香港中大-商汤科技联合实验室AAAI录用论文详解:超大规模分类加速算法
近日,香港中大-商汤科技联合实验室的新论文“Accelerated Training for Massive Classification via Dynamic Class Selection”被AAAI 2018录用为Oral Presentation。该论文着力于解决超大规模分类问题(过百万类)对模型训练带来的一系列挑战,尤其是超大规模Softmax层造成的计算瓶颈。具体而言,该论文提出了一种新型的Dynamic Selective Softmax,能够以较低的代价在每次迭代中根据类别空间的结构动态选择一小部分类别参与计算,在保证精度基本一致的条件下,可以非常显著地提升训练速度,并大幅度减少训练过程所占用的显存。本文中我们将详细介绍该论文中提出的方法,并介绍一些可能的后续工作等。
值得指出的是,这项工作是由商汤科技在城市级人脸识别的场景所驱动。而此项工作的成果也反映了在人工智能领域产业应用对于学术创新的重要意义。
作者:张行程,杨磊,闫俊杰,林达华
一个实际的问题—人脸识别
随着数据的迅速积累,数据的类别数目也在不断增加,大规模分类的问题受到越来越广泛的重视,人脸识别就是其中一个重要的例子。在先前的一些人脸识别的工作中[2],基于分类的训练方式因其简单且能提供高效监督信息的特点,为学界和工业界广泛使用。
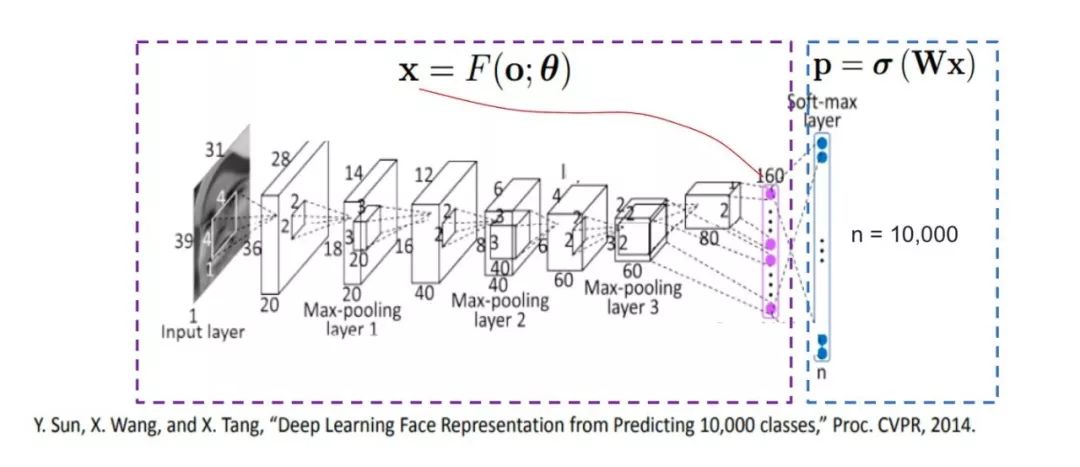
图1 基于分类方法的人脸识别训练流程
然而,如下图所示,随着类别数量急剧增加,两个实际的问题浮出水面:1)计算Softmax所需要的计算量会大大增加,使得Softmax的计算成为制约网络训练速度的瓶颈。2)类别数量的增加会导致分类层的参数量大大增加,在如今GPU显存有限的情况下,会极大制约能够参与分类的类别数量。
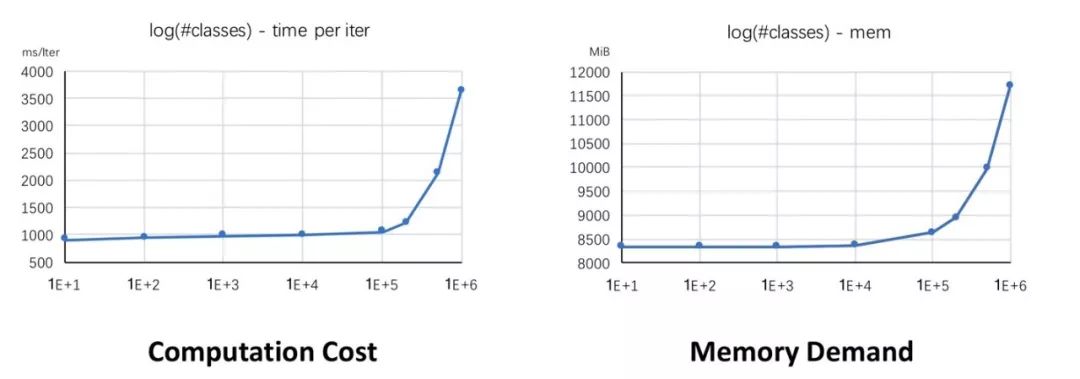
图2 类别数量增加时
对应的计算量和显存的变化
针对类别数增加时带来的计算增长和显存增加的挑战,本论文提出了一种全新的选择性Softmax计算框架,我们称之为“基于动态类别选择的Softmax”(Dynamic Selective Softmax)。该框架可以显著减少训练过程中的计算量以及显存消耗,并且取得近似完整Softmax训练的性能。
