阿里双11数据库计算存储分离与离在线混布
“如何做到支撑32.5万笔/秒交易的同时降低数据库成本?”
一、背景
随着阿里集团电商、物流、大文娱等业务的蓬勃发展,数据库实例以及数据存储规模不断增长,在传统基于单机的运维以及管理模式下,遇到非常多的困难与挑战,主要归结为:
l 机型采购与预算问题
在单机模式下计算资源(CPU和内存)与存储资源(主要为磁盘或者SSD)存在着不可调和的冲突;计算与存储资源绑定紧密,无法进行单独预算。数据库存储时,要么计算资源达到瓶颈,要么是存储单机存储容量不足。这种绑定模式下,注定了有一种资源必须是浪费的。
l 调度效率问题
在计算与存储绑定的情况下,计算资源无法做无状态调度,导致无法实现大规模低成本调度,也就无法与在大促与离线资源进行混布。
l 大促成本问题
在计算资源无法做到调度后,离线混布就不再可能;为了大促需要采购更多的机器,大促成本上涨严重。
因此,为了解决诸多如成本,调度效率等问题,2017年首次对数据库实现计算存储分离;计算存储分离后,再将计算节点与离线资源混布,达到节省大促成本的目的。
2017年数据库计算存储分离,
使得数据库进行大规模无状态化容器调度成为可能!
使得数据库与离线业务混布成为可能!
使得低成本支持大促弹性成为可能!
在高吞吐下,总存储集群整体RT表现平稳,与离线资源联合首次发力,最终完美完成2017年“11.11”大促10%的交易支撑;
并为明年全面拥抱计算存储分离与大规模离在线混布,打下坚实的基础。
二、计算存储分离
在所有业务中,数据库的计算存储分离最难,这是大家公认的。因为数据库对于存储的稳定性以及单路端到端的时延有着极致的要求:
1. 存储稳定性
在分布式存储的稳定性方面,我们做了非常多的有意探索,并且逐一落地。这些新技术的落地,使得数据库计算存储分离成为可能:
l 单机failover
单机failover我们做到业界的极致,5s内完成fo,对整体集群的影响在4%以内(以集群规模24台为例,集群机器越多,影响越小)。另外,我们对分布式存储的状态机进行加速优化,使得基于paxos的选举在秒级内进行集群视图更新推送。
l 长尾时延优化
计算存储分离后,所有的IO都变成了网络IO,因此对于单路IO时延影响的因素非常多,如网络抖动,慢盘,负载等,而这些因素也是不可避免的。我们设计了“副本达成多数写入即返回的策略(commit majority feature)”,能够有效地使长尾时延抖动做到合理的控制,以满足业务的需求。
以下是commit majority feature开起前后的效果对比。其中“蓝色”为优化后的长尾时延,“红色”为优化前长尾时延,效果非常显著。
