干货实践 | 计算机视觉花卉识别模型(代码分享)
摘要:用机器学习自动识花
关键词:Python 机器学习 计算机视觉
文末可领福利~

前几天,想必大家都忙着过女神节,但送礼物这件事情还是让不少直男苦恼,口红色号那么多,花还有那么多品种,一个不小心选错就容易踏入雷区,下面就教大家用机器学习来识别各种花。

“什么是机器学习和计算机视觉?”
计算机视觉是一门让计算机替你“看”的科学。机器学习,就是实现计算机视觉的一种工具和方法,它可以从数据中挖掘出规律,并用于预测或者分类。识别花卉的过程就是让计算机替你识别分类。
*以下完整代码,文末都有免费获取方式
Part.1
寻找一个合适的模型
实现学习和分类,我们可以采用神经网络模型。神经元的结构如下:
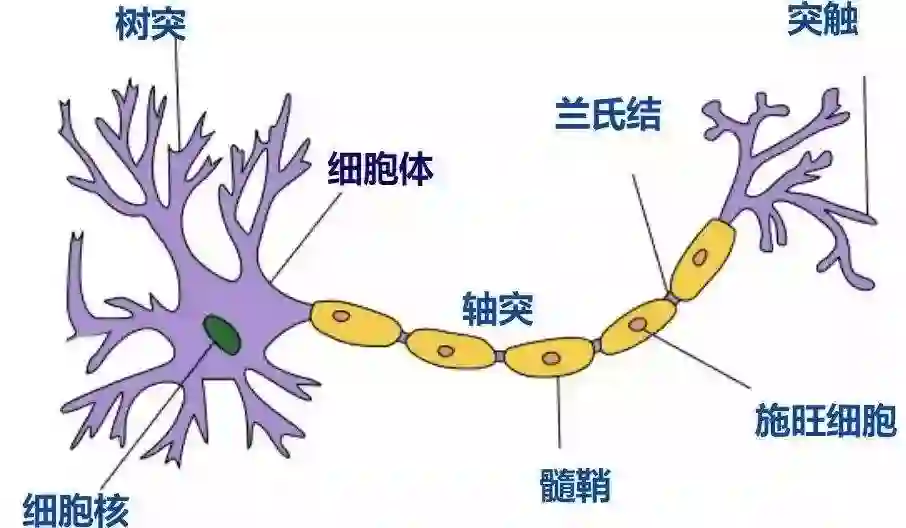
笼统说就是输入信号——处理——输出对应信号,而神经网络模型就是模仿了这一工作过程:
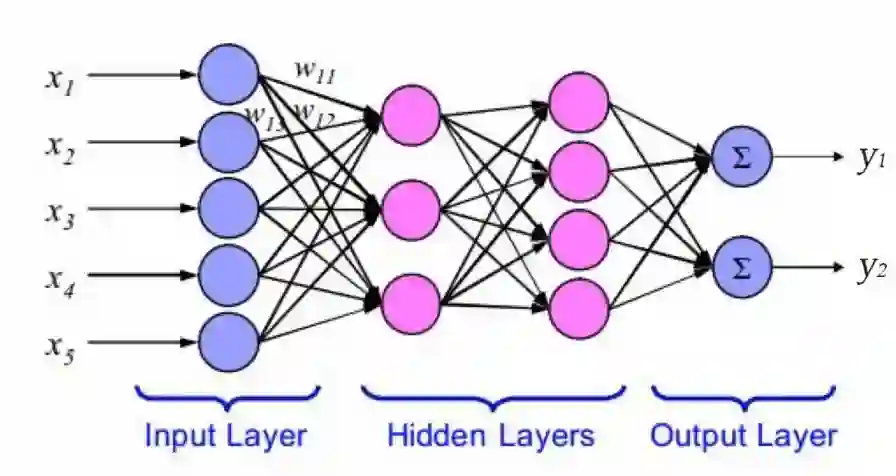
1. 每个神经元都接受来自其它神经元的输入信号,每个信号都通过一个带有权重的连接传递;
2. 神经元把这些信号加起来得到一个总输入值;
3. 将总输入值与神经元的阈值进行对比(模拟阈值电位);
4. 通过一个“激活函数”处理得到最终的输出(模拟细胞的激活),这个输出又会作为之后神经元的输入一层一层传递下去。
如何让机器能够准确识别花的品种?很简单,一遍一遍反复的学习,直到能认准为止。“一遍一遍反复学习”这一行为,我们称之为深度学习。
学习要讲究方法,比如如何区分玫瑰和蒲公英,很简单,玫瑰一般为红色,花朵是卷起来的,而蒲公英大多为球状。这种提取特征的学习方法,我们通常称之为卷积。
知道了让计算机学习的基本原理,接下来就是让它为我们所用。
Part.2
花卉素材准备
如果想要认识各种花卉,首先要掌握每种花的特征。所以,我们先准备一些学习的素材:

*大家可以在CSDN等技术网站搜集训练素材
这么多图片,一部分将用来作为训练集,另一部分数据会用来测试已经训练好模型的精确度。
训练集(Training Set):帮助我们训练模型,简单的说就是通过训练集的数据让我们确定拟合曲线的参数。
测试集(Test Set):用来测试已经训练好的模型的精确度。
测试的精确度越高越好吗?
并不是,如果模型在测试集上表现得越来越好,训练集表现却越来越差,就会过拟合。
欠拟合指模型没有很好地捕捉到数据特征,不能够很好地拟合数据:
过拟合通俗一点地说就是模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,即不能正确的分类,模型泛化能力太差:
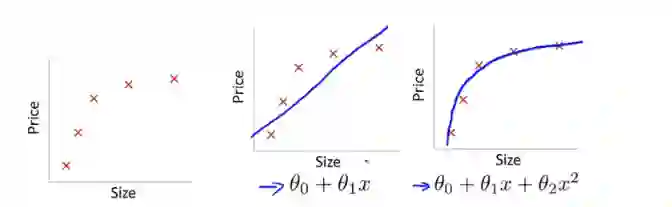

欠拟合和过拟合都不是好事情,这是我们判断该不该继续训练的重要指标。
Part.3
搭建模型
这一部分是我的模型实现过程,有些步骤就不再详细讲解,想免费获取完整代码和学习资料的同学们可以移步文末。
构建训练集模块和测试集模块:
train_datagen = ImageDataGenerator(
rotation_range = 40, # 随机旋转度数
width_shift_range = 0.2, # 随机水平平移
height_shift_range = 0.2,# 随机竖直平移
rescale = 1/255, # 数据归一化
shear_range = 20, # 随机错切变换
zoom_range = 0.2, # 随机放大
horizontal_flip = True, # 水平翻转
fill_mode = 'nearest', # 填充方式
)
test_datagen = ImageDataGenerator(
rescale = 1/255, # 数据归一化
)
在训练集中我们定义了旋转,平移,缩放等功能,这样可以让我们的模型学习旋转、跳跃、闭着眼的花花图片,增加样本使用效率和模型准确度。

然后,开始搭建神经网络:
model = Sequential() #创建一个神经网络对象
#添加一个卷积层,传入固定宽高三通道的图片,以32种不同的卷积核构建32张特征图,
# 卷积核大小为3*3,构建特征图比例和原图相同,激活函数为relu函数。
model.add(Conv2D(input_shape=(IMG_W,IMG_H,3),filters=32,kernel_size=3,padding='same',activation='relu'))
#再次构建一个卷积层
model.add(Conv2D(filters=32,kernel_size=3,padding='same',activation='relu'))
#构建一个池化层,提取特征,池化层的池化窗口为2*2,步长为2。
model.add(MaxPool2D(pool_size=2,strides=2))
#继续构建卷积层和池化层,区别是卷积核数量为64。
model.add(Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'))
model.add(Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'))
model.add(MaxPool2D(pool_size=2,strides=2))
#继续构建卷积层和池化层,区别是卷积核数量为128。
model.add(Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'))
model.add(Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'))
model.add(MaxPool2D(pool_size=2, strides=2))
model.add(Flatten()) #数据扁平化
model.add(Dense(128,activation='relu')) #构建一个具有128个神经元的全连接层
model.add(Dense(64,activation='relu')) #构建一个具有64个神经元的全连接层
model.add(Dropout(DROPOUT_RATE)) #加入dropout,防止过拟合。
model.add(Dense(CLASS,activation='softmax')) #输出层,一共14个神经元,对应14个分类
为了方便观察模型,绘制一个网络结构图如下:

可下滑查看完整模型结构图
生成训练集和测试集的迭代器,用于把图片按一定批次大小传入模型训练:
train_generator = train_datagen.flow_from_directory( #设置训练集迭代器
TRAIN_PATH, #训练集存放路径
target_size=(IMG_W,IMG_H), #训练集图片尺寸
batch_size=BATCH_SIZE #训练集批次
)
test_generator = test_datagen.flow_from_directory( #设置测试集迭代器
TEST_PATH, #测试集存放路径
target_size=(IMG_W,IMG_H), #测试集图片尺寸
batch_size=BATCH_SIZE, #测试集批次
)
*如果对代码和复杂的结构图过敏,文末提供完整代码和学习资料,包学包会。
Part.4
模型训练过程
一开始准确率是很低的,只有7%,约等于1/14,完全随机:

一段时间以后,训练超过200个周期,准确率就开始上升了,达80%:

而400个周期以后:

训练集准确率大于90%,而测试集准确率约84%。如果继续训练,训练集准确率还能再提高,但测试集准确率几乎提高不了。
这就是上文提到的过拟合,应该停止训练了。
Part.5
结果展示
模型训练好了,我们可以采用实际的案例来测试下效果:

*文末分享测试用图
用一个简单的脚本来导入训练好的模型,再把用于预测的图片转换成模型的对应格式:
from keras.models import load_model
from keras.preprocessing.image import img_to_array,load_img
import numpy as np
import os
# 载入模型
model = load_model('flower_selector.h5')
label = np.array(['康乃馨','杜鹃花','桂花','桃花','梅花','洛神花','牡丹','牵牛花','玫瑰','茉莉花','荷花','菊花','蒲公英','风信子'])
def image_change(image):
image = image.resize((224,224))
image = img_to_array(image)
image = image/255
image = np.expand_dims(image,0)
return image
遍历文件夹下的图片进行预测:
for pic in os.listdir('./predict'):
print('图片真实分类为',pic)
image = load_img('./predict/' + pic)
image = image_change(image)
print('预测结果为',label[model.predict_classes(image)])
print('----------------------------------')
结果如下(可以上下滑动查看):

预测准确率达到百分之百!!!!
想要学会这一手技能,现在送出计算机视觉免费福利~有趣、有答疑、有内容还免费的直播课+操作课,还有限时赠送的学习大礼包!现在加入,下回就可以自己动手来识别口红色号。
福利有限,手慢无:
Part.1
免费直播课
直播主题:
如何攻破人工智能技术门槛?
3月13日 周三 19:00
直播大纲:
1. 步入AI,为什么选择计算机视觉方向?
2. 技术剖析,小白需要掌握哪些知识&技能?
3. 从零开始学习AI技术的成长建议(干货)
直播讲师:

大鹏 “城市数据团联合发起人”
网易云课堂微专业特邀讲师
Part.2
实操体验课

报名后可永久观看
Day1 安装python环境
Day2 Python语言入门(一)
Day3 Python语言入门(一)
Day4 OpenCV图像处理(一)
Day5 OpenCV图像处理(二)
Day7 神经网络算法
Day8 猫狗分类演练
Part.3
文中涉及的模型及学习框架
花卉识别模型代码
Part.4
7.6 G不可错过的AI入行秘籍
1. 6G Python入门资料
AI学习的必备帮手
2. 120+篇最新最全的AI报告
遍布政府、证券、咨询、IT等相关行业
3. 6门行业权威亲自授课的在线免费课程
160+篇涉及深度学习、计算机视觉各方向的论文(中英兼备,既泛且精
4. 20+部从小白到高手都能获益的人工智能PDF资料
含人工智能和机器学习领域国际权威学者吴恩达手稿
Part.5
领取方式
扫码加入QQ群
即可领取所有福利
群号:778554527
席位有限,先到先得~
点击【阅读原文】,有惊喜~