对两个指标的观察
我们定义了两个指标来帮助我们分析大规模分类的问题。第一个指标叫做CP_K,即前K累加概率和,表示Softmax计算出的前K大的概率的总和。CP_K的值越大表示概率越集中在前K个的类别中。
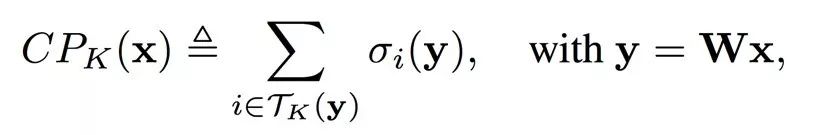
进一步地,从Softmax的梯度公式可知,除了真实标签之外,其它类别的梯度和概率大小成正比。这说明如果概率是集中在前K个类别中,那么对应的梯度值也是集中在前K个类别中。
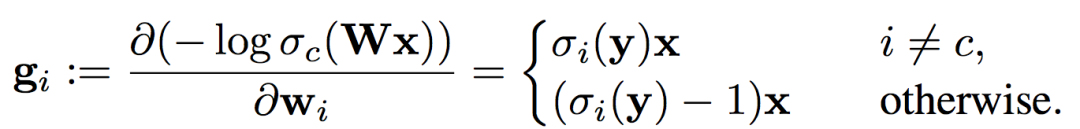
因此,我们进一步定义了一个指标NCG_K,即前K归一化累计梯度。这个指标衡量了梯度在前K个类别上的集中程度。
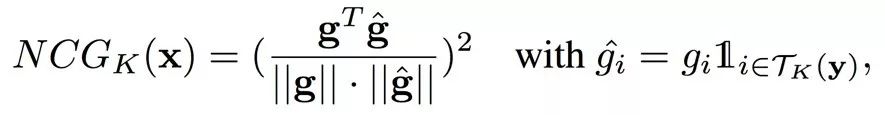
根据定义,我们用一个在Ms1MCeleb上训练好的Resnet-101模型,画出了NCG_K随着迭代轮数变化的曲线。
从上图中我们可以得到几点重要的观察:1)在多数情况下,一个样本只容易和一小部分的类别混淆。2)当使用Softmax作为损失函数时,从这一小部分类别产生的梯度主导了所有的梯度。3)随着训练的进行,容易混淆的类别的集合会越来越小。
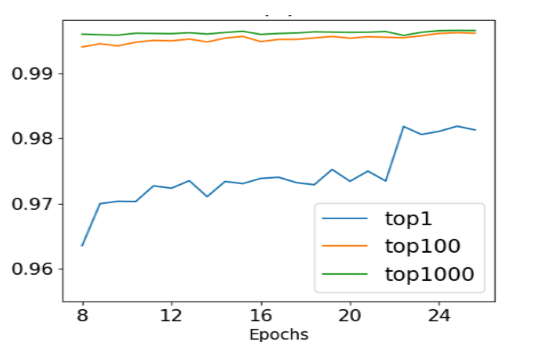
图3 Softmax计算中的“活跃类别”
如图所示,这K个概率值最大的类别主导了Softmax计算,我们将其称之为“活跃类别”。
选择性Softmax框架
基于上述观察,我们提出了一种选择性的Softmax框架。该框架引入了一个选择器,该选择器通过结合当前特征和分类的权重矩阵,能够高效且准确地挑选出分类上能够产生较强监督信号的“活跃类别”。根据之前的分析,“活跃类别”可以近似提供和所有类别同样有效的监督信息,因此,对于这占整体类别比例很小的“活跃类别”,我们可以利用一些稀疏性的操作来加速整体的计算流程。
