基于VGG19的识别中国人、韩国人、日本人分类器

向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT数据分析 公众号: datadw
这是本学期机器学习课程的项目。通过这个项目了解了不少东西,希望通过博客记录下整个项目过程。
国外有一个网站
http://www.alllooksame.com/
上有一个非常有趣的测试,他们在街头收集了一共18名中国人、韩国人、日本人的照片,放在网站上,让人去识别。博主自己尝试过一次,18个对了7个,38%的正确率,跟猜的概率并没有相差太多,恰好刚在学习深度学习一些模型,了解到可以通过深度的学习模型构建分类器去识别。在一时冲动之下,有了这个项目。废话不多说,直接开始博主完成整个项目的过程。
数据集构造
网上没有找到现成的数据集,甚至没有找到单纯包含中国人或者日本人或者韩国人的数据库。遂决定自己构造数据集,能够想到的办法就只能从当地的官方网站(譬如政府、学校等等)收集图片作为我们的训练集。在一番折腾之后,得到具体数据集情况如下:
| 名称 | 数据来源 | 样本数目 |
|---|---|---|
| 中国人 | 政府网站、明星、老师、学生 | 483 |
| 日本人 | 政府网站、明星、老师、学生 | 407 |
| 韩国人 | 408 |
ps:这里我们韩国人的数据存在问题,因为直接来源于Google,真实性不如收集到的中国人和日本人,很可能原始标记就存在问题。
人脸检测
人脸检测,我们主要使用的是Haar分类器,这个分类器原理在这篇博文中介绍的很仔细。http://www.cnblogs.com/ello/archive/2012/04/28/2475419.html
主要的步骤包括:
1)使用Haar-like特征做检测;
2)使用积分图(Integral Image)对Haar-like特征求值进行加速;
3)使用AdaBoost算法训练区分人脸和非人脸的强分类器;
4)使用筛选式级联把强分类器级联到一起,提高准确率。本文直接在python使用opencv提供的接口,顺利完成了人脸检测。效果如下:
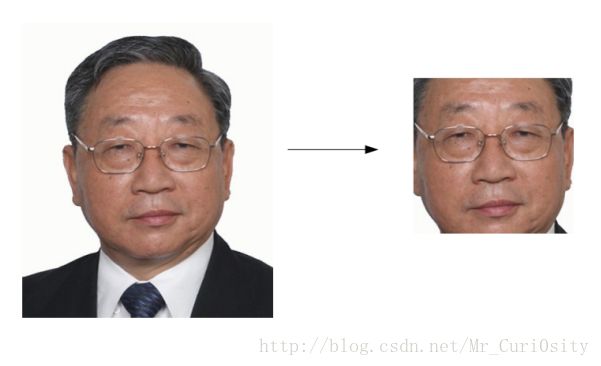
学长说这样的人脸检测会丢失很多有用的信息,要在人脸检测之后做一些人脸补全的工作,目前还不知道怎么弄,先码着,等期末结束之后有空了再来折腾一下。
具体做法的代码参照这篇博文,修改了一下。
https://blog.csdn.net/u012162613/article/details/43523507
数据集增强
因为收集到的数据非常有限,三种人种一起才1290张。考虑到深度学习在数量足够多的时候才有更好的效果,我们这里计划改变数据的亮度、饱和度、对比度、锐度、旋转一个小角度做一个数据增强。下面使我们做数据集增强的方法:
饱和度
这里直接调用了ImageEnhance模块的Color类,其中random_factor是一个随机变量。random_factor=1的时候为原图,random_factor越大饱和度越大。
亮度
这里直接调用了ImageEnhance模块的Brightness类,其中random_factor是一个随机变量。random_factor=1的时候为原图,random_factor越大饱和度越大。
对比度
