TPAMI2022 || 基于图神经网络实现强化的、增量和跨语言社会事件检测
北京航空航天大学、美国伊利诺伊大学芝加哥分校和澳大利亚莫纳什大学联合提出了一个全新的强化、增量且跨语言的社会事件检测体系结构FinEvent在离线、在线和跨语言社会事件检测任务中,FinEvent的模型质量有了显著和持续的提高,分别提高了14%-118%、8%-170%和2%-21%。

作者
Hao Peng, Ruitong Zhang, Shaoning Li
Beihang University, School of Computer Science and Engineering, Beijing,
Yuwei Cao
Computer Science, University of Illinois at Chicago
Shirui Pan
Faculty of Information Technology, Monash University
Philip Yu
Computer Science, UIC, Chicago, Illinois, United States
论文地址:https://ieeexplore.ieee.org/document/9693189/authors#authors
本作品的源代码和数据在 https://github.com/RingBDStack/FinEvent 公开。
摘要:
从社会信息中发现热点社会事件(如政治丑闻、重大会议、自然灾害等)是至关重要的,因为它突出了重大事件,有助于人们理解现实世界。由于社会信息的流特性,随着时间的推移,增量的社会事件检测模型在获取、保存和更新消息方面已经引起了广泛的关注。然而,现有的面向流社会信息的事件检测方法通常面临着事件特征模糊、文本内容分散、语言多,准确率和泛化能力较低。在本文中,我们提出了一种新的增强的(强化的)、增量的和跨语言的社会事件检测体系结构,即来自流媒体社会信息的FinEvent。具体来说,我们首先将社会消息建模为融合丰富元语义和多种元关系的异构图,并将其转换为加权多关系消息图。其次,我们提出了一种新的强化加权多关系图神经网络框 架,通过使用多智能体强化学习算法来选择跨不同关系/边的最优聚合阈值,以学习社会消息嵌入。为了解决社会事件检测中的长尾问题,设计了一种平衡采样策略指导的对比学习机制,用于增量社会消息表示学习。第三,设计了一种新的基于深度强化学习的空间聚类模型,用于在社会事件检测任务中选择形成一个聚类所需的最佳最小样本数和两个聚类之间的最佳最小距离。最后,在图神经网络上实现了基于知识保存的增量社会信息表示学习,实现了跨语言的社会事件传递检测。我们进行了大量的实验来评估推特流上的FinEvent,结果表明,在离线、在线和跨语言社会事件检测任务中,FinEvent的模型质量有了显著和持续的提高,分别提高了14%-118%、8%-170%和2%-21%。
1 引言
社会事件是现实世界中不寻常事件的发生,涉及特定的时间、地点、人物、内容等。[1],同时在社交网络和媒体中被广泛传播和讨论。例如,在2020年1月26日发生的卡拉巴萨斯直升机坠毁事故[1]中,包括退役职业篮球运动员科比·布莱恩特、他13岁的女儿吉安娜、棒球教练约翰·阿尔托贝利和其他5名乘客在内的9人遇难。社交媒体平台(推特、微博、脸书、Tumblr、Telegram等)已经成为官方和个人社交新闻的主要来源。这些平台吸引了大量用户,因为它们为人们提供了方便的方式来实时分享和寻求关于社会事件的观点。从大量社交信息中检测社会事件是有益的。一方面,以事件的形式存储每日新闻和社会消息可以使信息存储更有条理[2] 并丰富信息推荐[3]. 另一方面,社会事件检测可以应用在大量的实际应用中,例如舆情分析[4], 情感分析[5],企业风险管理[6], 政治选举预测[7],等等。从技术上来说,社会事件检测侧重于从大量真实的社会消息中学习高效的事件相关聚类。
然而,社会事件检测任务比传统的文本挖掘或社会网络挖掘更具挑战性,因为一般的社会事件是开放领域中有意义和有影响的社会信息的组合。社会事件往往包含一些与事件相关的异质元素,如地点、人物、组织、关系、日期时间、关键词等。虽然存在基于异质信息网络(HIN)[8]的社会消息模型[4],[9],[10],但如何学习更有区别的社会消息嵌入仍然是一个难以解决的问题。特别是,社会消息的内容总是重叠的、冗余的和离散的,而消息流的噪声特性使得传统的离群点检测技术[11]-[14]不适合语义丰富的事件检测任务。因此,第一个挑战仍然是如何对社会消息建模,并设计一个更具更有区别和解释性的社会信息嵌入框架。除了上述复杂的语义,事件检测任务还具有长尾分布的特点[15]。一般受到社会数据收集和社会事件标注成本的限制。每个事件中包含的消息(样本)数量相对不均衡[9]。长尾问题促成了第二个问题挑战,即检测方法的性能下降和泛化能力差。更多实用的社会事件检测方法通常使用流聚类检测技术,而不是事件分类技术。此外,实用的社会事件检测方法也需要实现对流消息的增量检测[12], [16]甚至跨语言检测[17], [18]。一方面,社交消息和社会事件都具有时间属性,社交消息流中社交事件的数量也会增加。不同于现有的在线社交事件检测方法[1],[13], [14], [19]–[22] 基于确定性模式,如团、密集图、关键词、主题和模板等,一个泛化性能更好的语义增量事件检测框架值得研究。另一方面,跨语言消息会导致隐含词或实体语义嵌入的空间不一致[23], 这也为事件检测模型带来了直接的可用性困难(虽然有第三方翻译工具或翻译对齐模型可以解决这些问题,但这些困难是相对客观的)。因此,第三个挑战是如何实现跨语言的社会事件检测,甚至推广到低资源的语言消息数据。
为了应对上述挑战,我们推出了一种新的强化的、增量的和跨语言的社会事件检测架构,即用于从流社会消息中检测事件FinEvent。该体系结构主要包含预处理、消息嵌入、训练、检测和传输5个模块。首先,我们利用异构信息网络[8] 将各种类型的面向事件的元素和关系组织成一个统一的图形结构。与以往利用元路径实例将异构图转化为同构图的方法([4]、[9]、[10])不同,我们首次提出了一种加权多关系图来建模社会消息之间的关联,并将元路径实例的数量保留为不同的边/关系权重。其次,我们提出了一种新的多智能体强化加权多关系图神经网络框架,即MarGNN,利用强化学包含习(RL)学习社会信息嵌入。具体来说,我们利用GNN学习表示社会信息中包含的语义和结构信息并使用多代理Actor-critic算法(AC)[24] 为每个关系学习最优数量/阈值,以便分别指导关系内和关系间的信息聚合。第三,为了解决社会事件检测中的长尾问题,设计了一种基于平衡采样策略的对比学习机制BasCL来指导框架的训练。然后,我们定期更新消息以保持一个最新的嵌入空间,并基于一种精心设计的基于MarGNN的知识保存技术实现增量式社会事件检测。第四,我们还设计了一种新的深度强化学习(DRL)指导的DB-SCAN模型,即DRL-DBSCAN,基于学习到的社会信息嵌入,自动实现社会事件聚类检测任务。通过DRL-DBSCAN,我们使用双延迟深度确定性策略梯度算法(TD3)[25] 学习最小点的最佳参数—形成聚类所需的最小样本数,以及ϵ—社会流中两个集群之间的最小距离。最后,提出了一种跨语言的社会信息嵌入方法,即Crlme,通过传递MarGNN的参数来提高目标语言(非英语)信息的嵌入性能。在Crlme方法的基础上,我们实现了跨语言社会事件的检测。
我们的初步工作发表在2021年[10]网络大会的会议记录中。本文将原始的保留参数的增量事件检测模型KPGNN扩展到一个强化的、增量的、跨语言的社会事件检测体系结构。这个完整版本涉及到在升级方法和建议架构的框架结构方面的一些改进。在模型升级方面,不同于将HINs转化为同构图,我们首先引入了加权多关系图,以保留图中的异构关系中更丰富的结构和统计特征。其次,我们提出了一种新的MarGNN框架来学习更有区别的社会信息嵌入。具体来说,MarGNN通过RL学习最优保留阈值,合理地保留和整合了每个关系中最有价值的语义和结构信息。第三,我们提出了新的DRL-DBSCAN方法,不同于启发式的K-Means或DBSCAN方法,实现了无需人工参数的社会事件聚类检测任务。第四,我们提出了新的Crlme方法来实现跨语社会事件检测。在实验中,提出并分析了更先进的性能。通过深入的分析,验证了[FinEvent](在https://github.com/RingBDStack/FinEvent 公开本作品的源代码和数据 "源码")的有效性和解释性。
总之,本文的贡献总结如下:
•提出了一种新型的社会事件检测体系结构,并将其命名为FinEvent。FinEvent利用社会消息表示学习框架MarGNN、跨语言社会消息表示学习方法Crlme和社会事件聚类检测模型DRL-DBSCAN,实现离线、在线和跨语言社会事件检
•提出了一种新的多智能体增强加权多关系图神经网络框架MarGNN,以学习更有区别的社会信息嵌入。它从不同关系在社会信息聚合中的重要性的角度提供了一个深刻的解释。
•为了解决社会事件检测中的长尾问题,设计了一种基于平衡抽样的对比学习策略BasCL作为社会信息表征学习的基本目标函数。
•为了实现社会事件的自动聚类检测,提出了一种新的深度强化学习引导的基于密度的空间聚类模型DRL-DBSCAN。不需要离线维护,也不需要人工经验,通过深度强化学习来学习DBSCAN的最优参数。
