迈向无所不聊的对话代理

文 / Google Research 及 Google Brain 团队高级研究工程师 Daniel Adiwardana 和高级研究员 Thang Luong
现代 对话代理 (Conversational Agent, 又称 chatbots 聊天机器人) 非常专业,只要用户的使用行为与预期相差不多,这类机器人的表现就会很好。
为了更好地处理各种各样的对话主题,开放域对话 (Open-Domain Dialog) 的研究团队探索出一种补充方法:尝试开发出一种不专门针对聊天、但仍然可以与用户聊任何内容的聊天机器人。这类对话代理不仅是一个吸引人的研究课题,而且还可衍生出很多有趣应用,如:可进一步提升人机互动,改进外语学习,制作有关联的交互式电影和视频游戏角色的应用。
但是,现有的开放域聊天机器人存在一个严重缺陷:它们回复的内容常常不具有实际意义。它们时常回复的话语前后不搭,或者明显缺乏常识与关于世界的基本认知。此外,这类聊天机器人经常会给出不符合当前特定语境的答复。例如,用“我不知道”这个没有针对性的答案来回复很多问题。据统计,聊天机器人比人类更频繁地给出类似的万金油回答。
我们在《迈向拟人化的开放域聊天机器人》(Towards a Human-like Open-Domain Chatbot) 一文中介绍了 Meena,这是一个包含 26 亿个参数的端到端训练的神经对话模型。我们证明,与现有的最先进 (State-Of-The-Art) 聊天机器人相比,Meena 可以进行更合理和更具体的对话。我们针对开放域聊天机器人提出一项新的人工评估指标,即合理度和具体度平均值 (Sensibleness and Specificity Average, SSA),可捕获人类对话中基本但重要的属性。值得注意的是,我们提出了一项适用于任何神经对话模型,而且与 SSA 高度相关的自动指标 “困惑度 (Perplexity)”。
迈向拟人化的开放域聊天机器人
https://arxiv.org/abs/2001.0997-
神经对话模型
https://arxiv.org/abs/1506.0586
Meena(左)与用户(右)的聊天对话
Meena
Meena 是一种端到端的神经对话模型,可以根据特定语境学习并做出明智回答。训练的目标是最大程度地降低困惑度,即预测下一个 token (在本例中是指对话中的下一个词) 的不确定性。Meena 的核心是 Evolved Transformer seq2seq 架构,这是一种为降低困惑度,在改进神经架构搜索时发现的 Transformer 架构。
Evolved Transformer seq2seq
https://ai.googleblog.com/2019/06/applying-automl-to-transformer.html
具体来说,Meena 拥有 1 个 Evolved Transformer 编码器块 (Encoder) 和 13 个 Evolved Transformer 解码器块 (Decoder),如下图所示。编码器负责处理对话上下文,以帮助 Meena 理解对话中已经提及过的内容。随后,解码器使用理解的信息来制定实际回答。通过调整超参数,我们发现功能更强大的解码器是提高对话质量的关键。
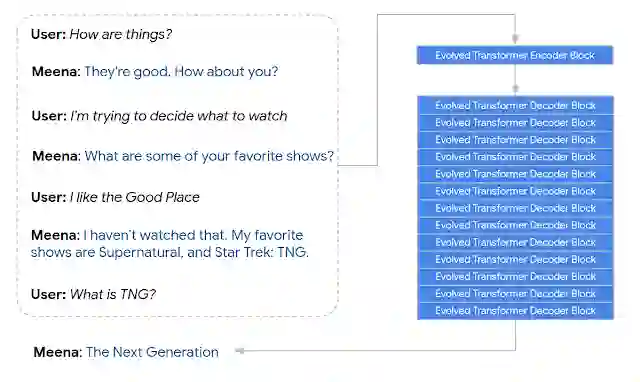
Meena 对含 7 轮上下文的对话进行编码并生成 “新一代 (The Next Generation)”回答的示例
我们把用于训练的对话组织成树线索,其中线索内的每次回答均视作一个对话回合(一轮)。我们提取了每个对话训练示例(包含七轮上下文的对话),并将其作为树线索的一条路径。我们认为七轮的对话可实现良好的平衡,一边保证用于训练对话模型的上下文长度足够,一边保证不超过内存限制,因为更长的上下文会占用更多内存。
