和电子邮件进行分类将是困难且不可能的。这就是朴素贝叶斯分类器机器学习算法的用武之地。分类器其实是一个分配总体元素值的函数。例如,垃圾邮件过滤是朴素贝叶斯算法的一种流行应用。因此,垃圾邮件过滤器是一种分类器,可为所有电子邮件分配标签“垃圾邮件”或“非垃圾邮件”。基本上,它是按照相似性分组的最流行的学习方法之一。这适用于流行的贝叶斯概率定理。
K-means:聚类机器学习算法
通常,K-means是用于聚类分析的无监督机器学习算法。此外,K-Means是一种非确定性和迭代方法,该算法通过预定数量的簇k对给定数据集进行操作。因此,K-Means算法的输出是具有在簇之间分离的输入数据的k个簇。
支持向量机学习算法
基本上,它是用于分类或回归问题的监督机器学习算法。SVM从数据集学习,这样SVM就可以对任何新数据进行分类。此外,它的工作原理是通过查找将数据分类到不同的类中。我们用它来将训练数据集分成几类。而且,有许多这样的线性超平面,SVM试图最大化各种类之间的距离,这被称为边际最大化。
SVM分为两类:
线性SVM:在线性SVM中,训练数据必须通过超平面分离分类器。
非线性SVM:在非线性SVM中,不可能使用超平面分离训练数据。
Apriori机器学习算法
这是一种无监督的机器学习算法。我们用来从给定的数据集生成关联规则。关联规则意味着如果发生项目A,则项目B也以一定概率发生,生成的大多数关联规则都是IF_THEN格式。例如,如果人们购买iPad,那么他们也会购买iPad保护套来保护它。Apriori机器学习算法工作的基本原理:如果项目集频繁出现,则项目集的所有子集也经常出现。
线性回归机器学习算法
它显示了2个变量之间的关系,它显示了一个变量的变化如何影响另一个变量。
决策树机器学习算法
决策树是图形表示,它利用分支方法来举例说明决策的所有可能结果。在决策树中,内部节点表示对属性的测试。因为树的每个分支代表测试的结果,并且叶节点表示特定的类标签,即在计算所有属性后做出的决定。此外,我们必须通过从根节点到叶节点的路径来表示分类。
随机森林机器学习算法
它是首选的机器学习算法。我们使用套袋方法创建一堆具有随机数据子集的决策树。我们必须在数据集的随机样本上多次训练模型,因为我们需要从随机森林算法中获得良好的预测性能。此外,在这种集成学习方法中,我们必须组合所有决策树的输出,做出最后的预测。此外,我们通过轮询每个决策树的结果来推导出最终预测。
Logistic回归机器学习算法
这个算法的名称可能有点令人困惑,Logistic回归算法用于分类任务而不是回归问题。此外,这里的名称“回归”意味着线性模型适合于特征空间。该算法将逻辑函数应用于特征的线性组合,这需要预测分类因变量的结果。
结论
我们研究了机器学习算法,并了解了机器学习算法的分类:回归算法、基于实例的算法、正则化算法、决策树算法、贝叶斯算法、聚类算法、关联规则学习算法、人工神经网络算法、深度学习算法、降维算法、集成算法、监督学习、无监督学习、半监督学习、朴素贝叶斯分类器算法、K-means聚类算法、支持向量机算法、Apriori算法、线性回归和Logistic回归。熟悉这类算法有助你成为机器学习领域的专家!