•为了提高低资源语言信息嵌入的性能,提出了一种新的跨语言社会信息表示学习方法Crlme。它从跨语言社会事件检测的角度提供了一个低成本的迁移学习应用。
•在推特流上实现了大量的实验和分析,证明了FinEvent在有效性和解释方面优于现有的SOTA社会事件检测方法。甚至增量的和跨语言的社会事件检测任务也以知识保存和知识转移的便捷方式被释放。
2问题表述和符号
在本节中,我们总结了表1中的主要符号,并将社会流、社会事件、异构信息网络、加权多关系消息图、社会事件检测、增量社会事件检测和跨语言社会事件检测的定义形式化如下。
表 1:符号表

定义2.1社会流 是一个连续的、时间上的社会信息块序列,其中Mi是一个信息块,包含在时间段[ti, ti+1)内到达的所有信息。我们表示消息块Mi为Mi = {mj|1≤j≤|Mi|},其中|Mi|为Mi中包含的消息总数,mj为一条消息。
定义2.2一个社会事件e = {mi|1≤i≤|e|}是一组相关的社会信息,讨论相同的现实世界发生的事件。请注意,我们假设每个社会消息最多属于一个事件。例如,2019年4月巴黎圣母院发生的灾难性火灾在推特上引发了广泛讨论。这里,巴黎圣母院Cathedralfire[3](https://en.wikipedia.org/wiki/Notre-Dame de Parisfire。 "巴黎圣母院Cathedralfire")可以被定义为一个事件,它包含一系列相关tweet(类似于原始消息m1, m2, m3在图2),除了热点事件,我们的工作也关注影响力较小的社会事件,比如西班牙番茄战[4](https://en.wikipedia.org/wiki/La Tomatina。"西班牙番茄战")阿伯丁郡金鹰中毒事件[5](https://www.bbc.co.uk/news/uk-scotland-north-east-orkney- shetland-57000780"丁郡金鹰中毒事件")等等。
定义2.3异构信息网络HIN是一个图G = (V, E),其中V表示社会事件中具有各类事件相关元素的节点集合,E表示消息与相应面向事件的元素之间的边的集合。
定义2.4我们定义一个加权的多关系消息图,其中M是一个节点集合 ,n为节点个数。每个节点表示一个消息 ,并具有一个d维特征向量,表示为 是所有节点特性的集合。 是消息mi和mj之间的边/连接,关系r∈{1,…, R},给定边权值 。注意,一条边可以与多个关系相关联,有R种不同类型的关系。
定义2.5给定消息块 ,社会事件检测算法学习模型 , 使 为 中包含的事件集合,其中θ为f的参数。
定义2.6给定一个社会流S,增量社会事件检测算法学习一系列事件检测模型 ,使得对于 中的所有信息块 。其中, 为消息块 中包含的一组事件,w为更新模型的窗口大小, 和 分别为 和 的参数。请注意, 通过依赖 扩展了其前身 的知识。特别地,我们调用 ,它没有扩展以前的模型作为初始模型。
定义2.7给定英语社会流中社会事件检测算法 ,跨语社会事件检测算法学习一个升级模型 ,其中 也是非英语消息块 中包含的事件集合。其中, 表示由 改进后的模型fNOE的参数。
3FINEVENT架构
FinEvent以增量生命周期机制执行社会事件检测。FinEvent体系结构的设计目标是在事件检测中与社会消息的流特性和真实情况保持一致。具体地说,我们需要灵活的架构来:
1).以在线方式处理社会信息的流式传输特性;
2).不断获取、保存和扩展信息语义;
3).处理实际问题,特别是跨语言事件检测任务。
此外,FinEvent还能够实现跨语言迁移。本节包含FinEvent生命周期中的不同阶段,并介绍FinEvent如何操作跨语言传输检测。
3.1生命周期机制
为了应对流消息的挑战,FinEvent采用了生命周期机制(如图1所示),该机制包括四个阶段,即预训练阶段、单语言检测阶段、跨语言检测阶段和维护阶段,分别如图1所示为阶段I、阶段II、阶段III和阶段IV。在预训练阶段,我们预先存储一小部分社会信息,在此基础上构建初始加权多关系信息图。然后,我们利用处理过的图来训练初始模型。在检测阶段,通过插入新的消息节点、其与现有消息节点的链接以及其内部的链接来更新消息块的加权多关系消息图,并重构加权关系。同时,在更新过程完成后,无需进行新一轮的训练,就可直接利用预训练模型从未见过的信息中检测社会事件。在维护阶段,我们在消息图中删除过时的社会消息,并使用更新后的消息图继续训练来维护模型。在此生命周期中维护的模型可以用于下一个生命周期的检测阶段。通过这样设计的生命周期机制,FinEvent能够很好地适应社会消息的流特性,实现在线方式的事件检测。
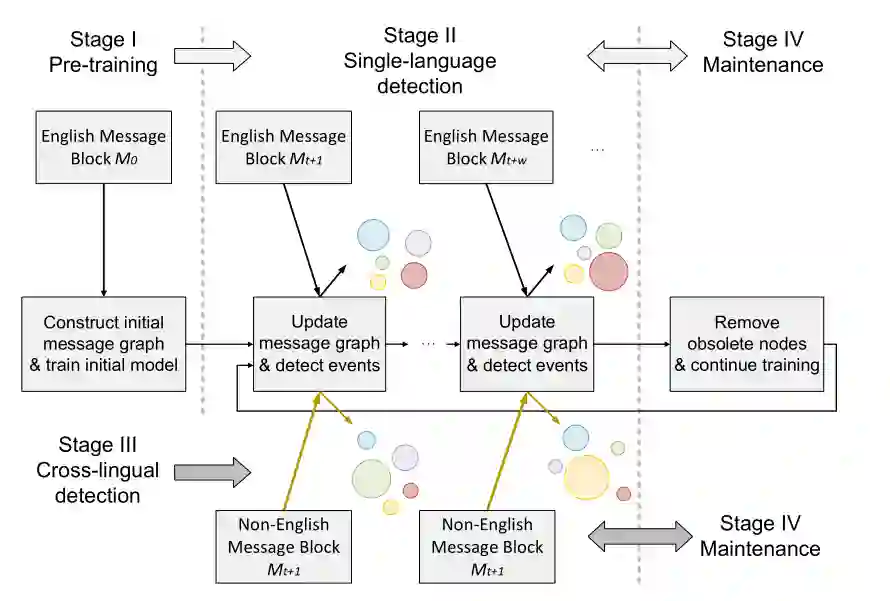
3.2增量学习框架
针对增量社会事件检测中的泛化挑战,我们采用增量学习结合上述生命周期机制,帮助FinEvent不断获取、保存和扩展语义空间,并利用其优势处理实际问题。首先,我们要求我们的体系结构能够有效地组织和处理社会流中的各种元素,以充分利用这些元素,并有效地解释这些元素,从而发现有助于事件检测的底层知识。为了获得消息嵌入,我们首先利用HIN对面向事件的流媒体社会消息进行建模。然后在构造的异构图中提取不同的关系,并根据其元路径实例将其转换为一系列加权的多关系同构图。其次,FinEvent需要在新消息到达时有效地更新其嵌入空间。基于所获得的多关系图,我们在FinEvent中设计了一个增强的图神经网络框架MarGNN,该框架利用了GNN的强大功能来优化社会事件检测的参数,并保留了有关社会数据的有用知识。结合生命周期机制,我们的FinEvent可以实现增量学习模式下的持续训练,而不是从零开始。
3.3跨语言迁移机制
受FinEvent保存和扩展特性的启发,我们采用强大的归纳学习能力来解决跨语言问题,FinEve-nt在检测阶段利用MarGNN中保存的参数来推断事件,在维护阶段利用传入的数据恢复训练过程来扩展MarGNN。如图1中所示在跨语言检测阶段,如果MarGNN用英语信息训练,传入的消息都是用法语或阿拉伯语, 由于MarGNN中保存了参数,我们仍然可以实现检测,并继续扩展到下一个生命周期。因此,我们获得了动态FinEvent体系结构,并在实际应用中对其进行了探索。
4 增强的多关系图神经网络框架
图2显示了提出的框架FinEvent,其中包含五个重要模块。对于原始的社会消息,我们首先将它们转换成一个加权的多关系图(第4.1节)。然后我们使用多智能体强化学习对不同关系选择邻居,通过加权多关系图神经网络得到所有消息的聚合(第4.2节)。为了平衡采样和处理增量检测场景,我们使用基于策略的对比学习机制来训练GNN(第4.3节)。最后,我们使用深度强化学习引导的DBSCAN模型进行事件聚类参数调试(第4.4节)。此外,我们还在第4.5节中给出了跨语言检测的总体算法过程,并在本节的最后给出了算法1。

图2提出的 FinEvent 的架构
算法1FinEvent:强化的、增量和跨语言社会事件检测

4.1加权多关系社会消息图
图2中的异质社会图是从社会流中面向消息和面向事件的元素中提取出来的异质信息网络(heterogeneous information network, HIN)。为了防止不同类型事件元素之间异构信息的丢失,FinEvent将HIN映射到消息节点的加权多关系图 ,从而保存了更丰富的连接信息。我们将多关系图中的节点定义为具有d维特征X的一系列消息集合M(包含所有单词[26]和时间戳编码的预训练单词嵌入的平均值)。当消息共享不同类型的事件元素时,将分别建立属于不同关系的边。多关系图中关系r下消息节点Mi和Mj}的边 如下:(1)
这里, Amr是HIN异构图的邻接矩阵的子矩阵,行代表所有信息节点,和列代表属于关系r的所有事件元素节点。T矩阵的转置, min取两个元素中较小的一个。另外,为了处理在相同关系下具有多个公共元素的两个消息节点之间的信息丢失问题,FinEvent在不同关系的构建过程中引入了边缘权值。我们定义图G中关系r下消息节点mi,和mj的加权边为 ,其中边权 是 。
4.2多关联图神经网络框架下的多智能体强化聚合(MarGNN)
4.2.1强化邻居选择
考虑到社会信息之间存在一些影响消息表示的无意义链接,在聚合之前,我们首先对每个关系进行采样,以保留较高的语义和结构连接邻居。由于多关系图中不同关系存在不同程度的杂质,共同影响嵌入结果,因此需要通过协作学习方法在不同关系之间找到平衡。以往的工作使用伯努利多臂老虎机过程[27]或注意机制[28]来选择邻居,但在增加检测时已不再适用。为此,我们在框架MarGNN中引入多智能体强化学习,引导每个关系在聚合前进行Top-p邻居抽样(图2中的节点选择部分)。具体来说,我们首先对每个关系r下的邻居按照欧氏距离升序排序,然后为每个关系建立一个智能体,作为保留阈值pr∈[0,1]的选择器。当pr = 1时,保留所有邻居;当pr = 0时,丢弃所有邻居。
具体来说,每个关系的智能体将在游戏中学习如何在流社会检测的任务中找到关系之间的平衡。该过程是R型智能体的马尔可夫博弈,由四个元素(Nagg、Aagg、Sagg、Ragg)组成,其中Nagg为智能体的数量,Aagg为智能体的行动空间,Sagg为智能体的状态空间,Ragg为智能体的奖励函数。整个过程的具体细节如下:
-
状态:
