Mercari Price 比赛分享 —— 语言不仅是算法和公式而已

本文首发于知乎专栏「数据科学与脑洞」,AI 研习社获其作者授权转载。
最近半年一直在忙于各种NLP比赛,除夕因为kaggle的price写到凌晨3点,最后靠rp爬回季军,也算圆了一个solo gold的梦想。这应该是我2017下半年玩到的最有意思的一场比赛了,赛内赛外都学到很多。kernel上有很多优秀的解决方案,有同学觉得我注释太少(源码在此https://www.kaggle.com/whitebird/mercari-price-3rd-0-3905-cv-at-pb-in-3300-s ),这里聊一下这个比赛,正好也说说NLP这个领域的二三事。
Price题目非常简单,是一个通过二手商品的名字类型及用户描述来预测一个定价的场景。有趣的地方在于主办方为比赛做了一个很大的限制,让参赛者所有的方案必须在线上的docker(16gb内存+1g硬盘+4 core cpu)中60分钟内完成预处理训练及预测。所以以往疯狂融合模型的套路走不通了,大家在同一起跑线拼的就是对数据和机器学习模型的理解。比赛的ab榜几乎没有shake,可以说是非常良心的比赛。
思路
既然是限时赛,那么我们要做的事情就是通过人的先验知识去为模型铺好道路让它沿着最优的梯度一路滑下去。商品定价回归不同于文本分类,并不是简单的截取单个关键字就可以进行判断,而是由关键词之间会有强烈的互作用力:比如苹果+手机产生的价格远远高于他们各自价格相加,所以奠定了FM会是隐层中一个非常有效的回归工具。而且二手市场大部分都是女性用户,冗长的文本拥有大量信息,那么输入端提取特征时nn的embedding也是一个很好的选择。
预处理部分
预处理占据了代码的70%,但却是最不提分的部分...一个优秀的模型奠定了你的baseline,预处理只能给你锦上添花。如果不是参加比赛的选手其实可以忽略冗长的预处理:基本就是给拼写错误的单词纠正,干掉奇怪的符号,把法语字母翻译成英文字母等。
提一句英文单词有个很有意思的点:词的多态。显然apple和apples、text和txt是相近的意思,但大部分tokenizer都会把它分成两个。这个问题值得细细琢磨,我个人倾向通过词根和词源演化来解决这个问题,所以用了注重子串复现的翻译评价指标bleu去归并了词语,有兴趣可以自行了解下这个原理。
NN系列模型
最早我采用的是一个nn模型,模型结构如下:
la= []
def gauss_init():
return RandomNormal(mean=0.0, stddev=0.005)
def conv1d_maxpool_flatten(filters, kernel_size, pool_size, input):
return Flatten()(MaxPooling1D(pool_size)(Conv1D(filters, kernel_size, activation='sigmoid', padding='same')(input))
input1 = Input(shape=(sub_featlen.shape[1],), dtype='float32')
input2 = Input(shape=(1,), dtype='int32')
input3 = Input(shape=(FEAT_LENGTH-FIX_LEN,), dtype='int32')
input4 = Input(shape=(FEAT_LENGTH2,), dtype='int32')
la.append(Flatten()(Embedding(index3, 30, init=gauss_init(), input_length=1, trainable=True)(input2)))
x31 = Cropping1D(cropping=(0,40))(Embedding(wordnum, 40, init=gauss_init(), trainable=True)(input3))