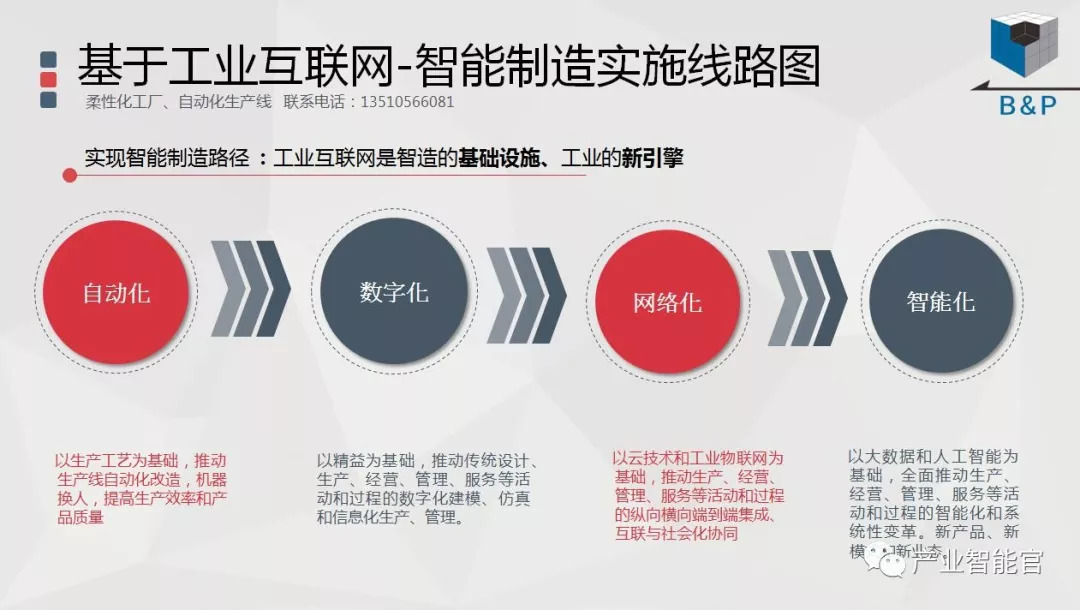
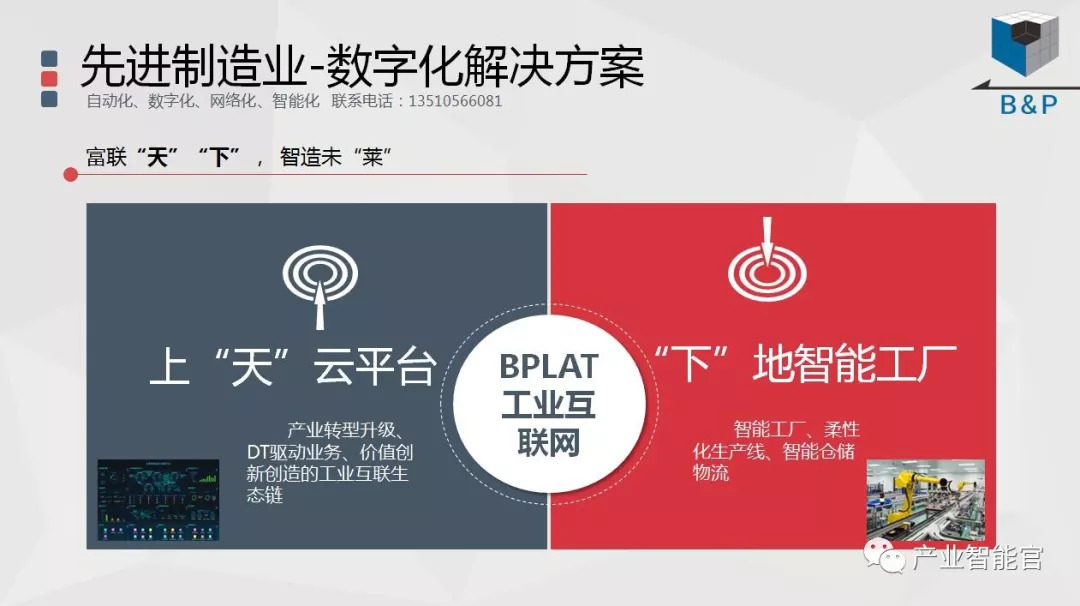
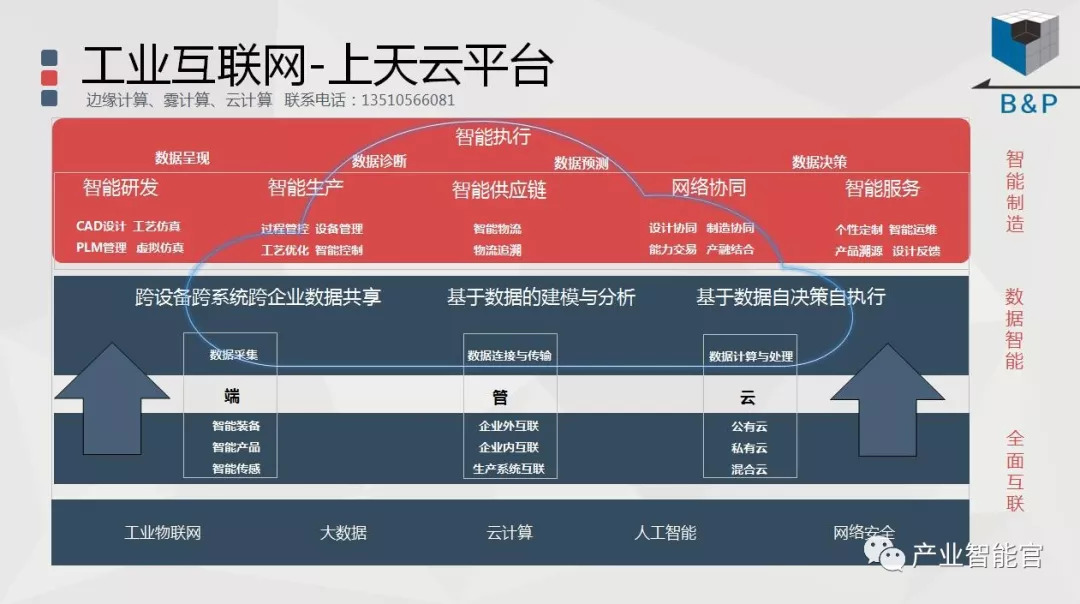