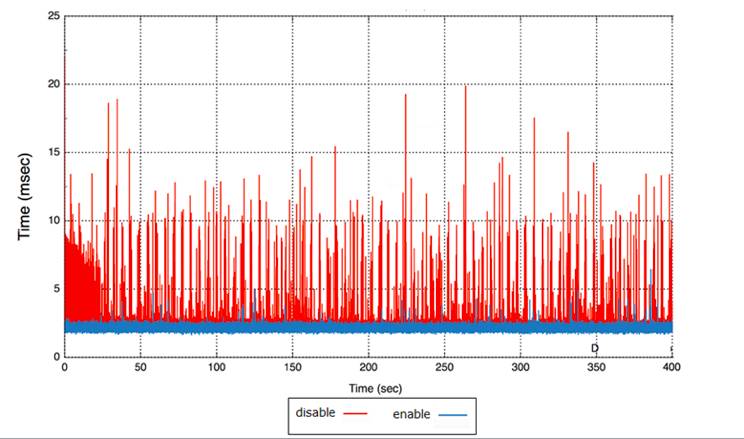
l 流控
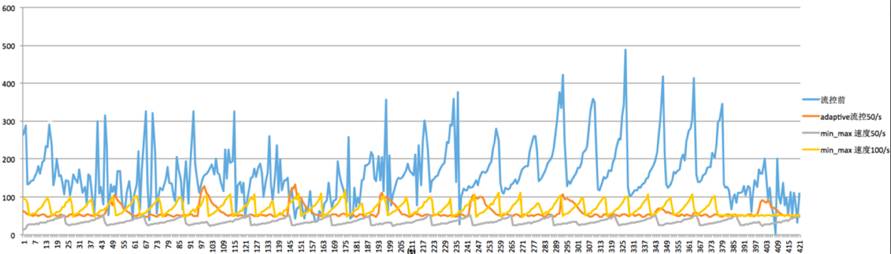
我们实现了基于滑动窗口的流控功能,使得集群后台活动(如backfill和recovery)能根据当前的业务流量进行自适配的调整,在业务与后台数据恢复之间做到最佳平衡。
一般如果集群后端活动太低,会影响数据恢复,这会提高多盘故障的概率,降低了数据的可靠性。我们经过优化后,通过滑动窗口机制,做到了前后端数据写入的速动,在不影响业务写入的情况下,尽最大可能提高数据恢复速度,保证多副本数据的完整性。
提高数据重平衡的速度,也是为了保证整个集群的性能。因为一出现数据倾斜时,部分盘的负载将变大,从而会影响整个集群的时延和吞吐。
流控效果如下:
l 高可用部署
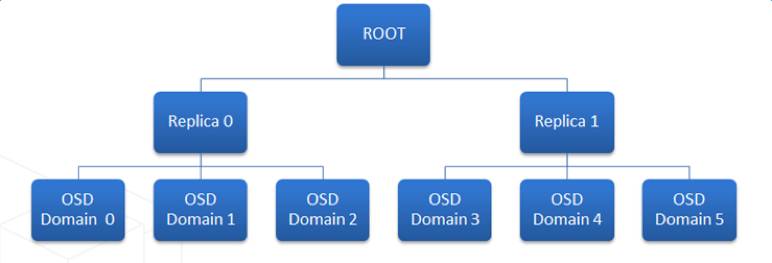
在高可用部署上,我们引入的故障域的概念。多个数据副本存储在多个故障域,分布到至少4个RACK以上的机架上,用于保障底层机柜电源以及网络交换设备引起的故障等。
为了能够更好的理解数据副本存储位置(data locality),需要知道数据散射度(scatter width)的概念。怎么来理解数据散射度?
举个例子:我们定义三个copy set(存放的都是不同的数据):{1,2,3},{4,5,6},{7,8,9}。任意一组copy set中存放的数据没有重复,也就是说一份数据的三个副本分别放置在:{1,4,7}或者{2,5,8}或者{3,6,9}。那么这个时候,其数据散射度远小于随机组合的C(9,3)。
随机组合时,任意3台机器Down机都会存在数据丢失。而采用此方案后,只有当{1,4,7}或者{2,5,8}或者{3,6,9}其中的任意一个组合不可用时,才会影响高可用性,才会有数据丢失。
综上可知,我们引入copy set的目标就是尽量的降低数据散射度“S“。下图中两组replica set,其中每一组的三个副本分别放置到不同的RACK中。
我们的优化还有很多,这里不再一一列举。
2. 数据库吞吐优化
当所有的IO都变成网络IO后,我们要做的就是如何减少单路IO的延迟,当然这个是分布式存储以及网络要解的问题。
分布式存储需要优化自身的软件stack以及底层SPDK的结合等。
而网络层则需要更高带宽以及低时延技术,如25G TCP或者25G RDMA,或者100G等更高带宽的网络等。
但是我们可以从另外一个角度来考虑问题,如何在时延一定的情况下,提高并发量,从而来提高吞吐。或者说在关键路径上减少IO调用的次数,从而从某种程度上提高系统的吞吐。