鉴于不同关系的保持阈值共同影响最终的聚合效果,我们利用所有关系的保持阈值聚合的邻居节点表示 来计算一个关系下的平均加权距离,这样每个代理人都可以考虑到其他关系的影响。在第k时刻,一个智能体在关系r下所观察到的状态 定义为:
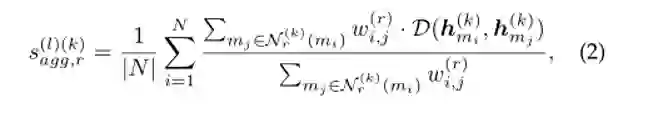
其中 是中心节点 在第k历元关系r下所有保留的邻居节点mj的集合。 为节点 和节点 在关系r下的边权值。
-
动作:
行动 是代理的保留阈值 ,在时代k下的关系r。由于 , r∈[0,1]精度最高,我们使用离散动作加速学习过程。
-
奖励:
由于增强聚合的目标是寻找最佳的聚合方案,以获得消息的最佳聚类性能,因此我们使用归一化互信息(NMI)作为奖励函数,客观地衡量聚类效果。并定义纪元k中关系r下的奖励 ,定义为:
此处 为NMI分数,该分数使用实际的消息类别数量|E_{true}|对消息的表示进行聚类。消息的表示是基于动作 进行聚合的,我们将在第4.2.2节详细展开这个过程。需要注意的是,为了防止DRL-DBSCAN训练过程造成的干扰,我们使用K-Means作为聚类方法。
优化。基于上述定义,每个智能体使用actor -critic算法[24]通过actor网络根据状态选择动作,最终获得相同的奖励来更新损失函数。在这个过程中,每个智能体都力求获得最大的整体利益,多智能体属于一个合作关系。关系r下行动者的损失函数定义为:
(4)
其中Q(,)为动作值函数,π(|)为策略。
4.2.2感知关系的加权邻居聚合
为了更好地指导加权多关系图神经网络学习消息嵌入,我们提出了一种加权关系感知的邻居聚合。如图2中的消息嵌入部分所示,整个MarGNN的聚合过程分为两个部分:关系内聚合和关系内聚合。
对于关系内聚合,参与的邻居消息受保留阈值控制。该过程的形式表示为第l层关系r的消息 的聚合过程:
其中 表示消息mi的邻居消息mj在关系r下嵌入到第L−1层。 表示消息mi的一系列邻居经过邻居选择过程后,保持阈值 的集合。每个消息的嵌入 为输入特征。在考虑消息流不断增加的情况下,引入了图注意网络[29]中邻居聚合器 在关系r内的多头注意机制。Heads 表示head-wise拼接[30],我们在中间层拼接多个Heads的输出,并在最后一层平均它们。⊕表示求和聚合算子。
然后在相互关系聚合中,使用关系的保持阈值作为相互关系聚合中关系嵌入的权重(在第6.3.1节中,我们将比较其他聚合进行验证)。我们将第l层消息 的相互关系聚合定义为:
其中 表示 的聚合间嵌入属于关系r。我们提出了一种基于保留阈值的关联聚合器 ,其中⊗为拼接聚合算子,如串联、求和或多层感知器MLP (multilayer Perceptron)。将关联聚合器的结果和上层消息mi的嵌入结果拼接,作为 在第l层的最终表示。将聚合间嵌入 视为 的最终嵌入 。
4.3基于均衡抽样策略的对比学习机制(BasCL)
增量式事件检测任务中事件类的数量不断变化,使得广泛应用于gnn中的交叉熵损失函数不再适用。对比学习[31]不局限于固定数量的类,因为它侧重于学习相似实例之间的共同特征,以及区分不同实例之间的差异。特别是,对比学习可以解决现实世界[15]中社会事件的长尾问题,其中一些事件是稀疏和小范围的,使得模型难以检测。另外,基于对比学习的表示包含更多类簇结构信息,有利于下游事件聚类任务[32]。受[33],[34]和[35],[36]的启发,我们在BasCL中引入了三重损失,以平衡其他事件类的大量负样本和同一事件类的少量正样本,并在此基础上增加全局-局部对损耗,以保持增量检测长尾事件过程中的图结构信息。
对于每个消息m_i,我们首先采样一个正样本m_{i_+}和一个负样本m_{i_−},以构造三重损失,并更新消息在正样本方向的嵌入。这个过程被形式化为:
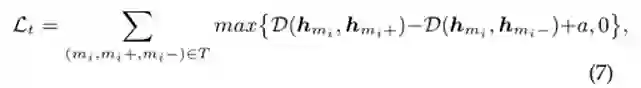
其中(mi, mi+, mi−)是一个三元组,T是一系列以[34]在线采样的三元组。D(,)计算两个消息之间的欧氏距离。max{.}用于获取两个元素中较大的一个。A是一个超参数,它决定了与正样本相比,消息离负样本有多远。
我们还构造了全局-局部对损耗,通过最小化全局摘要和局部消息表示的交叉熵,更好地利用相似结构信息的影响:
全局摘要s是所有消息表示的平均值,而s(,)是一个双线性评分函数,用于获得两个操作数来自联合分布的概率。我们使用噪声对比方法[37]构造 ,通过X的行向shuffle来获得消息表示hmi的损坏表示 。
优化。 我们平衡考虑正-负样本比较和全局-局部比较,定义BasCL的总体损失函数为:
4.4深度强化学习引导的DBSCAN模型(DRL-DBSCAN)
在事件检测阶段,我们根据学习到的消息表示对消息进行聚类(这个过程遵循Def. 2.6)。常用的基于距离的聚类算法K-Means容易用于聚类表示,但由于需要指定类别的数量,在增量检测任务中存在局限性。基于密度的聚类算法DBSCAN[38]自动调整类的数量,但它仍然有两个参数(距离参数Ɛ和最小样本数参数minPts),需要手工调整,不能适应在不断变化的消息输入中匹配不同数据分布的消息块。为此,我们首先在模型DRL-DBSCAN中提出了一种新的强化学习方法,探讨如何在与DBSCAN的多轮参数交互中获得稳定的社会事件聚类效应。据我们所知,我们是第一个将DBSCAN和RL方法结合起来的。DRL-DBSCAN以参数调整系统为智能体,增量社会数据为环境,将过程形式表达为马尔可夫决策过程MDP (Sclu, Aclu, Rclu),其中Sclu为状态空间,Aclu为行动空间,Rclu为奖励函数。具体来说,我们定义了以下三个元素:
-
状态:
状态是智能体在每次参数调整后观察到的消息块事件的聚类情况,即对聚类结果的描述。考虑到在观察状态时不能使用事件的簇标,将情景τ内的状态s(τ) clu定义为四元集:
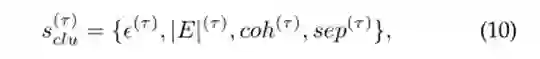
由当前最小邻居距离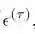
-
行动: 为了防止维数诅咒,提高DBSCAN处理速度,我们使用分布式随机邻居嵌入[40]将消息表示的维数降为2维。因此,根据DBSCAN算法作者对最小样本数参数的建议,将minP ts固定为2。然后,我们定义在τ时刻的作用a(τ)是当前状态s(τ) cluu应选择的参数值。此外,动作空间是具有上下界的连续数据 -
奖励: 对于奖励函数,我们引入外部评价指标Calinski-Harabasz[41] (也称为方差比准则)来刺激智能体。这种奖励的设置不需要依赖样本的真实标签和事件类的数量,在检测过程中可以比其他外部评价指标更快地找到聚类组合。奖励函数定义为:
其中,SS(τ) W为τ情景中的总体簇内方差,SS(τ) Bis为总体簇间方差。N为消息总数。CH的事实可能的失败在极端情况下(例如,集群的CH指数2是异常高的数量),我们一些定义可接受的数量的集群中,给一个奖励值为0的情况下超过范围。
优化。在参数调整过程中,相邻集的状态之间存在很强的相关性。为了避免神经网络学习的片面问题,我们选择双延迟深度确定性策略梯度算法[25]对一个策略网络和两个值网络进行优化。其中,价值网络的损失函数表示为:
其中,E表示从经历重放记忆中随机抽取过渡元组()并计算期望的过程。Q是当前值网络中的动作值函数。 表示选择两个值网络中动作值最小的,是为了抑制过高估计。
4.5跨语言消息嵌入方法(Crlme)
在更广泛的社会事件检测场景中,除了英语等资源丰富的语言外,还存在一些原始信息不足的非英语语言,无法重用英语模型的训练过程。为了实现更低资源的社会事件检测和降低训练成本,在检测非英语事件时,我们直接继承英语模型fE中保留的参数θ作为非英语模型fNoE的参数θ。我们将这个方法命名为Crlme,并在Def 2.7中形式化了这个过程。其中,参数θ包括通过对比学习保留的信息语义和结构的认知,通过多智能体强化学习发现的多关系平衡方法,以及通过深度强化学习获得的DBSCAN聚类参数调整能力。此外,我们利用LNMAP模型[42]将非英语信息m映射到英语语义空间,以增强英语参数的适应性。
4.6维护策略
1)所有信息策略,保留所有信息。在检测阶段,我们只需将新到达的消息块插入到g中。在维护阶段,我们使用图中的所有消息继续训练过程。换句话说,我们让FinEvent记住它曾经收到的所有消息。这种策略是不切实际的(在G中积累的消息会逐渐降低模型的速度,最终会超过消息编码器E的嵌入空间容量),我们实现它只是为了进行比较。
2)相关消息策略,保留与新到达的消息相关的消息。在检测阶段,我们新来的消息块插入图在维护阶段,wefirst删除消息没有连接到任何消息到在过去的时间窗口,然后继续训练中使用的所有消息图 .换句话说,我们让FinEvent忘记老的消息(例如,到达窗口之外),与(到达窗口内的新消息)无关。请注意,从这些消息中获得的知识以模型参数的形式保存。
3)最新消息策略,保持最新消息块。在检测阶段,我们只使用新到达的消息块来重构图G。在维护阶段,我们继续训练图G中的所有消息,它只涉及最新的消息块。换句话说,我们让FinEvent忘记除了最新消息块中的消息之外的所有消息。从被删除的消息中学习到的知识以模型参数的形式记忆。
4.7提出FinEvent