la.append(conv1d_maxpool_flatten(15, 3, FEAT_LENGTH-FIX_LEN, x31))
la.append(conv1d_maxpool_flatten(50, 2, FEAT_LENGTH-FIX_LEN, x31))
embedding_layer1 = Embedding(wordnum, 160, init=gauss_init(), trainable=True)
la.append(Attention(50)(Cropping1D(cropping=(0,80))(embedding_layer1(input3))))
la.append(Attention(50)(embedding_layer1(input4)))
la.append(conv1d_maxpool_flatten(55, 2, FEAT_LENGTH2,
Cropping1D(cropping=(0,50))(Embedding(wordnum, 50, init=gauss_init(), trainable=True)(input4))))
x1 = BatchNormalization()(merge(la+[input1],mode = 'concat'))
x1 = Dropout(0.02)(merge([Dense(30, activation='sigmoid')(x1),
PReLU()(Dense(470)(x1))], mode='concat'))
x1 = Dropout(0.02)(merge([Dense(256, activation='sigmoid')(x1),
Dense(11, activation='linear')(x1),
PReLU()(Dense(11)(x1))], mode='concat'))
out = merge([Dense(1, activation='linear')(x1),
Dense(1, activation='relu')(x1),
MaxoutDense(1, 30)(x1)], mode='sum')
model = Model(input=[input1,input2,input3,input4], output=out)
四个input分别代表一些普通数值特征、商品分类embedding、商品名称+商标的短文本以及商品详细信息长文本。普通特征用Dense处理、文本使用cnn+attention。
为了保证效率,有几个高光的细节:
1.文本的处理:首先放弃了lstm使用快速的cnn和attention,让模型训练在cpu下也可以非常快的处理embedding。特征方面把商品名字和商品商标放在一起作为一个短文本,我之前有一篇博客(https://zhuanlan.zhihu.com/p/29394867)专门谈过这个加速训练的方案,比赛后我惊讶地发现这个思路很多top选手也用了,殊途同归。
2.模型训练为了极致优化时间,我甚至将每个ep的batchsize和optimizer手动控制,让前期的batchsize小lr大——小步迅速迭代更新,后期batchsize大lr小——finetune。为了让参数最优,几乎所有参数都是靠不断猜想尝试+盯着loss的每一跳感受模型的梯度下降调整的...养成盯进度条的习惯有好处的。
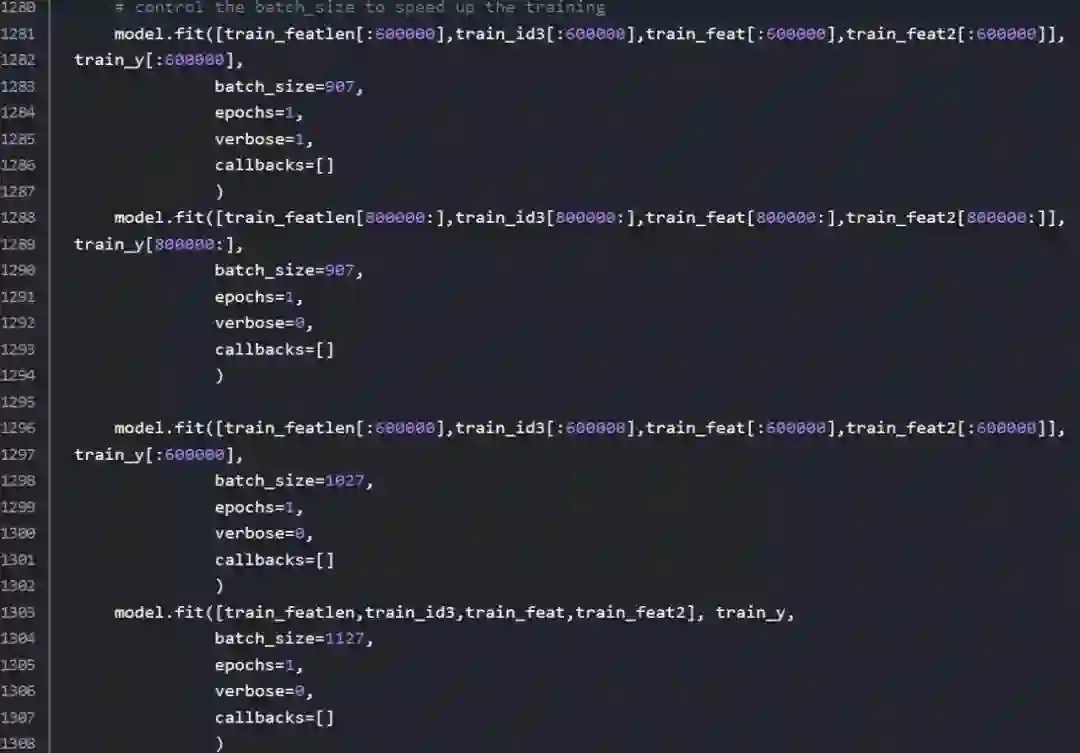
atchsize控制
3.大量运用了concat不同激活函数的方式。本来一个relu的结构,我习惯用一个relu和sigmoid拼接,甚至再加一个linear。我认为每一层的隐层特征里面既有表达是与否的二分类特征也有表达程度的量特征,用任何一个激活函数都是会有信息丢失,最合适的方式是让模型的梯度自行选择合适的激活函数。
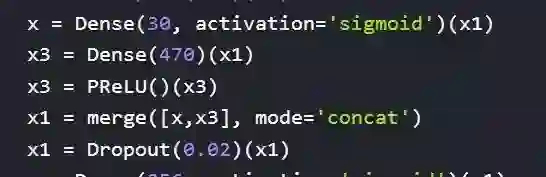
Dense concat操作
另外优秀的NN模型还有第四名的XNN以及第一名的无embedding的文本处理NN。
