从谷歌到阿里,谈谈工业界推荐系统多目标预估的两种范式
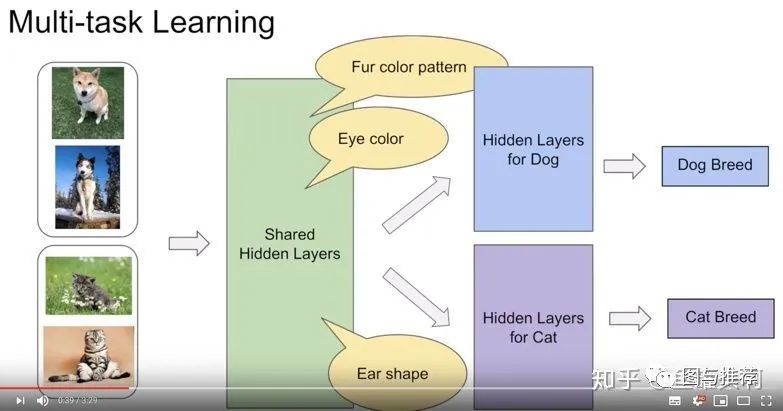
多目标是什么?为什么要多目标?
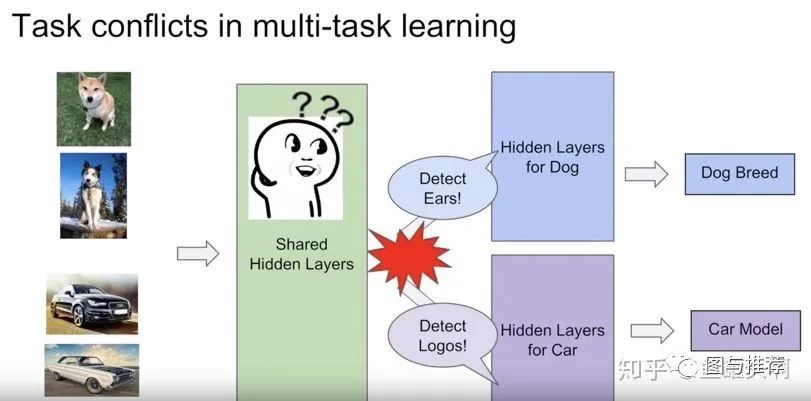
范式一:MMoE替换hard parameter sharing
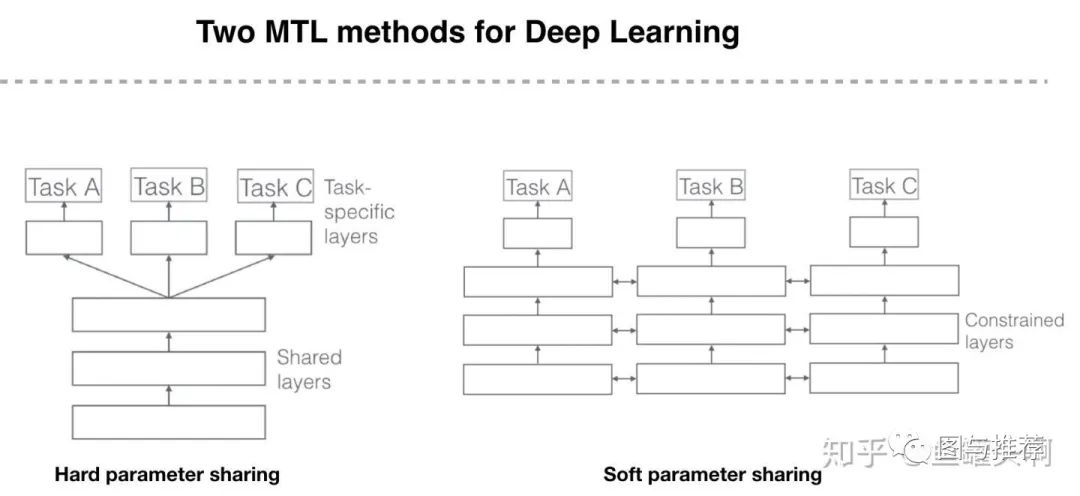