大家知道,影响数据库事务数的最关键因素就是事务commit的速度,commit的速度依赖于写REDO时的IO吞吐。所谓的REDO也就是大家熟知的WAL(Write Ahead Log)日志。
在脏数据flush回存储时,日志必须先落地,这是因为数据库的Crash Recovery是重度以来于此的。在recovery阶段,数据库先利用redo进行roll forward;再利用undo进行roll backward,最后再撤销用户未提交的事务。
因此,存储计算分离下,要想在单路IO时延一定时提高吞吐,就必须要优化commit提交时的效率。我们通过优化redo的写入方式,让整个提高吞吐100%左右,效果如下:
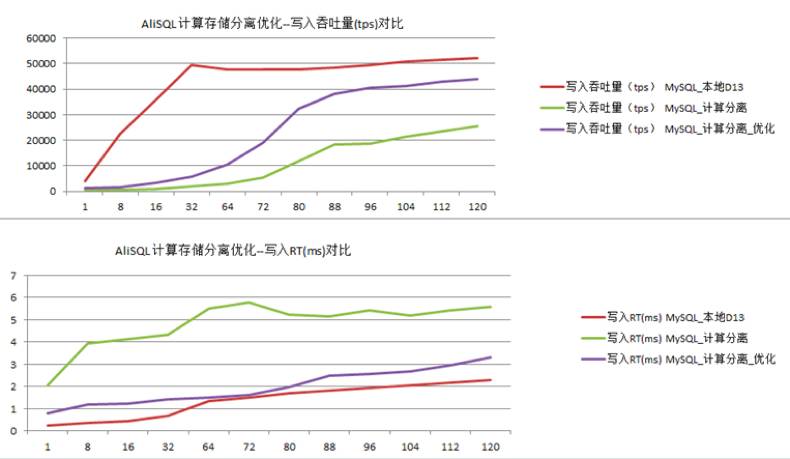
另外,也可以优化redo group commit的大小,结合底层存储stripe能力,做并发与吞吐优化。
备注:”D13”是一种已经做过raid的SATASSD
3. 数据库原子写
在数据库内存模型中,数据页通常是以16K做为一个bufferpage来管理的。当内核修改完数据之后,会有专门的“checkpoint”线程按一定的频率将Dirty Page flush到磁盘上。我们知道,通常os的page cache是4K,而一般的文件系统block size也是4K。所以一个16k和page会被分成4个4k的os filesystem block size来存储,物理上不能保证连续性。
那么会带来一个严重的问题,就是当fsync语义发出时,一个16k的pageflush,只完成其中的8k,而这个时候client端crash,不再会有重试;那么整个fsync就只写了一半,fsync语义被破坏,数据不完整。上面的这个场景,我们称之为“partial write”。
对于MySQL而言,在本地存储时,使用Double Write Buffer问题不大。但是如果底层变成网络IO,IO时延变高时,会使MySQL的整体吞吐下降,而Double Write Buffer会加重这个影响。
我们实现了原子写,关闭掉Double Write Buffer,从而在高并发压力及高网络IO时延下,让吞吐至少提高50%以上。
4. 网络架构升级
分布式存储,对于网络的带宽要求极高,我们引入了25G网络。高带宽能更好的支持阿里集团的大促业务。另外,对于存储集群后台的活动,如数据重平衡以及恢复都提供了有力的保障。
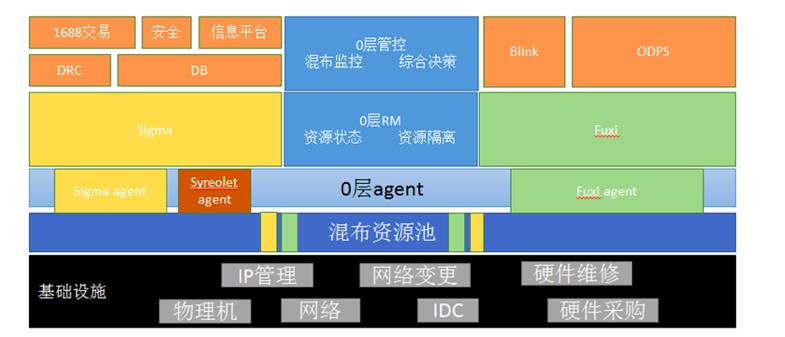
三、离在线混布
计算存储分离后,离在线混布成为可能;今年完成数据库离在线混布,为2017年大促节省了计算资源成本。