这里直接调用了ImageEnhance模块的Contrast类,其中random_factor是一个随机变量。random_factor=1 的时候为原图,random_factor越大饱和度越大。
锐度
这里直接调用了ImageEnhance模块的Sharpness类,其中random_factor是一个随机变量。random_factor=1 的时候为原图,random_factor越大饱和度越大。

这里主要是参考了这边博文。
http://blog.csdn.net/icamera0/article/details/50753705
旋转角度
改变旋转角度同样也可以做数据增强。
下图是博主两次做数的两次数据增强。左边是没有任何经验,完全随机的做出来的数据集增强,右边是学长指导之后做出来的增强结果,把这两个数据集在博主训练得到最好的分类器上面跑,左边只有86%左右的正确率,右边却达到了94%左右的正确率。 
左边主要存在的问题是,数据增强的幅度过大,导致图片有点失真(跟正常相机拍出来的相差太大);随机调整的角度也过大;这两种方式得到的照片跟实际相差太大,没有很大的实际应用价值。Ps:学长还说,在实际工作中,添加随机噪声得到的数据集没有价值。。。目前还没有弄明白为啥,先码着。
下面是我得到右边数据集的代码:
构造分类器
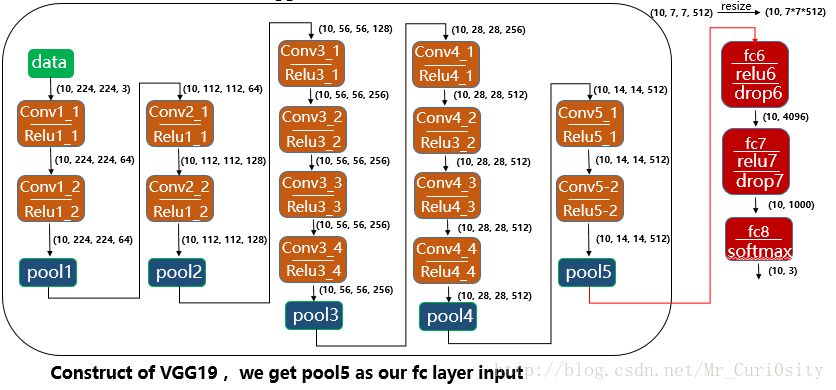
博主在深度学习课程中的老师讲到:在我们想利用深度模型做图片分类器的时候,可以考虑将图片先在ImageNet上面训练好的模型跑,截取某一层的特征图构建全连接的神经网构建分类器。基于这个思想,博主使用VGG19,截取最后一个pooling层,然后构造一个全连接的神经网络作为分类器。结构如下图所示:
因为VGG对输入图片有要求,在放入VGG模型之前首先对图片进行了如下处理:将RGB转换成BGR
将图片resize成为224*224*3
图片中每一个pixel减去在ImageNet上训练的平均值(出于改善模型结果的考虑)
在Batch size = 16、#training = 1082、#validation = 16、 #test = 200、 Dropout = 1时训练上述分类器得到正确率随着训练步数的变化如下: 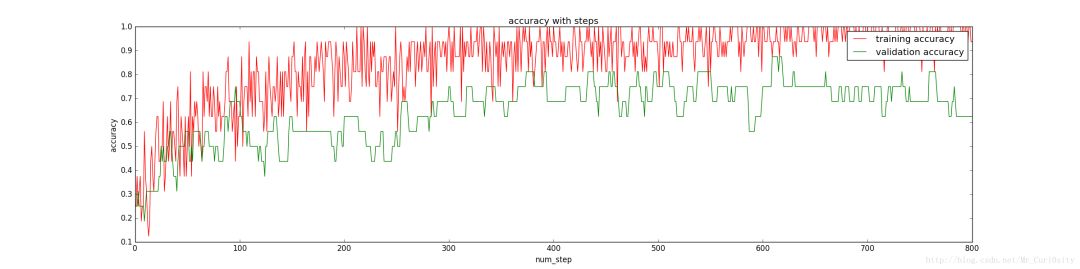
发现训练集上面的正确率接近100%,然而验证集上面的正确率却58%,显然出现了过拟合,为了避免过拟合,提高泛化能力,我们队对参数进行调整。
这里图像波动很大,因为我们的batch_size只有16,若batch_size大一些,图像会更加平滑一点,但是总体局势还是能够反映的。
参数调整
首先尝试了不同的drop out,得到在drop_out = 0.5 的时候结果比较好,正确率为70%;然后做了,上述左边的数据集增强,得到了79%的正确率,一次比较大的提升;在尝试了权重衰减系数,得到在weight_decay = 0.0003的时候有81%的正确率。最后尝试了Batch Normalization,在没有drop out和weight decay情况下,得到了86%的正确率。随后在学长的意见上改变了数据增强的方式,得到一个最终94%的正确率。
https://blog.csdn.net/mr_curi0sity/article/details/72927941
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注