算法1显示了我们提出的FinEvent的生命周期。在生命周期中,加权多关系图是不断变化的。具体来说,我们初始化一个加权多关系图G在训练前阶段(3算法1行)。新消息到达时,也就是说,单一语种的检测或跨语言检测阶段,我们通过插入新的消息更新图G节点和建立连接算法1(第5行)。此外,在维护阶段,我们定期删除过期的节点和边缘,详细的维护策略见章节4.6。在训练前阶段对MarGNN的邻居选择器进行初始化和训练,在维护阶段继续进行定期训练,以便在新消息到达时对邻居选择器进行优化(算法2第15行)。在进行模型单语言检测或跨语言检测时,选择不更新,直接观察到新来的相似性让邻居(1 - 3算法3行)。值得注意的是,聚合模块将参与整个生命周期,无论是pretraining或维护和检测阶段(第4 - 9线在算法2,5 - 12线算法3)。MarGNN之后,BasCL只出现在训练和维护阶段(算法2第13行)。此外,DRL-DBSCAN部分只会参与生命周期的检测阶段,并在每个block中重新开始游戏进行优化。在游戏中,DRL-DBSCAN会进行一系列的动作改变,直到获得一个稳定的事件集群(算法3中10-15行)。


5实验设置
5.1数据集
我们主要在大规模、公开可用的数据集上进行实验,即 Twitter API 收集的 Twitter 数据集,以评估流媒体社会事件检测的有效性,因为它由多个具有连续时间戳的消息块组成。在过滤掉重复和不可恢复的推文后,Twitter 数据集完全包含 68841 条手动标记的推文,分别与 503 个事件类别相关,分布在大约 4 周(29 天)内。为了进行跨语言实验,我们另外收集了法语 Twitter 数据集,其中包含与 257 个事件类别相关的 64516 条带标签的推文,分布在大约 3 周(为期 23 天)内。此外,我们设置了三个关系,包括 M-U-M(消息-用户-消息)、M-L-M(消息-位置-消息)和 M-E-M(消息-实体消息),作为加权多关系图的元路径模式。对于增量检测,我们按日期拆分 Twitter 数据集以构建社会流。具体来说,我们使用第一周的消息形成初始消息块 M0,其余天的消息形成以下消息块 M1,M2,...,M21。附录 C 显示了产生的社会流的统计信息,包含每个区块的消息总数和事件类别。图 3 可视化了两个数据集的事件分布,它们遵循长尾趋势,并且属于每个事件的消息计数非常不平衡。少数事件与大量消息相关联,而大部分事件与少量消息相关联。可能的原因是社会网络中的优先依恋。在这种情况下,由于训练实例不足导致泛化性差,特别是在社会流中,学习小样本的事件检测器要困难得多。

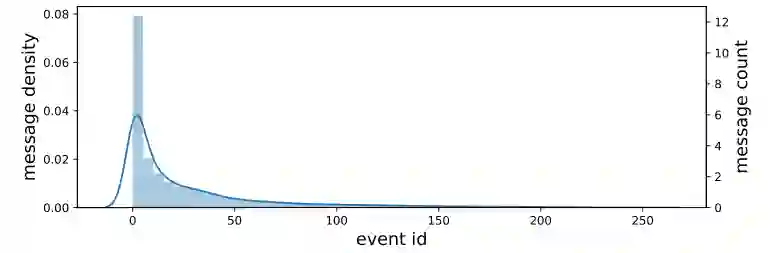
图3社会流中的长尾分布和数据不平衡挑战。曲线和条形分别表示一个事件中消息的密度和计数。消息计数的数量级为
5.2 基线
我们将 FinEvent 与一般消息表示学习和相似性测量方法、离线社会事件方法、增量方法和原始 KPGNN 进行比较。基线是:Word2vec [43],它使用消息中所有单词的预训练 Word2vec 嵌入的平均值作为其表示;LDA [44],一种生成统计模型,通过对底层主题和单词分布进行建模来学习消息表示;WMD [45],它通过计算一个词嵌入到另一个消息中需要经过的最小距离来测量两条消息之间的差异;BERT [46],它使用消息中所有单词的 BERT 嵌入的平均值作为其表示;BiLSTM [47],它学习消息中单词之间的双向长期依赖关系;PP-GCN [9],一种基于 GCN [48] 的离线细粒度社会事件检测方法;EventX [14],一种基于社区检测的细粒度事件检测方法,适用于在线场景。KPGNN,一种用于流式社会事件检测的知识保存增量异构图神经网络模型;KPGNNt,其中全局-局部对损失项 Lp 从损失函数中移除,仅使用三元组损失项 Lt。FinEventk,仅实现 K-Means 来对最终嵌入进行聚类。
5.3实验设置
对于提议的 FinEvent,我们将 MarGNN 中的内部关系聚合的注意力头数设置为 4,嵌入维度设置为 64,总层数设置为 2,学习率设置为 0.001,优化器设置为 Adam,训练epochs 到 100,设置提前停止的patient为5,并选择最佳模型进行推理。BiLSTM 和其他基于 GNN 的基线使用与上述基本相同的配置,只是将维度设置为 32。此外,我们将 LDA 的topics总数设置为 50,并且对于 EventX采用原始论文 [14] 中建议的超参数。对于维护策略和BasCL,我们将三元边距a设置为3,使用大小为2000的小批量采样来提高训练效率,采用最新的消息策略和维护窗口大小为3(KPGNN和KPGNNt也使用这些)。对于MarGNN的多智能体强化学习算法Actor-critic,我们使用步长为 0.01 的离散动作空间在 [0, 1] 到每个保留阈值的范围内,并将每个关系的最佳阈值初始化为 1.0。对于 DRL-DBSCAN 的深度强化学习算法 TD3,我们设置范围为 [−5, 5] 的连续动作空间,Eps 的取值范围为 (0, 10],聚类边界为 [15, 100], batch size 为 32,降维的 perplexity 为 40。其中,初始参数是动作空间的中点。我们将所有实验重复 5 次,并报告结果的均值和标准方差。注意 KPGNN 和 FinEvent不需要预先定义事件类的总数,但是一些基线(Word2vec、LDA、WMD、BERT 和 BiLSTM)需要。为了公平比较,在从 WMD 获得消息相似度矩阵和从除了 EventX 之外的其他模型(EventX 没有预先定义其检测到的类的总数),我们分别利用 Spectral 和 K-Means 聚类,并将类的总数设置为 grounded-truth 类的数量。否则, 在增量检测的情况下,FinEvent 是为以前未知数量的类设计的。因此,我们还详细分析了自适应 DRL-DBSCAN 聚类模块,以展示我们的优势。实验中的完整架构被命名为 FinEventd 以便于区分。
5.4 实施
对于 Word2vec,我们使用预训练的 300-d GloVe [49] 向量。对于 LDA、WMD、BERT、PP-GCN 和 KPGNN (KPGNNt),我们使用开源实现6[2]7[3]8[4]。我们使用 Python 3.7.3 实现 EventX,使用 Pytorch 1.8.1 实现 BiLSTM 和 FinEvent。所有实验均在具有 512GB RAM 和 1×NVIDIA Tesla P100-PICE GPU 的 64 核 Intel Xeon CPU E5-2680 v4@2.40GHz 上进行。
5.5 评价指标
为了评估所有模型的性能,我们测量了它们检测到的消息集群和真实集群之间的相似性。我们利用归一化互信息 (NMI) [50]、调整互信息 (AMI) [51] 和调整兰特指数 (ARI) [51]。NMI 测量人们可以从关于groundtruth 标签分布的预测分布中提取的信息量,并广泛用于社会事件检测方法评估[9]、[14]。AMI 与 NMI 类似,也测量两个集群之间的互信息,但会根据机会进行调整 [51]。ARI 考虑所有预测标签对并计算分配在相同或不同集群中的对,并且 ARI 还考虑了机会 [51]。
6 评估
在本节中,我们首先将 FinEvent 与不同的基线进行比较,包括离线以及增量社会事件检测模型。我们进一步研究了强化学习引导的多关系 GNN 的效果和稳定性。然后,我们给出了跨语言迁移评估。最后,我们提供了 FinEvent 的时间复杂度分析。
6.1 线下评估
在本节中,我们将初步模型 KPGNN 和改进版 FinEvent 与离线场景中的基线进行比较。对于这两个数据集,我们随机抽取 70%、20% 和 10% 用于训练、测试和验证,因为这些分区通常被 GNN 研究采用 [9]。为了确保一致性,我们将 FinEventk 与其他实现 K-Means 聚类的基线进行比较。表2 总结了离线评估结果。FinEventk 在所有指标上都大大优于一般消息嵌入方法(Word2vec、LDA、BERT 和 BiLSTM),相似度测量方法(WMD)( Twitter 数据集上的 NMI、AMI 和 ARI 为 8%-172%、24%-1、450% 和 20%-2300%)。原因是这些方法要么依赖于测量消息元素 (LDA) 的分布,要么依赖于消息嵌入(Word2vec、WMD、BERT 和 BiLSTM),它们都忽略了底层的社会图结构。请注意,尽管 PP-GCN 表现出强大的性能,但它假定了一个固定的图结构,无法适应动态的社会流。相反,FinEventk 能够不断地适应和扩展传入消息的知识(在第 6.2 节中进行了经验验证)。KPGNN 的性能也优于 PP-GCN 和 KPGNNt,这意味着 Lp 的优势。EventX 在其他基线中显示了 NMI 的最高度量分数,但与 KPGNN 和 FinEventk 相比要低得多。这表明 EventX 倾向于生成更多的集群,无论是否实际捕获了更多信息,而 FinEventk 总体上更强大。FinEventk 的性能优于其原始版本 KPGNN。这种改进归功于多关系 GNN 中的多智能体引导聚合。它能够自适应地过滤噪声(即不相关的消息,但由于提到相同的位置而意外链接)并捕获贡献的邻居。最后,FinEventd 在 NMI 中的表现比 FinEventk 高 10%,在 AMI 中高出 11%,在 ARI 中高出 100%。它展示了 DRL-DBSCAN 在离线检测任务中的强大功能。总而言之,FinEvent 在 NMI 中显著优于其他基线 11%,在 AMI 中高出 38%,在 ARI 中高出 140%。