第四名的XNN结构很复杂这里就不细说,各位可以去阅读他的github(https://github.com/ChenglongChen/tensorflow-XNN ),杂揉了cnn、attention、attend、fm等思路,是一个惊艳的NLP解决方案。
第一名的NN模型完全舍弃了cnn,用ngram先提取了所有关键词然后tfidf直接扔给模型,效果非常惊人,仅仅用半个小时就远高于现在第二名的成绩,只能说state of the art。精致的80行代码,里面满满的都是对于数据的理解。所谓艺术品对于新手来说如果看不到他雕刻成型的过程,那是很难学习到东西的,不建议新手学习。。。
FM系列模型
一个NN对这个比赛来说是不够的,当我把我的NN压在40分钟左右时,我开始做第二个模型。这时刚巧anttip开源了他的wordbatch库(https://github.com/anttttti/Wordbatch ),我把它稍稍做了修改(将部分特征tfidf),作为次模型和NN加权。学会FM的使用是这个比赛给我最大的收获,以前从未想过FM可以在文本处理任务上这么优秀。
不得不说anttip的ftrl-fm写的非常漂亮,建议大家有兴趣的去拜读一下他的cython代码。FM系列算法在文本处理场景的好处是可以处理上百万维的特征,而embedding+cnn最多能提取上千到上万个关键词。相比之下FM更加迅速暴力,但缺点是不像NN一样可以有3-5个隐层处理特征关联,潜力不足。但个人认为在一些简单的工作生产环境,如商品短文本识别推荐等,高效率的ftrl-fm比NN更加适合。
lgb系列模型
这个是我没有尝试的,因为在文本场景lgb表达力操作感上来说远弱于NN,速度上又逊于FM。
--------------分割线---------------
比赛说到这里,最后随便说点算法之外的事吧。2017年对我来说无论是在工作还是比赛上写代码,像极了wow那几年打raid的日子。
最大的感触是:Things change. 工作、比赛与游戏一样充斥着版本的更替。不断有更加优秀的方案和模型涌现,就像一个个小资料片,瞬间就把以前的方案踩在脚下。
版本伊始,早期玩家带着任务装备开荒,战场牌子副本牌子每个cd拼命的刷,种族声望日常任务没有断过。
新版本的一切如公众号上热门的那些技术文:计算机视觉、自然语言、自动驾驶、强化学习;各个平台的比赛:天池的科学家积分、kaggle的master成就。日常论文要读,比赛牌子要刷。
就在休闲玩家刚刚意识到版本的稀缺职业和材料的时候,高玩已经开着g团赚够了g。老板终于砸锅卖铁刷出毕业装的时候,新版本预告片出来了。晚期的紫装贬值,属性还不如下个版本的入门蓝绿。暴雪大手一挥,辛辛苦苦刷了几个月的毕业装和货币化为废土。
人生并没有在你艰辛努力后考上大学、买房、成家、打败lich king的那一刻走到幸福的终点,而是从零开始了另一个篇章。NN神经网络和lgb梯度森林已经快把传统的LR、SVM的价值挤压殆尽了。转瞬即逝的比特币已经成为版本弃儿,而这个版本极度稀有的房产和算法科学,两年后的下个版本会不会烂在拍卖行?

没有什么事物抵挡得住时代变迁,除了人。知识会过时,想象力和好奇心不会;算法会被淘汰,工程和学术能力不会。并没有人告诉我们神经网络或者梯度森林什么时候会过时,但我想如果有心把coding做到极致,不妨在提升这些算法熟练度的同时,多做一些算法之外的东西。从在研究Word2vec的时候想起阅读古老的词源学演化开始,从看到埃舍尔的版画能联想到CNN的kernel之间互相影响开始,从看到壮丽的建筑感受到美妙的结构优化开始。
NLP是个非常有意思的领域,至今为止我常常在阅读或者与人交谈时,思考人为什么如此组织语言,词汇在我脑海中以怎样的方式形成话语。正是因为这种对抽象和感性的迷惑促使了近年来这个领域不断出现新的想法。人类拥有动物的兽性,又在长远的进化路上获得了理智。兽性本是天生,生物学可以解释。现在是时候尝试了解陌生的理智了。
最后祝各位狗年运势昌隆,竞赛有成。

春节 AI 学习狂欢,精品课程 豪华特辑
优惠折上折,福利抢不停!

进入阅读原文获取更多福利
▼▼▼