如下图所示,我们将大规模分类所需要的巨大的权重矩阵放置于CPU的内存中,根据选择器挑选出的类别,可以从这个巨大的权重矩阵中挑选出需要的权重向量,放置到GPU的显存中。当在GPU上计算出对应的梯度之后,再异步地将求出的梯度稀疏更新到存在于CPU上的权重矩阵中。
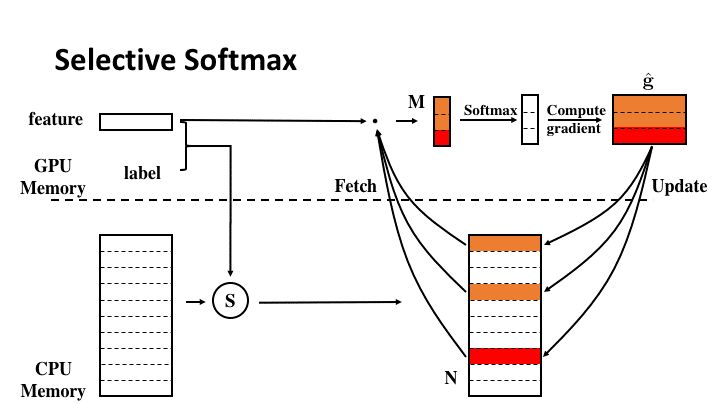
图4 选择性Softmax工作流程示意图
To Be or not to be的困局
根据上文的介绍,选择性Softmax框架的一大核心是“活跃类别”的选择器,如何找到一种高效且准确的选择器成为这个计算框架的关键。首先我们研究了两种最为直观的选择器。
第一种是随机选择器。在每一轮迭代中,除了当前训练样本、的类别,还会通过随机采样得到其余的类别。该随机选择器不依赖于当前样本的特征和分类层权重矩阵的信息,几乎没有额外的时间开销,也因为是随机选取,没有引入任何额外信息,该方法的性能可以被视为是选择器的性能下界。
第二种是最优选择器。在每一轮迭代中,会根据当前样本的特征和整个特征矩阵点乘的结果,从中选取响应最大的类别,用这些类别来作为“活跃类别”。这种方法保证了每次选取出来的活跃类别都是最优的,但是由于引入了整个权重矩阵参与计算,无法减少前传的计算开销,这有悖于我们减少计算量的初衷。但最优选择器每次都选取了最活跃的类别,该方法的性能可以被视为是选择器性能的上界。
如图所示,随机选择器虽然速度快,但是损失了精度;最优选择器虽然保证了精度,但是没有减少计算开销。这两种选择器都无法满足我们的设计要求,因此,我们希望找到一种在速度和精度上都可以取得较好平衡的“活跃类别”选择器。
哈希森林选择器
为了有一个速度和精度上可以达到良好平衡的选择器,我们提出了哈希森林选择器。我们将从哈希森林的构建和哈希森林的使用两个方面来介绍这一算法。
对于哈希森林的构建,我们首先来看一棵哈希树的构建。对于N个类别分类的权重矩阵,我们可以将这个权重矩阵看作是N个类别的平均特征向量,那么我们就得到了D维空间的N个点。首先,我们从这N个点中随机选择2个点,计算出距离这两个点距离最大的超平面,也即,该超平面把这两个点划分在了空间的两侧。那么,根据这个计算出的超平面,我们就可以把空间中的其它点分为两部分,即在超平面的不同侧。这样,我们就把空间分成了两个子空间。