6.2 增量评估
本小节在增量检测场景中评估 FinEvent。表 3、4 和 5分别总结了 NMI、AMI 和 ARI 中的增量社交事件检测结果。请注意,作为离线基线的 PP-GCN 不能直接应用于动态社交流,我们通过为每个消息块从头开始重新训练新的 PP-GCN 模型来缓解这种情况(即,使用之前的块作为训练集和预测当前块)。对于 FinEvent,保留阈值将在维护阶段的每个开始时初始化。为了确保一致性,我们将 FinEventk 与其他实现 K-Means 聚类的基线进行比较。
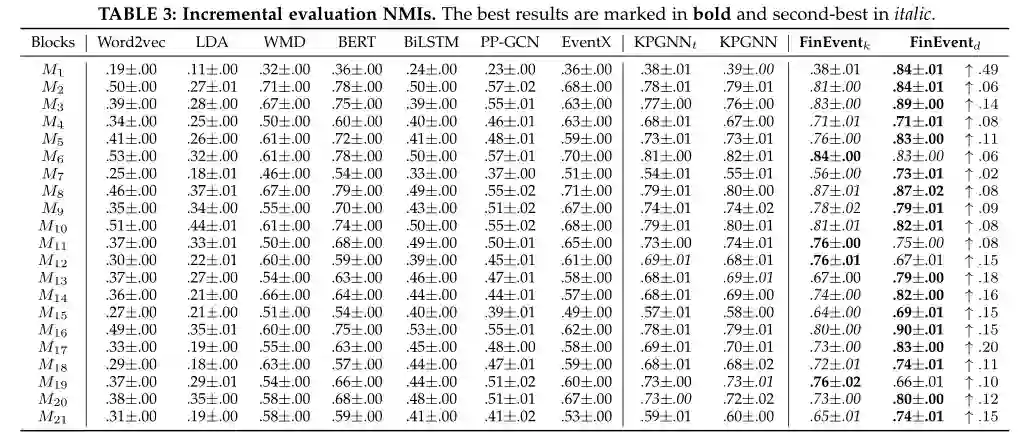
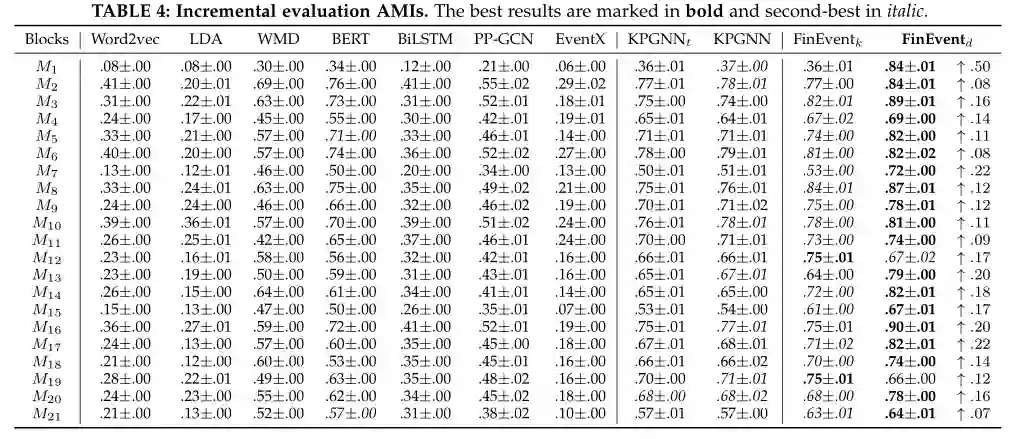
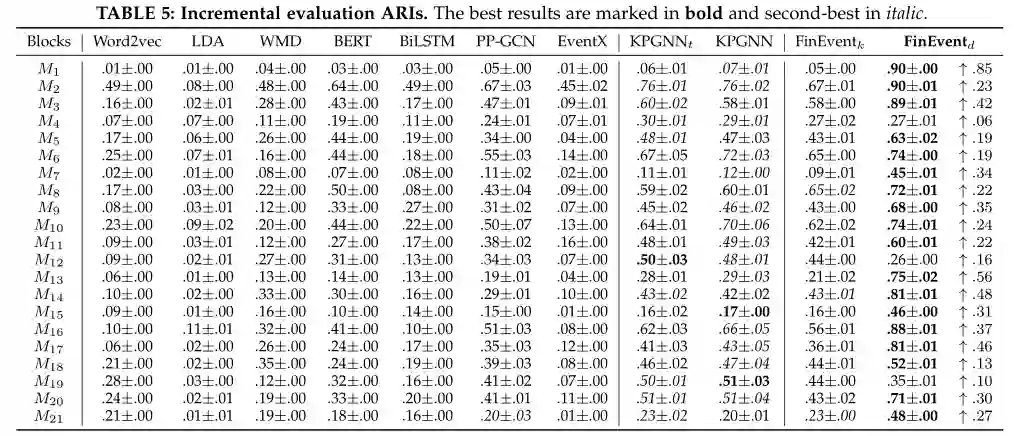
KPGNN 和 FinEventk 都显着且始终优于所有消息块的基线。他们在 NMI 中超过 EventX 8%-32%(平均 21%),在 AMI 中获得 169%-771%(平均 345%),在 ARI 中获得 69%-1782%(平均 560%)。原因是,EventX 仅依赖于社区检测,而 FinEventk 结合了社交消息的语义。它们在 NMI 中比 WMD 高 12%-52%(平均 28%),在 AMI 中高出 11%-63%(平均 29%),在 ARI 和 BERT 中高出 0%-266%(平均 110%) NMI 高达 3%-28%(平均 11%),AMI 高达 1%-33%(平均 13%),ARI 高达 0%-83%(平均 39%)。这是因为我们的设计能够利用 WMD 和 BERT 忽略的社交流的结构信息。它们在 NMI 中的表现也比 PP-GCN 高 42%-65%(平均 53%),在 AMI 中高出 48%-117%(平均 62%),在 ARI 中高出 0%-51%(平均 15%)。这表明我们的设计有效地保留了最新的知识,而随着消息的积累,PP-GCN 可能会被过时的信息分散注意力。
对于 NMI 和 AMI 中的绝大多数消息块,FinEventk 的性能优于 KPGNN 和 KPGNNt。这些改进证明了加权多关系图结构的印象和多智能体引导聚合的积极影响,它包含了更多的关系信息并大大增强了内部和内部聚合。ARI 降低的原因是 ARI 指标更喜欢在事件具有相同大小的聚类时测量性能,但我们实验中的真实事件聚类不平衡(如图 3 所示)。这也解释了 AMI 中 FinEventk 的增加,因为它更喜欢不平衡的集群。MarGNN 和 DRL-DBSCAN 的使用提高了聚类的准确性,但同时可能会加剧社交流带来的事件不平衡的影响。总而言之,FinEventk 的性能优于基线。最后,FinEventd 在 NMI 中显着优于 FinEventk 0%- 1210%,在 AMI 中 0%- 1330%,在 ARI 中 0%- 1700%。这些改进归功于精心设计的 DRL-DBSCAN,证明 DRL-DBSCAN 不仅突破了 K-Means 在流聚类中的限制,而且在深度强化学习代理方面也取得了更好的性能。更重要的是,FinEventd 在 ARI 上有显着的性能,这弥补了 K-Means 在聚类不平衡事件上的局限性。
总体而言,在增量检测场景中,FinEvent 在 NMI 中显着优于其他基线 8%- 136%,在 AMI 中高出 11%- 147%,在 ARI 中高出 24%- 170%。
消融研究 为了评估 MarGNN 的有效性,我们分别对 AGGintra 和 AGGinter 的过程进行了消融研究,分别表示为关系内聚合器和关系内聚合器。对于内部关系聚合器,我们设计了 (a) 共享 GNN,它仅利用一个单独的 GNN 从所有关系图中学习信息;(b) RNN,用 RNN 代替 GNN。为了避免 DBSCAN 中参数选择的影响,我们对所有变体实施 K-Means。如表 6 所示,与 shared-GNN 相比,MarGNN 在 NMI 中的表现优于 3.9%,在 AMI 中优于 4.6%。此外,MarGNN 和 shared-GNN 在 ARI 中的表现分别比 KPGNN 高 6.5%,在 NMI 中高出 4.2%,在 AMI 中高出 4.6%,在 ARI 中高出 6.5%,在 NMI 中高出 0.3%,在 AMI 中高出 0.2%。它表明,整合来自多关系图的不同信息在社会事件检测中至关重要,因为应该充分考虑事件的类型和模式。MarGNN 和 KPGNN 在 NMI 中的表现分别比 RNN 系列高 61.9%、在 AMI 中高出 116.7%、在 ARI 中高出 163.7%、在 NMI 中高出 55.5%、在 AMI 中高出 107.1%、在 ARI 中高出 116.7%。优势可归因于社交消息的图形建模。与基于 GNN 的模型相比,RNN 忽略了社交流中的结构信息。
对于相互关系聚合器,我们采用不同的组合策略:4.2.2 节中提到的连接(Cat.)、Sum 和 MLP。GNNs 和 MLPs 的输出维度设置为 64。如表 6 所示,连接操作可以将 MarGNN 的性能在 NMI 中提高 3.6%,在 AMI 中提高 4.2%,在 ARI 和 MLP 中提高 4.2% 11.3%在 NMI 中,AMI 为 13.2%,ARI 为 15.7%。这归因于直接连接操作可以最好地保留来自社会流的关系之间的知识和结构信息。
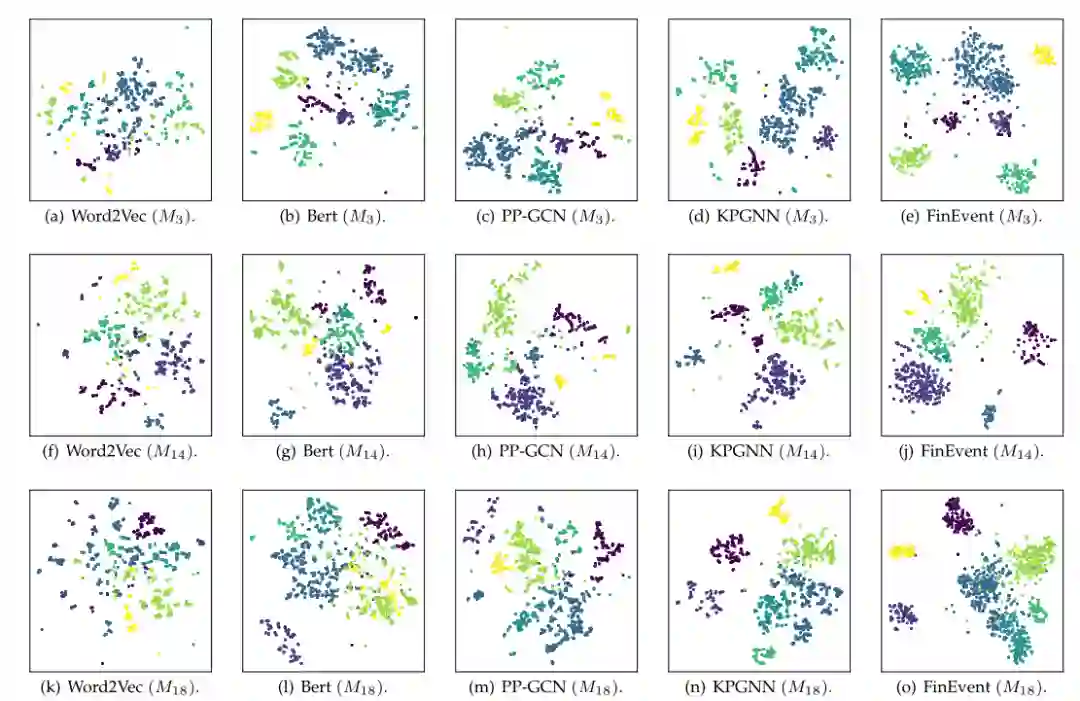
可视化分析 为了更好地衡量 FinEvent 的效果,我们报告了特定块的信息表示的降维可视化,即检测阶段的 M3、M14 和 M18,如图 4 所示。在这些图中,我们专注于按体积计算的前 7 个事件,因为应对社交数据的长尾挑战(图 3)。属于同一事件的消息的表示用相同的颜色标记。比较图 4 中的第 1、2 列与第 3、4 和 5 列,可以观察到,基于 GNN 的方法的聚类结果比仅依赖于表示的方法更紧凑。它展示了将 GNN 引入事件检测的优势。此外,对于 PP-GCN、KPGNN 和 FinEvent 之间的内部比较,显然 FinEvent 取得了更好的性能。这表明 FinEvent 的架构结合不同的 RL 模块可以很好地适应增量事件检测。
6.3 强化学习过程研究
在本节中,我们将重点介绍 FinEvent 中的强化学习过程,分别包括多智能体 RL 引导的最优保留阈值选择和聚合,以及 DRL 引导的 DBSCAN。
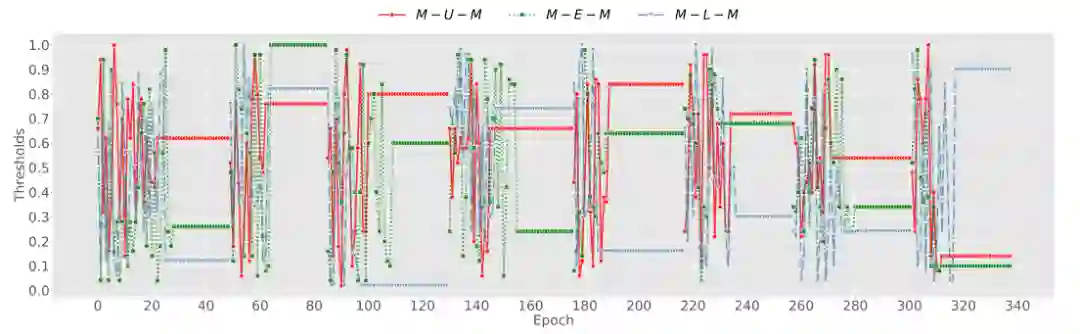
6.3.1 保留阈值
如图 5 所示,我们将训练过程中的所有 epoch 连接起来,包含 1 个预训练阶段(从 epoch 0 到 epoch 50)和 7 个维护阶段(从 epoch 50 到 epoch 340),并可视化每个关系下保留阈值的变化。可以观察到,每个保留阈值在振荡几个 epoch 后逐渐收敛到一个固定值。多智能体稳定地从图结构中学习,直到所有保留阈值都达到最终条件。
我们进一步对增强的邻居选择进行了消融研究。首先,我们验证邻居选择的有效性。具体来说,我们根据其表示距离为每个目标节点选择前 50% 和后 50% 的邻居(第 4.2.1 节)。我们取 21 个区块的 NMI、AMI 和 ARI 结果的平均值。如表 6所示,与选择后 50% 的邻居相比,选择前 50% 的邻居取得了更好的结果,在 NMI 中提高了 3.0%,在 AMI 中提高了 4.3%,在 ARI 中提高了 3.3%。它证明了一些消息或用户确实是社交网络中的噪声,这会损害 GNN 的性能,迫切需要过滤。其次,我们讨论了不同的邻居抽样策略,以验证多智能体引导的 Top-p 邻居抽样的有效性。除了提出的强化策略外,我们还设置了
i)。每个目标节点都有恒定数量的邻居,因为我们利用 2 层 GNN,第一跳的大小设置为 25,[52] 推荐的第二跳的大小设置为 15;
ii)。随机邻居数,第一跳的邻居数在 10 到 100 的范围内随机选择,第二跳的邻居数在 10 到 50 之间。
从表 6 可以看出,强化抽样策略在 NMI 中比随机抽样策略的性能好 1.3%,在 AMI 中好 1.2%,在 ARI 中好 1.4%,在 NMI 中比恒定抽样策略好 0.7%,在 AMI 中好 0.9%,和0.2% 的 ARI。它验证了最佳保存阈值的有效性。在检测阶段由多智能体引导的精心设计的最佳保留阈值的值如表 7 所示。多智能体无需手动固定阈值,而是能够利用他们从块特征(例如信息和关系结构)中学习的经验来在检测阶段自适应地选择最佳保留阈值。我们进一步评估了在相互关系聚合过程中最佳保留阈值的优势。如表 6 所示,所提出的最佳保留阈值可以在 NMI 中将聚合器间的性能提高 0.6%,在 AMI 中提高 0.7%,在 ARI 中提高 1.1%,NMI 提高 0.3%,AMI 提高 0.3%,==AMI 提高 0.7%。总和的 ARI,NMI 为 1.2%,AMI 为 1.6%,MLP 为 4.0%。这为我们假设 4.2.2 节中描述的噪声和关系的重要性提供了重要的解释,即噪声过多的关系对聚合的贡献较小。
表6邻居采样器策略、关系内聚合 AGGintra 和关系间聚合 AGGinter 的消融研究。最佳结果以粗体标记,次佳以斜体标记.