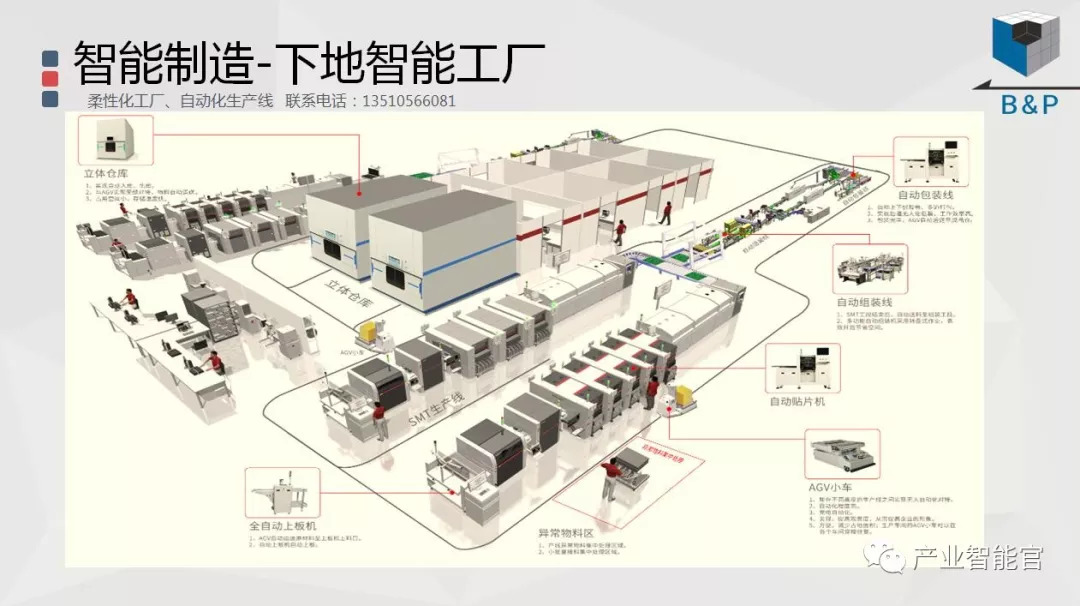
工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。