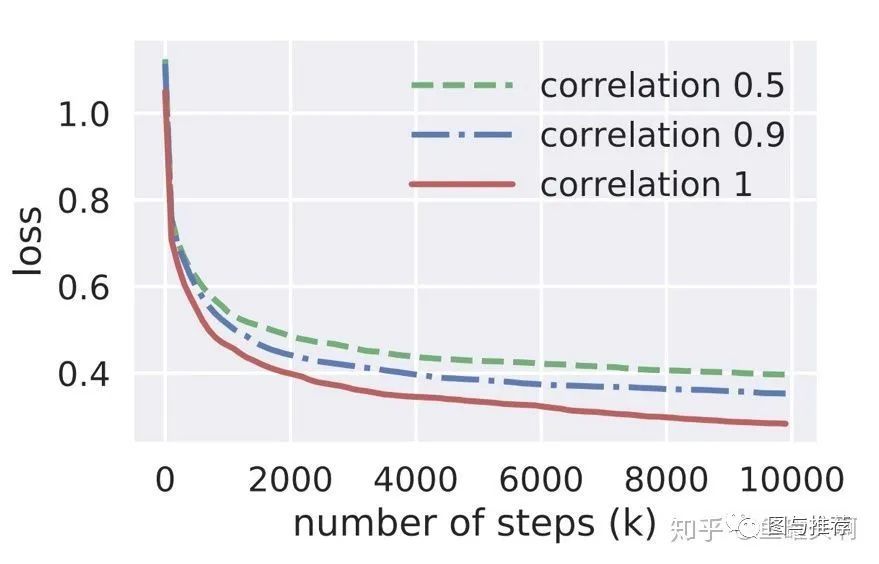
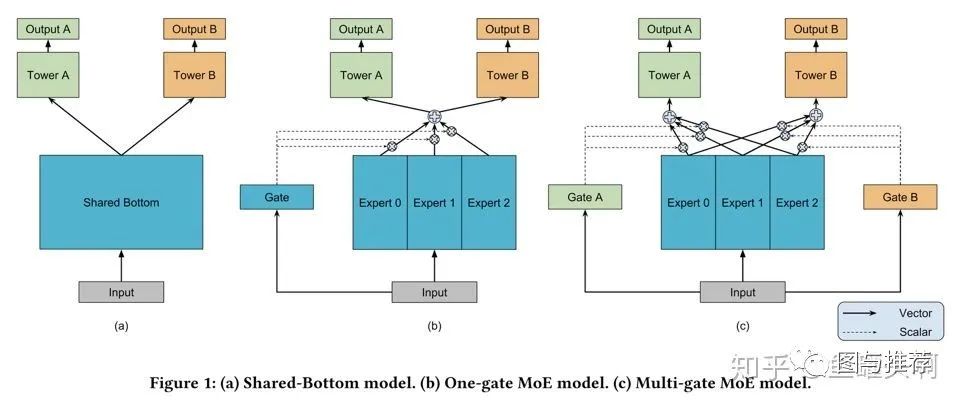
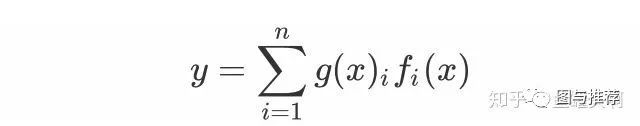
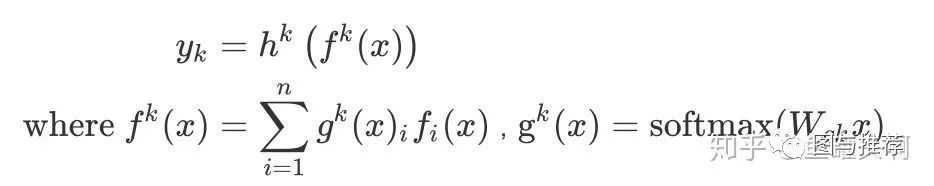

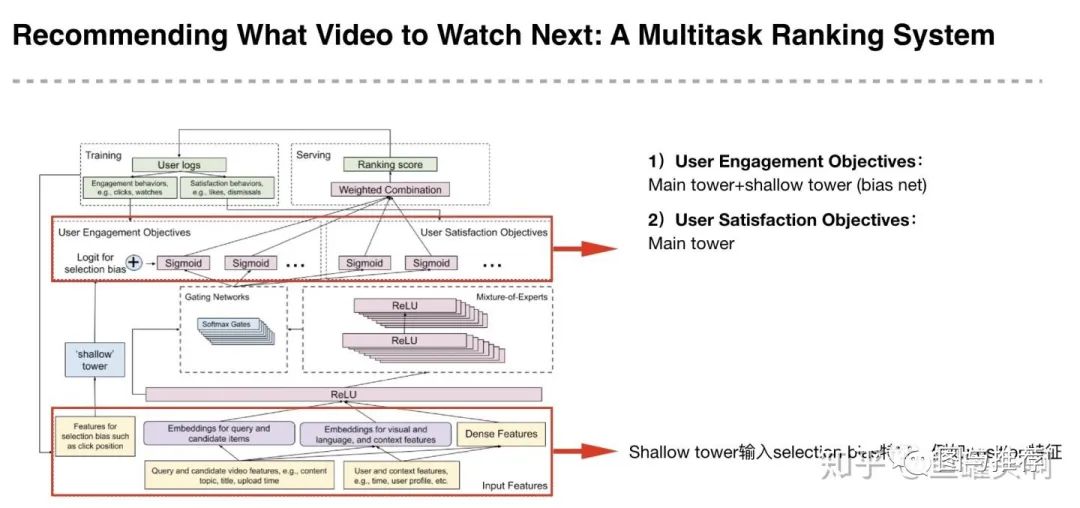