对于每一个子空间,我们会重复上面的过程,即每次随机选取2个点,计算出超平面对空间进行划分,当子空间中点的个数不超过B个点时停止继续划分。经过若干次操作后,当所有子空间中的点的个数都不超过B个点时,构建过程结束。如果将每个划分的超平面视为中间节点,将最终划分后的结果视为叶子结点,那么构建的这个结构就可以被当成是一棵哈希树。
从一棵哈希树的构建过程可以看出,我们构建哈希树时采用的是随机算法,因此,为了消除随机选取带来的不稳定性,我们会同时生成L棵哈希树,这样就组成了哈希森林。
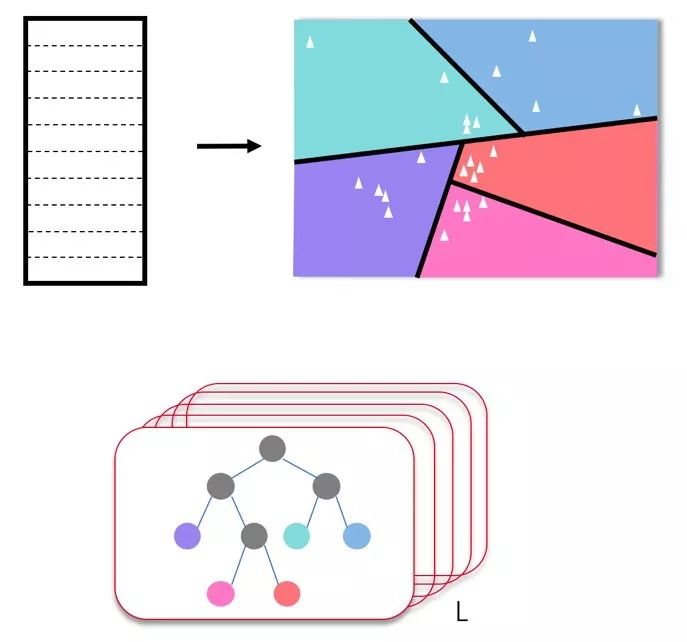
图5 哈希森林的构建
对于哈希森林的使用,我们也先来看每棵哈希树对应的操作。对于每一颗哈希树,树上的中间节点都是一个超平面。因此,当一个新的特征向量来了之后,首先会被根结点的超平面分到左子树或者右子树,接着又会被相应子树的根节点继续往下分类,直到落入一个叶子结点中。那么叶子结点中所包含的类别就被认为是和这个特征向量相似的类别。
对于森林中的每一棵树,都会重复这个过程,最终会得到一个类别的候选集合,如果候选集合中的类别超出了我们所需的类别数目,我们再通过计算其余弦距离,最终选取余弦距离最小的那些类别作为我们的“活跃类别”。
更好的平衡—动态选择性Softmax
虽然哈希森林的选择器在保证准确率的同时大大提升了我们的效率,但从之前对两个指标的观察中,我们可以看到,随着训练的进行,所需要的活跃类别数越来越少,因此我们可以针对选择器中引入的参数做动态调整,进一步优化计算资源的配置。
为此,我们引入了一个阈值,每隔一段时间,在验证集合上计算出CP_K(前K概率累加和),我们选取的类别数K恰好使得算出的CP_K超过定义的阈值。相比于预先设定好采样类别数,这种方式随着训练的进行,K的值会越来越小,也即需要采样的类别数会越来越少,这样可以进一步减少无用的计算资源消耗。
对于新引入的阈值和另外两个参数,树的数目和更新周期。基于“训练初期多尝试不同的可能,训练稳定后寻求更精准的选择”这一理念,我们发现简单的线性更新的方式就可以取得不错的效果,也即:阈值由小到大线性增长,树的数目由少线性增多,更新周期由大线性减小。
实验结果