在与离线混布的方案中,我们对数据库与离线任务混跑的场景进行了大量的测试。
实践证明,数据库对时延极度敏感,所以为了达到数据库混布的目的,我们采用了以下的隔离方案:
l CPU与内存隔离技术
CPU的L3是被各个核共享的,如果在一个socket内部进行调度,会对数据库业务有抖动。因此,在大促场景下,我们会对CPU进行独立socket 绑定,避免L3 cache干扰;另外,内存不超卖。当然,大促结束后,在业务平峰时,可以择机进行调度和超卖。
l 网络QOS
我们对数据库在线业务进行网络打标,NetQoS中将数据库计算节点的所有通信组件加入到高优先级group中。
l 基于分布式存储的弹性效率
基于分布式存储,底层分布式存储支持多点mount,用于将计算节点快速弹性到离线机器。
另外,数据库Buffer Pool可以进行动态扩容。大促ODPS任务撤离,DB实例Buffer Pool扩容;大促结束后,Buffer Pool回缩到平峰业务时的大小。
以下是今年离在线混布的部署图:
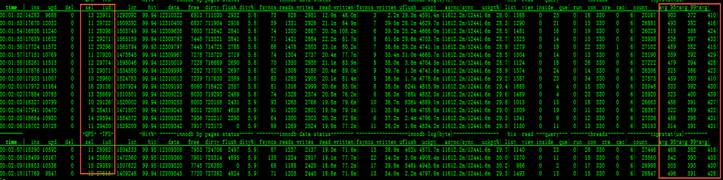
四、双11大促求证
我们拿了其中一个中等压力的数据库的业务,其吞吐达到将近3w tps,RT在1ms以内,基本上与本地相当,很好的支撑了2017年大促。
这就是我们今年所做的诸多技术创新的结果。
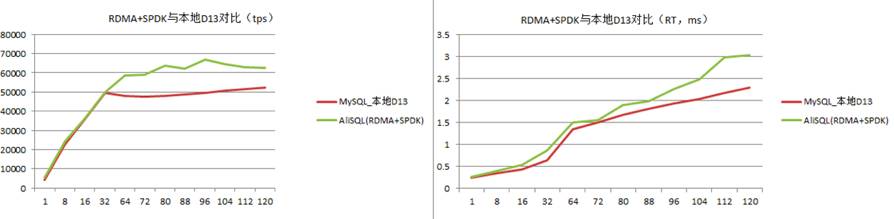
五、展望
目前我们正在进行软硬件结合(RDMA,SPDK)以及上层数据库引擎与分布式存储融合优化,性能将会超出传统SATA SSD本地盘的性能。
RDMA和SPDK的特点就是kernel pass-by。未来,我们数据库将引入全用户态IO Stack,从计算节点到存储节点使用用户态技术,更能充分满足集团电商业务对高吞吐低时延的极致要求。
下面是我们进行测试的一组数据,其中本地用的是SATA SSD,并且做了raid,但是其性能略低于基于RDMA和SPDK的分布式存储。
这些网络和硬件技术的发展,将会给“云计算”带来更多的可能性,也会给真正的“云计算”新的商业模式带来更多憧憬,而我们已经在这条阳光的大道上。
欢迎有更多的存储及数据库内核专家一起参与进来,一起携手迈进未来。
【引用】
[1] Copysets:Reducing the Frequency of Data Loss in Cloud Storage
[2] CRUSH: Controlled,Scalable, Decentralized Placement of Replicated Data
作者:
吕建枢,阿里巴巴数据库事业部技术专家。