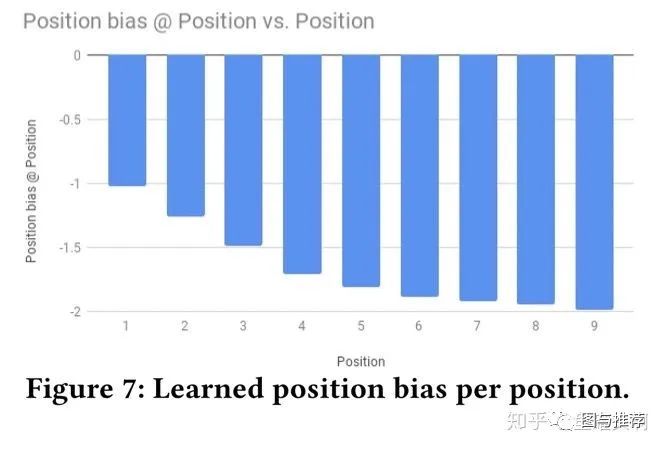
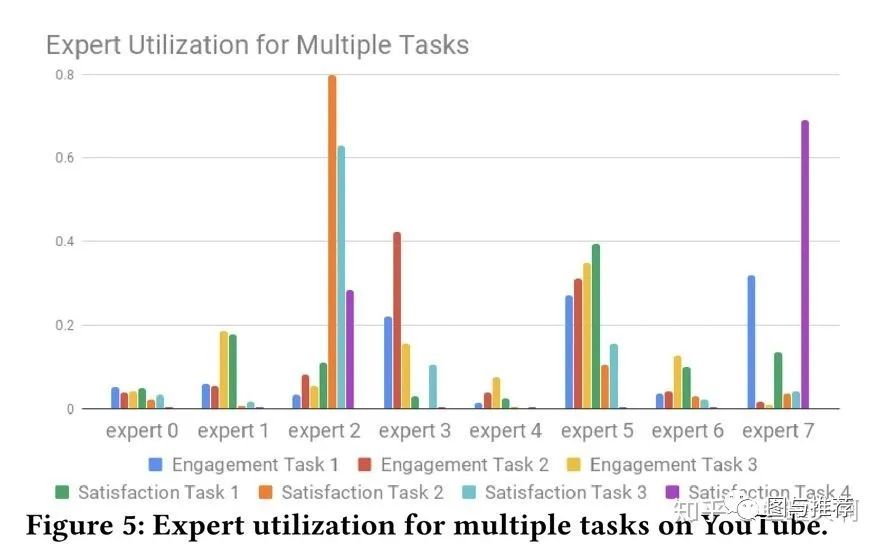
范式二:任务序列依赖关系建模
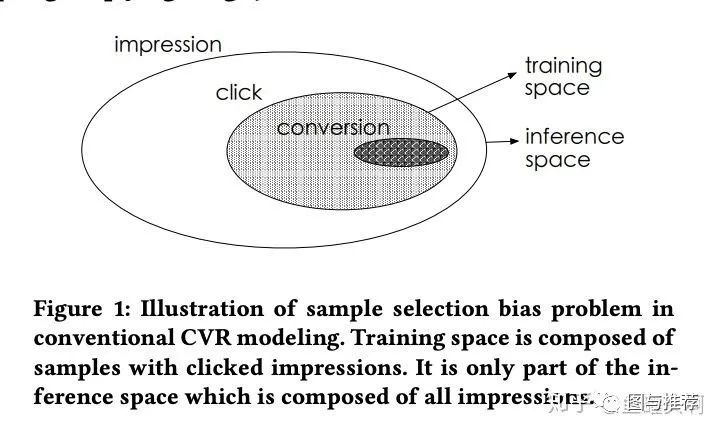

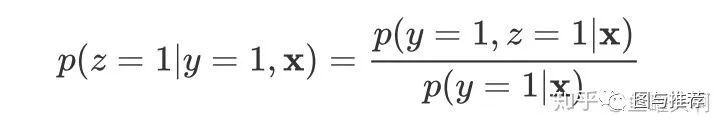
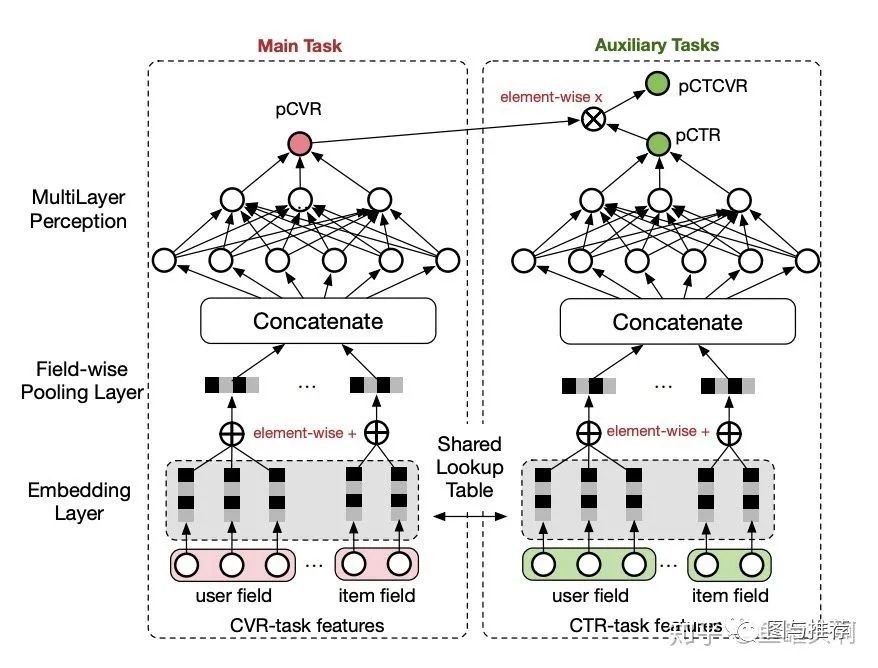
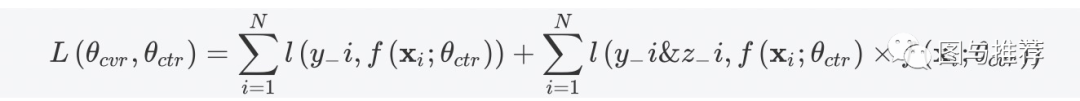
两种范式结合:MMoE+ESSM?
多目标预估中的其他问题


登录查看更多
相关内容

Arxiv
3+阅读 · 2018年9月11日
Arxiv
5+阅读 · 2018年4月5日





相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年9月11日
Arxiv
5+阅读 · 2018年4月5日