我们在两个分布迥异的人脸识别数据集上来验证选择性Softmax的性能。第一个数据集是Ms1M Celeb,该数据集包括10万人共1000万张图,由于原始的数据集有比较多的噪声,我们进行了一些清理,实际用于实验的是8.7万人约460万张图。第二个数据集是Megaface Challenge 2的训练数据。该数据集共有67万人约470万人。我们在4个不同的人脸识别标准协议上测试了方法的性能,即LFW非受限的人脸验证协议,人脸识别协议,IJB-A的1:1人脸验证协议以及Megaface的人脸识别协议。
在这些不同的协议上,我们的提出的方法有着一致的性能,在指数级别地减少计算量的同时,可以取得逼近于完整Softmax的性能。从表图1中可以看到,在取得相同性能的情况下,哈希森林的时间开销比最优选择器或者完整的Softmax要小一个数量级;在相同的时间消耗下,哈希森林的性能远超其它的一些算法。并且可以从图中看到,动态的哈希森林可以进一步地提升算法的性能。
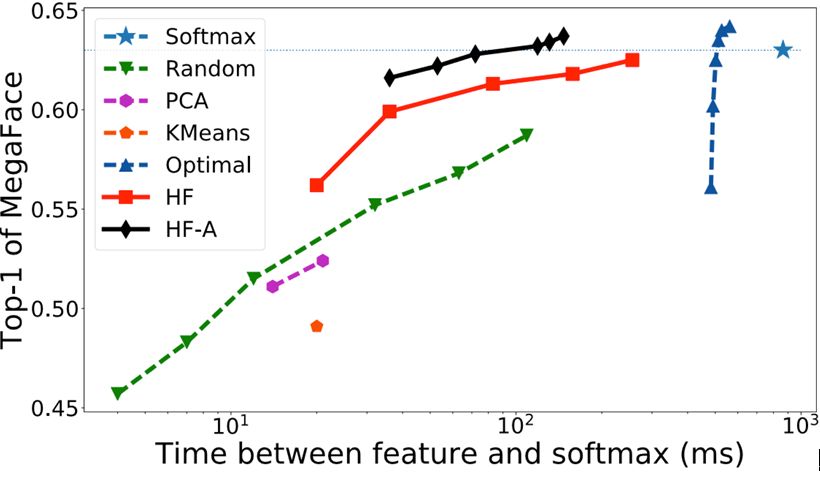
表图1. 选择性Softmax和其它方法的比较
除了在小模型上的比较实验,我们还将Ms1MCeleb和Megaface Challenge 2两个数据集合并在一起,得到一个75万分类的大数据集,用Resnet-101在这个数据集上进行了实验。在这个大实验中,我们在几乎不损耗性能的情况下,可以将每轮的训练迭代时间从3.5s缩短为1.5s,起到了60%的加速效果。并且由于我们将巨大的权重参数放到了CPU的内存中,我们几乎移除了权重矩阵所占用的所有显存。从整体网络的显存消耗上看,我们可以将显存开销减小24%。
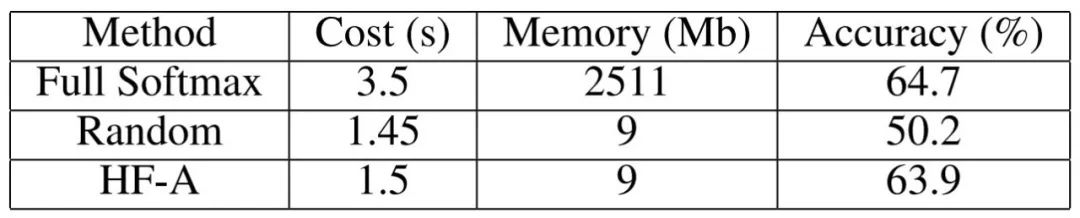
表图2. 在Resnet101上进行
75万人脸分类的训练
除了得到更好的性能,我们也详细分析了哈希森林中不同决定因子对最后结果的影响。由下图可以得到几个观察:1)不管用何种选择器,随着采样类别数目的增加,模型的性能都会随之增加。2)基于哈希森林的选择器在采样类别数目很小时,就可以逼近最优选择器的性能。3)对于哈希森林中树的数目不是特别敏感,在超过50颗树时性能就趋于稳定。4)当哈希森林的更新周期在1个epoch内时,对性能的影响不显著,如果更新周期超过了一个1 epoch,可能因为构建哈希森林的权重矩阵信息太过久远而造成整体性能的下降。