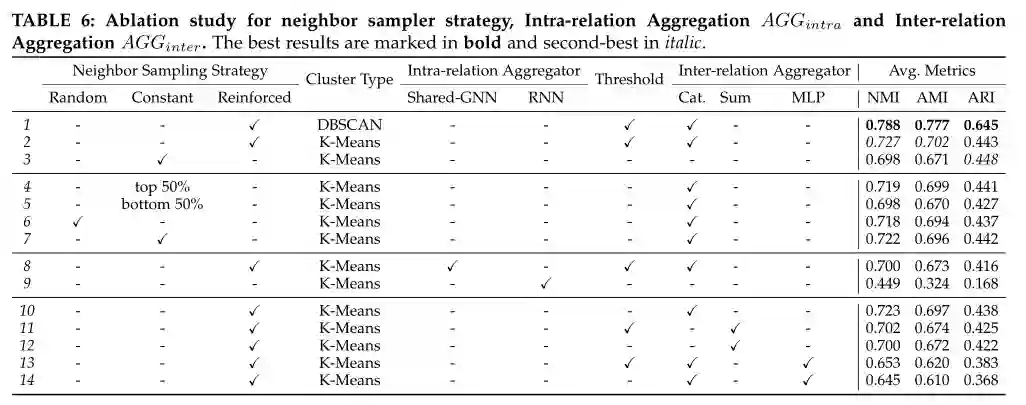
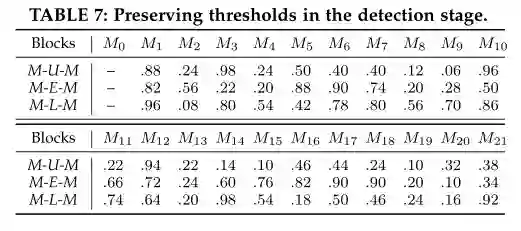
表7在检测阶段保留阈值。
6.3.2 DRL-DBSCAN
平稳分析。 在检测阶段,每个块为 DRL-DBSCAN 创建一个全新的聚类场景,因此深度强化学习智能体会在每个区块重新启动游戏过程。图 6 以块 M7 期间的强化学习过程为例,展示了一个块中的 DBSCAN 参数调整学习过程。我们观察参数Ɛ在图 6(a) 中,在整个动作空间中连续波动,并从第 200 episode开始稳定在 3-4 范围内。这个过程体现了强化学习智能体在与环境交互中获得参数调整经验的过程。此外,每个检测时间段,DRL-DBSCAN 都用于检测一个全新的消息块。我们在表中给出了DRL-DBSCAN在所有检测阶段预测的参数组合。可以看出,最终的参数结果随着消息块的不同而波动。
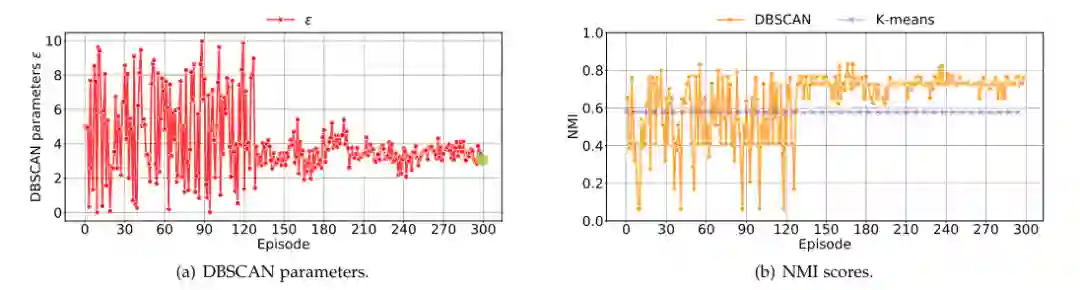
有效性分析。 为了评估方程式中奖励函数的激励能力。在图 11 中,我们测量了所有强化学习参数搜索游戏的收益(仅以块 M7 为例)。图 6(b) 显示了使用我们的 DRL-DBSCAN 的 DBSCAN NMI 变化和使用已知事件数量的 KMeans NMI 变化。值得注意的是,图6(a)中多个episode参数相互作用后,DRLDBSCAN的最终收敛NMI超过了K-Means,这表明启发式外部指标奖励函数可以有效地将参数激发到更高的水平。请注意,KMeans 的奖励保持不变,因为同一时期的事件分布和消息表示是固定的。此外,表8中不同消息块的最终参数对应的完整测量结果如表3、表4和表5所示。通通过与 K-Means 的比较,发现我们的模型在不同的块中具有稳定的优势。
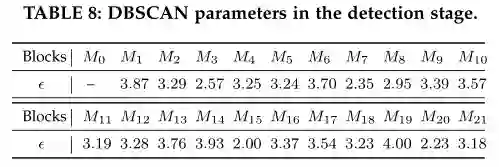
表 8检测阶段的 DBSCAN 参数。
6.4 跨语言迁移评估
如第 3.3 节所述,由于 FinEvent 在保存和扩展知识方面的优势,我们利用这种归纳学习能力来解决跨语言迁移问题。通常,将在高资源英语数据集上训练好的模型转移到低资源非英语数据集,这些数据集通过少量训练样本进行微调,并直接用于检测传入事件。我们将英文 Twitter 数据集作为高资源数据集对 FinEvent 进行预训练,并将其应用于法语 Twitter 数据集上实现跨语言检测,从而在低资源 Twitter 数据集中发挥作用。需要注意的是,这两个数据集完全不同,它们拥有各自的时间戳和事件类型(尽管图 3 中绘制的部分事件是重复的,但事件完全不同)。在我们的实验中,我们直接计算法语消息的文档特征,谷歌翻译首先翻译法语消息,然后获得节点特征。
为了验证我们对跨语言检测的假设,我们比较了 FinEvent 在两种不同情况下的性能:
(a) 我们在处理过的法语数据集上训练了一个新的 FinEvent 检测器,名为 FinEventr(Raw) 和 FinEventg(Google Translated)。设置和维护策略保持不变;
(b) 我们用法语数据集中的初始 M0 对英语数据集中训练好的 FinEvent 进行微调,分别命名为 FinEventcr 和 FinEventcg,并将它们保持在检测阶段,以便从传输的法语数据集中持续检测事件。
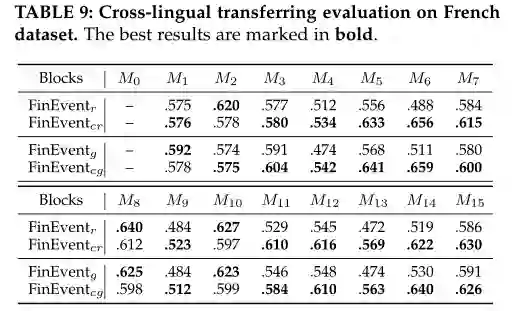
我们在表 9 中将 NMIs 结果作为它们的性能报告。FinEvent 的所有聚类类型都设置为 K-Means,以避免 DBSCAN 中不同参数选择的影响。观察到 FinEventcr 和 FinEventcg 的性能优于 FinEventr 和 FinEventg。具体而言,在15个区块中,FinEventcr与FinEventr相比领先12个区块,实现了1.7%~20.6%的提升。FinEventcg 在 12 个区块中也优于 FinEventg,并实现了 1.7% 到 20.8% 的改进。FinEventr 和 FinEventcr 的块平均 NMI 分别为 0.554 和 0.597。FinEventg 和 FinEventcg 的块平均 NMI 分别为 0.554 和 0.595。FinEventcr 和 FinEventcg 的可行性表明,在高资源英语数据集上训练的 FinE-vent中保存的知识可以扩展并指导低资源非英语数据集上的事件检测。此外,FinEventr 和 FinEventg 的相似性能也让我们了解到,尽管消息的语言表达方式不同,但消息图的语义和结构在事件检测中更为关键。
表9法语数据集的跨语言迁移评估。最佳结果以粗体标记
6.5 时间分析
在本节中,我们将分析在线维护阶段的时间复杂度和消耗,以探索 FinEvent 的实用性。FinEvent 的总运行时间为 O(Ne),其中 O(Ne) 是消息图中的边总数。其中,构建或维护包含 N 条消息的多关系图的时间复杂度为 O(N + Ne) = O(Ne)。MarGNN 框架的聚合取 O(Ne +N R+N +Ne) = O(Ne),其中第一个 O(Ne) 是关系内聚合的复杂度,O(NR + N ) 是关系间聚合的复杂度关系聚合,第二个 O(Ne) 是强化邻居选择的复杂度。其中,R为关系数。对于BasCL机制,损失计算需要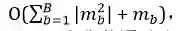
7 相关工作
社会事件检测。根据它们的目标,社会事件检测方法可以大致分为文档枢轴(DP)方法[9]、[14]、[53]-[56]:旨在根据相关性和特征枢轴 (FP) 对社会信息进行聚类:旨在根据其分布对社会消息元素(例如单词和命名实体)进行聚类。目前的 Fin-Event 是一种 DP 方法。根据其应用场景,社会事件检测方法可分为离线[9]和在线[4]、[13]、[14]、[54]、[56]、[58]方法。尽管离线方法在分析灾难、股票市场交易、重大体育赛事和政治运动等回顾性、特定领域的事件时必不可少,但需要持续处理动态社会流的在线方法 [4]、[13]、[58 ]。对于不同的技术和机制,社会事件检测方法可以分为几种常用的类例如依赖于增量聚类的方法[53]、[54]、[56]、社区检测[13]、[14]、[18]、[ 22]和主题模型[55]。然而,这些方法受到潜在知识的限制,因为它们在一定程度上忽略了社会流中包含的丰富语义和结构信息。此外,这些模型的参数太少,无法保存学习到的知识。虽然text - simclnn [58]提出了一种基于图注意网络和对比学习的文本语义编码方法,但没有充分考虑社会信息之间的结构特征和关系,甚至通过单个文档来判断集群,而不考虑出现在同一时期的相邻文档的共同贡献,这使得本应属于现有集群的节点很容易被误认为是一个新的集群。[9] 和 [59] 都属于基于 GNN 的社会事件检测方法,但这些模型只实现静态事件分类,只能离线工作。FinEvent 不同于现有方法,因为它通过不断适应传入的社会信息来有效地获取、扩展、保存和转移知识。
图神经网络的归纳学习。图神经网络(GNN)[29]、[48]、[60]-[63] 已广泛用于图数据表示学习和应用。一般来说,GNN 从源邻域中提取、聚合和更新节点上下文表示,从而实现跨图结构的数据扩散。由于某些GNN[48]需要已知的、固定的图结构,根据其提取和聚合策略,它们只能进行转导学习[64]。其他 [29]、[60]、[65] 可用于归纳学习 [64],这意味着它们无需重复训练即可应用于新的测试模式。尽管经常讨论,但在实际应用场景中很少评估或使用GNN 的归纳学习 [64]。提出的 FinEvent 是第一个利用 GNN 的归纳学习能力进行增量社会事件检测的。
结合 GNN 和强化学习。有一些尝试将 GNN 和 RL 结合起来以提高图数据的表示学习能力。DeepPath [66] 是基于 RL 策略的知识图谱嵌入和推理框架,训练 RL 代理以确定知识库中的推理路径。RL-HGNN [67] 设计了不同的元路径来学习其有效表示,并使用基于 DRL 的策略网络在下游任务中进行自适应元路径选择。与 MarGNN 相比,RL-HGNN 模型更注重在异构图分析中揭示有意义的元路径或关系。与我们的 MarGNN 类似,CARE-GNN [27] 使用 Bernoulli Multi-armed Bandit 过程来选择邻居,Rio-GNN [68] 使用递归强化学习来加速离线时平衡滤波器阈值的过程。以提高 GNN 的有效性,但这些模型不再适用于加权图和增量场景。GraphNAS [69] 使用 RL 来搜索最优的图神经架构。Policy-GNN [70] 将 GNN 训练问题表述为马尔可夫决策过程,并且可以自适应地学习聚合策略以对不同节点的聚合的不同迭代进行采样。然而,GraphNAS 和 Policy-GNN 模型都没有考虑聚合中的异构邻域,尽管它们更关注神经架构搜索。
基于密度的流聚类。基于密度的流数据聚类方法 [4]、[71]-[74] 是广泛的社会数据挖掘和分析的基础技术。然而,与这些聚类方法相比,DRL-DBSCAN首先探索了如何将DBSCAN与深度强化学习方法相结合,在没有离线维护过程的情况下获得稳定的社会事件聚类效果。
8 结论
本文研究了 FinEvent 一种来自流式社会消息的强化、增量和跨语言的社会事件检测架构。为了学习社会消息嵌入,提出了一种多智能体强化学习引导的多关系图神经网络框架 MarGNN。深度强化学习引导的基于密度的空间聚类模型 DRL-DBSCAN 旨在选择事件检测任务中的最佳参数。在 Twitter 流上进行的实验表明,FinEvent 在离线、在线和跨语言社会事件检测任务的性能方面实现了显著且持续的模型质量改进。未来,我们的目标是扩展多智能体 RL 引导的 GNN,以学习复杂的图数据表示及其应用,例如事件相关性、事件演化等。此外,研究如何将我们的模型扩展到其他聚类任务也是很有意义的。
参考文献
[1] M. Cordeiro and J. Gama,“Online social networks event detection:a survey,” in Solving Large Scale Learning Tasks. Challenges and Algorithms. Springer, 2016, pp. 1–41.
[2] J. Allan, Topic detection and tracking: event-based information organization. Springer Science & Business Media, 2012, vol. 12.
[3] Z. Wang, Y. Zhang, Y. Li, Q. Wang, and F. Xia,“Exploiting social influence for context-aware event recommendation in event-based social networks,” in Proceedings of the IEEE INFOCOM, 2017, pp.1–9.
[4] H. Peng, J. Li, Y. Song, R. Yang, R. Ranjan, P. Yu, and L. He,“Streaming social event detection and evolution discovery in heterogeneous information networks,” ACM TKDD, vol. 15, no. 5,pp. 1–33, 2021.
[5] R. Gaspar, C. Pedro, P. Panagiotopoulos, and B. Seibt,“Beyond positive or negative: Qualitative sentiment analysis of social media reactions to unexpected stressful events,” Computers in Human Behavior, vol. 56, pp. 179–191, 2016.
[6] T. M. Nisar and M. Yeung,“Twitter as a tool for forecasting stock market movements: A short-window event study,” The journal of finance and data science, vol. 4, no. 2, pp. 101–119, 2018.
[7] F. Marozzo and A. Bessi,“Analyzing polarization of social media users and news sites during political campaigns,” Social Network Analysis and Mining, vol. 8, no. 1, pp. 1–13, 2018.
[8] C. Shi, Y. Li, J. Zhang, Y. Sun, and S. Y. Philip,“A survey of heterogeneous information network analysis,” IEEE TKDE, vol. 29,no. 1, pp. 17–37, 2016. [9] H. Peng, J. Li, Q. Gong, Y. Song, K. Lai, and P. S. Yu,“Fine-grained event categorization with heterogeneous graph convolutional networks,” in Proceedings of the IJCAI, 2019, pp. 3238–3245.
[10] Y. Cao, H. Peng, J. Wu, Y. Dou, J. Li, and P. S. Yu,“Knowledge-preserving incremental social event detection via heterogeneous gnns,” in Proceedings of the Web Conference, 2021, pp. 3383–3395.
[11] W. Yu, C. C. Aggarwal, S. Ma, and H. Wang,“On anomalous hotspot discovery in graph streams,” in Proceedings of the IEEE ICDM, 2013, pp. 1271–1276.
[12] D. Eswaran, C. Faloutsos, S. Guha, and N. Mishra,“Spotlight:Detecting anomalies in streaming graphs,” in Proceedings of the ACM SIGKDD, 2018, pp. 1378–1386.
[13] M. Fedoryszak, B. Frederick, V. Rajaram, and C. Zhong,“Real-time event detection on social data streams,” in Proceedings of the ACM SIGKDD, 2019, pp. 2774–2782.
[14] B. Liu, F. X. Han, D. Niu, L. Kong, K. Lai, and Y. Xu,“Story forest: Extracting events and telling stories from breaking news,” ACM TKDD, vol. 14, no. 3, pp. 1–28, 2020.
[15] Q. Li, H. Peng, J. Li, J. Wu, Y. Ning, L. Wang, S. Y. Philip, and Z. Wang,“Reinforcement learning-based dialogue guided event extraction to exploit argument relations,” IEEE/ACM TASLP, pp.1–1, 2021.
[16] S. Zhao, Y. Gao, G. Ding, and T.-S. Chua,“Real-time multimedia social event detection in microblog,” IEEE transactions on cybernetics, vol. 48, no. 11, pp. 3218–3231, 2017.
[17] A. Subburathinam, D. Lu, H. Ji, J. May, S.-F. Chang, A. Sil, and C. Voss,“Cross-lingual structure transfer for relation and event extraction,” in Proceedings of the EMNLP-IJCNLP, 2019, pp. 313–325.
[18] J. Liu, Y. Chen, K. Liu, and J. Zhao,“Event detection via gated multilingual attention mechanism,” in Proceedings of the AAAI,2018, pp. 4865–4872.
[19] A. Goswami and A. Kumar,“A survey of event detection techniques in online social networks,” Social Network Analysis and Mining, vol. 6, no. 1, pp. 1–25, 2016.
[20] C. Zhang, L. Liu, D. Lei, Q. Yuan, H. Zhuang, T. Hanratty,and J. Han,“Triovecevent: Embedding-based online local event detection in geo-tagged tweet streams,” in Proceedings of the ACM SIGKDD, 2017, pp. 595–604.
[21] D. T. Nguyen and J. E. Jung,“Real-time event detection for online behavioral analysis of big social data,” FGCS, vol. 66, pp. 137–145,2017.
[22] W. Yu, J. Li, M. Z. A. Bhuiyan, R. Zhang, and J. Huai,“Ring: Realtime emerging anomaly monitoring system over text streams,”IEEE Transactions on Big Data, vol. 5, no. 4, pp. 506–519, 2017.
[23] X. Tan, J. Chen, D. He, Y. Xia, Q. Tao, and T.-Y. Liu,“Multilingual neural machine translation with language clustering,” in Proceedings of the EMNLP-IJCNLP, 2019, pp. 962–972.
[24] V. R. Konda and J. N. Tsitsiklis,“Actor-critic algorithms,” in Proceedings of the NIPS, 2000, pp. 1008–1014.
[25] S. Fujimoto, H. van Hoof, and D. Meger,“Addressing function approximation error in actor-critic methods,” in Proceedings of the ICML, vol. 80. PMLR, 2018, pp. 1587–1596.
[26] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean,“Distributed representations of words and phrases and their compositionality,” in Proceedings of the NIPS, 2013, p. 3111–3119.
[27] Y. Dou, Z. Liu, L. Sun, Y. Deng, H. Peng, and P. S. Yu,“Enhancing graph neural network-based fraud detectors against camouflaged fraudsters,” in Proceedings of the ACM CIKM, 2020, pp. 315–324.[28] L. Yang, Z. Liu, Y. Dou, J. Ma, and P. S. Yu,“Consisrec: Enhancing gnn for social recommendation via consistent neighbor aggregation,” in Proceedings of the ACM SIGIR, 2021, pp. 2141–2145.
[29] P. Veliˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y.
Bengio,“Graph attention networks,” in Proceedings of the ICLR,2018, pp. 1–12. [30] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N.Gomez,Ł. Kaiser, and I. Polosukhin,“Attention is all you need,”in Proceedings of the NeurIPS, 2017, pp. 5998–6008.
[31] K. Hassani and A. H. Khasahmadi,“Contrastive multi-view representation learning on graphs,” in Proceedings of the ICML, vol. 119.PMLR, 2020, pp. 4116–4126.
[32] Y. Tian, C. Sun, B. Poole, D. Krishnan, C. Schmid, and P. Isola,“What makes for good views for contrastive learning?” in Proceedings of the NeurIPS, vol. 33, 2020, pp. 6827–6839.
[33] F. Schroff, D. Kalenichenko, and J. Philbin,“Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the CVPR. IEEE, 2015, pp. 815–823.
[34] A. Hermans, L. Beyer, and B. Leibe,“In defense of the triplet loss for person re-identification,” arXiv preprint arXiv:1703.07737, 2017.
[35] R. D. Hjelm, A. Fedorov, S. Lavoie-Marchildon, K. Grewal, P. Bachman, A. Trischler, and Y. Bengio,“Learning deep representations by mutual information estimation and maximization,” in Proceedings of the ICLR, 2019, pp. 1–14.
[36] M. I. Belghazi, A. Baratin, S. Rajeshwar, S. Ozair, Y. Bengio,A. Courville, and D. Hjelm,“Mutual information neural estimation,” in Proceedings of the ICML, vol. 80. PMLR, 2018, pp. 531–540.
[37] P. Velickovic, W. Fedus, W. L. Hamilton, P. Lio, Y. Bengio, and R. D.Hjelm,“Deep graph infomax,” in Proceedings of the ICLR, 2019, pp.1–13.
[38] M. Ester, H.-P. Kriegel, J. Sander, X. Xu et al.,“A density-based algorithm for discovering clusters in large spatial databases with noise.” in Proceedings of the ACM SIGKDD, vol. 96, no. 34, 1996, pp.226–231.
[39] P. J. Rousseeuw,“Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,” Journal of Computational and Applied Mathematics, vol. 20, pp. 53–65, 1987.
[40] L. Van der Maaten and G. Hinton,“Visualizing data using t-sne.”JMLR, vol. 9, no. 11, pp. 2579–2605, 2008.
[41] T. Cali ´nski and J. Harabasz,“A dendrite method for cluster analysis,” Communications in Statistics-theory and Methods, vol. 3,no. 1, pp. 1–27, 1974. [42] T. Mohiuddin, M. S. Bari, and S. Joty,“Lnmap: Departures from isomorphic assumption in bilingual lexicon induction through non-linear mapping in latent space,” in Proceedings of the EMNLP,2020, pp. 2712–2723.
[43] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” in Proceedings of ICLR, 2013, pp. 1–12.
[44] D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichlet allocation,” JMLR, vol. 3, no. Jan, pp. 993–1022, 2003.
[45] M. Kusner, Y. Sun, N. Kolkin, and K. Weinberger, “From word embeddings to document distances,” in Proceedings of the ICML, 2015, pp. 957–966.
[46] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pretraining of deep bidirectional transformers for language understanding,” in Proceedings of the NAACL, 2019, pp. 4171–4186.
[47] A. Graves and J. Schmidhuber, “Framewise phoneme classification with bidirectional lstm and other neural network architectures,” Neural networks, vol. 18, no. 5-6, pp. 602–610, 2005.
[48] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in Proceedings of ICLR, 2017, pp. 1–10.
[49] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in Proceedings of the EMNLP, 2014, pp. 1532–1543.