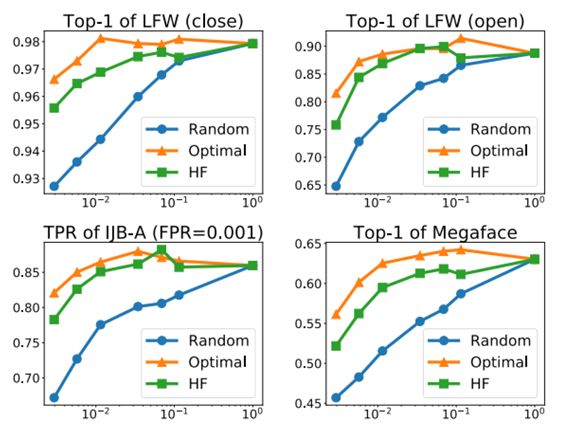
表图2. 采样类别数对性能的影响
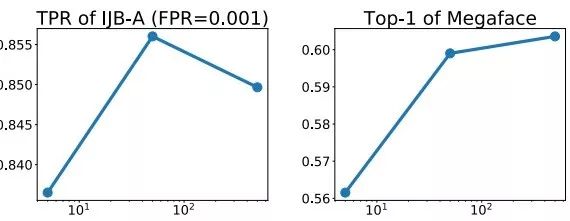
表图3. 树的数目对性能的影响
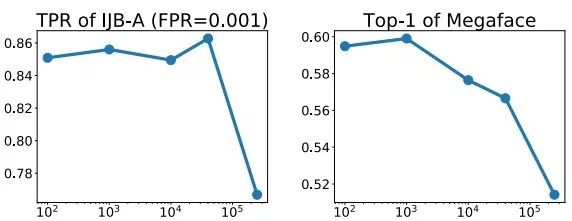
图表4. 更新周期对性能的影响
思考与最后的话
回顾本文的算法,我们针对大规模分类时Softmax带来的问题,提出了基于动态类别层级选择的算法,高效且准确地找到了“活跃类别”,并且我们进一步提出了动态分配的方案来进一步充分利用计算资源。在不同测试集上的实验结果,充分验证了本文方法的有效性。另外,除了本文中提出的哈希森林选择器,该动态选择性Softmax的计算框架还可以灵活引入不同的采样算法,在实际的使用情况中,可以根据速度和精度的不同需求来选择不同的采样算法。在未来,我们希望进一步探寻该方法的边界,当数据规模再大一个甚至几个量级时,会不可避免地引入更多的噪声。当这些噪声达到无法人工清理的规模时,可能会对构建的动态的层级结构造成很多干扰,使得选择器无法准确区分“活跃类别”和“噪声类别”等信息,如何在这种情况下改进我们的选择性Softmax是一个值得继续探究的问题。
相关文献:
【1】“Accelerated Training for Massive Classification via Dynamic Class Selection”, Xingcheng Zhang, Lei Yang, Junjie Yan and Dahua Lin, AAAI 2018.
【2】“Deep learning face representation from predicting 10,000 classes”, Sun, Yi, Xiaogang Wang, and Xiaoou Tang, CVPR 2014.
文章链接:
请点击左下角“阅读原文”查看
Github代码:
https://github.com/yl-1993/hfsoftmax