[50] P. A. Estevez, M. Tesmer, C. A. Perez, and J. M. Zurada, “Normal- ´ ized mutual information feature selection,” IEEE Transactions on neural networks, vol. 20, no. 2, pp. 189–201, 2009.
[51] N. X. Vinh, J. Epps, and J. Bailey, “Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance,” JMLR, vol. 11, pp. 2837–2854, 2010.
[52] W. Hu, M. Fey, M. Zitnik, Y. Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec, “Open graph benchmark: Datasets for machine learning on graphs,” arXiv preprint arXiv:2005.00687, 2020.
[53] C. C. Aggarwal and K. Subbian, “Event detection in social streams,” in Proceedings of the SDM. SIAM, 2012, pp. 624–635.
[54] L. Hu, B. Zhang, L. Hou, and J. Li, “Adaptive online event detection in news streams,” Knowledge-Based Systems, vol. 138, pp. 105–112, 2017.
[55] X. Zhou and L. Chen, “Event detection over twitter social media streams,” VLDB Journal, vol. 23, no. 3, pp. 381–400, 2014.
[56] K. Zhang, J. Zi, and L. G. Wu, “New event detection based on indexing-tree and named entity,” in Proceedings of the ACM SIGIR, 2007, pp. 215–222.
[57] G. P. C. Fung, J. X. Yu, P. S. Yu, and H. Lu, “Parameter free bursty events detection in text streams,” in Proceedings of the VLDB. Citeseer, 2005, pp. 181–192.
[58] C. Tong, H. Peng, X. Bai, Q. Dai, R. Zhang, Y. Li, H. Xu, and X. Gu, “Learning discriminative text representation for streaming social event detection,” IEEE TKDE, pp. 1–1, 2021.
[59] W. Cui, J. Du, D. Wang, F. Kou, and Z. Xue, “Mvgan: Multi-view graph attention network for social event detection,” ACM TIST, vol. 12, no. 3, pp. 1–24, 2021.
[60] W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” in Proceedings of the NeurIPS, 2017, pp. 1024–1034.
[61] F. M. Bianchi, D. Grattarola, L. Livi, and C. Alippi, “Graph neural networks with convolutional arma filters,” IEEE TPAMI, pp. 1–12, 2021.
[62] Z. Chen, X.-S. Wei, P. Wang, and Y. Guo, “Learning graph convolutional networks for multi-label recognition and applications,” IEEE TPAMI, pp. 1–16, 2021.
[63] T. Schnake, O. Eberle, J. Lederer, S. Nakajima, K. T. Schutt, K.-R. Mueller, and G. Montavon, “Higher-order explanations of graph neural networks via relevant walks,” IEEE TPAMI, pp. 1–1, 2021.
[64] L. Galke, I. Vagliano, and A. Scherp, “Can graph neural networks go” online”? an analysis of pretraining and inference,” in Proceedings of the ICLR, 2019, pp. 1–5.
[65] G. Ciano, A. Rossi, M. Bianchini, and F. Scarselli, “On inductivetransductive learning with graph neural networks,” IEEE TPAMI, pp. 1–1, 2021.
[66] W. Xiong, T. Hoang, and W. Y. Wang, “Deeppath: A reinforcement learning method for knowledge graph reasoning,” in Proceedings of the EMNLP. ACL, 2017, pp. 564–573.
[67] Z. Zhong, C.-T. Li, and J. Pang, “Reinforcement learning enhanced heterogeneous graph neural network,” arXiv preprint arXiv:2010.13735, 2020.
[68] H. Peng, R. Zhang, Y. Dou, R. Yang, J. Zhang, and P. S. Yu, “Reinforced neighborhood selection guided multi-relational graph neural networks,” ACM TOIS, pp. 1–46, 2021.
[69] Y. Gao, H. Yang, P. Zhang, C. Zhou, and Y. Hu, “Graph neural architecture search,” in Proceedings of the IJCAI, 2020, pp. 1403– 1409.
[70] K.-H. Lai, D. Zha, K. Zhou, and X. Hu, “Policy-gnn: Aggregation optimization for graph neural networks,” in Proceedings of the ACM SIGKDD, 2020, p. 461–471.
[71] Y. Chen and L. Tu, “Density-based clustering for real-time stream data,” in Proceedings of the ACM SIGKDD, 2007, pp. 133–142.
[72] G. Petkos, S. Papadopoulos, and Y. Kompatsiaris, “Social event detection using multimodal clustering and integrating supervisory signals,” in Proceedings of the ACM ICMR, 2012, pp. 1–8.
[73] C. C. Aggarwal, “A survey of stream clustering algorithms,” in Data Clustering. Chapman and Hall/CRC, 2018, pp. 231–258.
[74] C. Comito, C. Pizzuti, and N. Procopio, “Online clustering for topic detection in social data streams,” in Proceedings of the ICTAI. IEEE, 2016, pp. 362–369.
1 附录
A. 最佳保存阈值评估
深层分析。 保留阈值也代表了一种可解释的方法来克服 GNN 中深层的过度拟合和过度平滑问题。为了验证我们的推论,我们设计了三种 FinEvent 变体具有 4/8/32 层,及其相应的模型,而不保留阈值。我们仍然采用最新消息策略并将窗口大小设置为 1,并在图 1 中报告模型在 M9 到 M14 上的性能。观察到保留阈值的 FinEvent 提高了所有案例的检测效果,并且随着层的增长,改进会更大。与 [1] 随机丢弃图中的边不同,FinEvent 中的多智能体根据某些规则及其学习实验丢弃边。综上所述,FinEvent 为深度 GNN 的改进提供了合理的边缘下降指令。
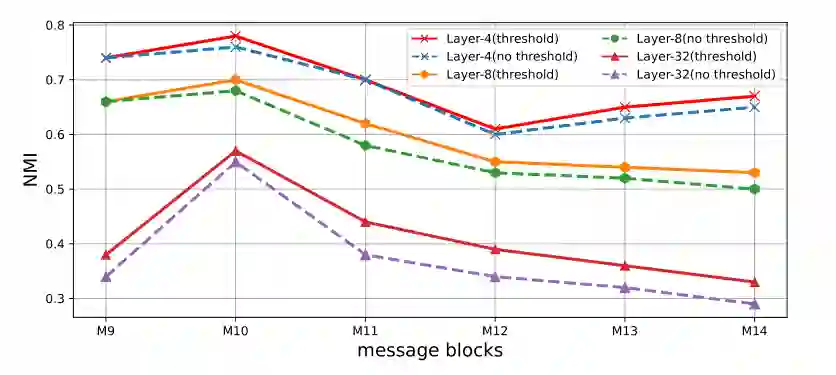
可解释性分析 此外,在训练或检测阶段,不同的智能体s最终会选择不同的保留阈值。各种阈值表示智能体s做出的不同贡献,可以抽象为 GNN 对不同关系的宏观关注。例如,如 M3 所示,关系 M-E-M 获得比其他关系更高的阈值,可能是因为在该块中占据更高的重要性。为了方便观察关系贡献的流动,我们还将一周内的保留阈值显示为雷达图(如图 2 所示)。它演示了块和事件结构随时间的变化。封闭区域可以近似视为一个关系对本周事件的整体贡献,因此我们可以直观地获得全局关系重要性。所有这些都为 GNN 事件检测提供了必要的可解释解释。
2 附录
B. 超参数敏感性
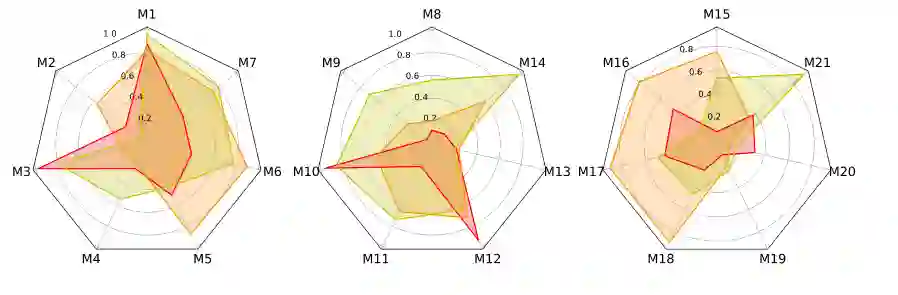
本小节研究超参数在增量社会事件检测实验中的影响。我们将 Twitter 数据集的隐藏嵌入维度设置为 128,以尽可能减少图熵,并且仅更改输出嵌入维度 d 和窗口大小 w。图 4 比较了 FinEvent 在采用不同的输出维度以及每个消息块的窗口大小时的性能。NMI、AMI 和 ARI 结果的平均偏差范围为 0.010.03。这表明 FinEvent 的指标随 d 和 w 变化,但相当显着。输出嵌入维度对 FinEvent 的性能影响不大。例如,输出嵌入维度的块平均 NMI 分别为 0.701、0.719、0.716。当 d 设置为 64 时,FinEvent 达到最佳性能。通常采用较小的窗口大小(2 或 3)会提供稍好的性能。例如,不同窗口大小的块平均 NMI 分别为 0.719、0.729、0.723、0.714,平均 AMI 分别为 0.693、0.702、0.698、0.687。当窗口大小设置为 3 时,FinEvent 获得最佳性能。一个可能的原因是,对于 Twitter 数据集,w = 3 对事件延续的适应性最好。总之,FinEvent 对超参数的变化很敏感。
3 附录
C.社会流统计
本节分别描述了来自英语和法语数据集的每个块中的消息数量和事件数量。具体如表1和表2所示。另外,社会流的时间消耗如图3所示
参考文献
[1] Y. Rong, W. Huang, T. Xu, and J. Huang,“Dropedge: Towards deep graph convolutional networks on node classification,” in Proceedings of the ICLR, 2020.
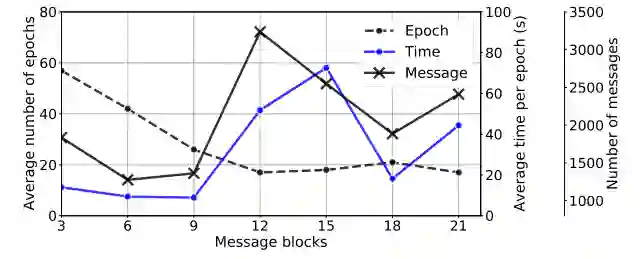
表 1:来自英语 Twitter 数据集的社会流的统计数据。
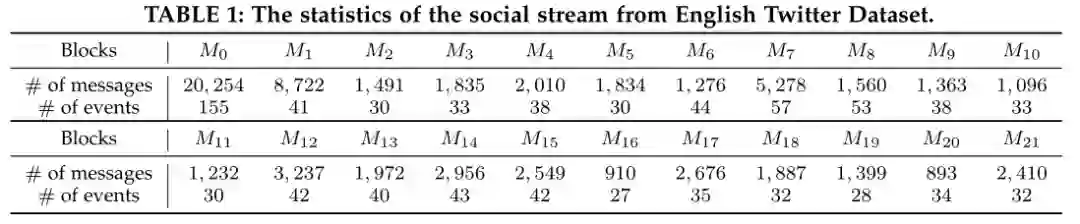
表 2:来自法国 Twitter 数据集的社会流的统计数据。
参考资料
卡拉巴萨斯直升机坠毁: https://en.wikipedia.org/wiki/2020
[2]开源1: https://github.com/huggingface/transformers
[3]开源2: https://github.com/RingBDStack/PPGCN
[4] 开源3: https://github.com/RingBDStack/KPGNN专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“FINE” 就可以获取《TPAMI2022 || 基于图神经网络实现强化的、增量和跨语言社会事件检测》论文专知下载链接