Meena 模型包含 26 亿个参数,并经过了 341 GB 文本的训练,这些文本都是从公共领域的社交媒体上的对话中过滤得到的。相较于现有最先进的生成模型 OpenAI GPT-2,Meena 拥有 1.7 倍的模型容量,并且经过了 8.5 倍数据量的训练。
OpenAI GPT-2
https://openai.com/blog/better-language-models/
人工评估指标:合理度和具体度平均值 (SSA)
目前,针对聊天机器人质量的人工评估指标往往很复杂,而且评估者之间没有统一的标准。因此,这促使我们设计出一种新的人工评估指标,即合理度和具体度平均值 (SSA),可捕获自然对话中的基本但重要的属性。
为了计算 SSA,我们通过众包形式与正在测试的聊天机器人进行了自由对话(包括 Meena 和其他著名的开放域聊天机器人,如 Mitsuku、Cleverbot、微软小冰和 DialoGPT 等)。为确保评估之间的一致性,每个对话都以相同的问候语 “嗨!”开始。对于每次对话,众包工作人员都需要评估两个问题:“回答是否合理?”和“回答是否具体?”。
DialoGPT
https://arxiv.org/abs/1911.00536
评估者需要用常识来判断给出的回答在上下文语境中是否完全合理。如果出现任何问题,比如语义混乱、不合逻辑、脱离上下文或有事实性错误,则应将其回答评为“不合理”。如果回答合理,则需要评估该回答是否符合给定的上下文。例如,如果 A 说“我喜欢网球”而 B 回答“很好”,那么该回答应被标记为“不具体”,因为这种回答在许多不同的上下文中都可使用。但是,如果 B 回答“我也是,我超爱罗杰·费德勒!”,则该回答可被标记为“具体”,因为它与正在讨论的内容密切相关。
针对每个聊天机器人,我们通过约 100 个场对话收集了 1600 至 2400 轮独立对话。每个模型的回答都由众包工作人员标记,评估回答是否合理和具体。
聊天机器人的合理度 (Sensibleness) 代表标记为“合理 (Sensible)”回答的占比,而具体度 (Specificity) 则代表标记为“具体 (Specific)”回答的占比,二者的平均值就是 SSA 分数。以下结果表明,就 SSA 评分而言,Meena 的表现明显优于当下最先进的聊天机器人,并且正在缩小与人类表现的差距。
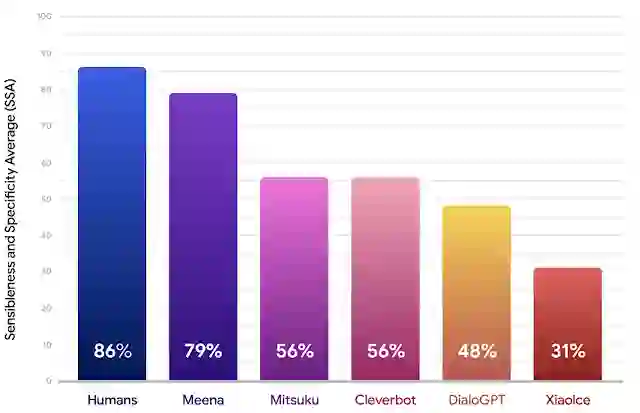
与人类、Mitsuku、Cleverbot、微软小冰和 DialoGPT 相比,Meena 的合理度和具体度平均值 (SSA)
自动指标:困惑度
长期以来,研究人员一直在寻找一种自动评估指标,能反映更为准确的人工评估。这将有助于加速对话模型的开发,但是迄今为止,找到这种自动指标的过程总是挑战重重 (https://www.aclweb.org/anthology/D16-1230/)。
出乎意料的是,我们在工作中发现困惑度,一种在任何神经 seq2seq 模型中均可方便使用的自动指标,它与人工评估指标(如 SSA 值)具有很强的相关性。困惑度用于衡量语言模型的不确定性。困惑度越低,模型就越有可能生成下一个 token(字符、子单词或单词)。从概念上讲,困惑度表示在生成下一个 token 时,模型尝试从中进行选择的数量。
seq2seq
https://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf
在开发过程中,我们对具有不同超参数和架构的八个不同模型版本进行了基准测试,例如 layers 的数量、attention heads、总训练步骤、是使用 Evolved Transformer 还是常规 Transformer,以及是否使用硬标签或 知识蒸馏 (Distillation) 进行训练。如下图所示,困惑度越低,模型的 SSA 评分越高,相关性也很强 (R2 = 0.93)。
知识蒸馏
https://arxiv.org/abs/1503.02531
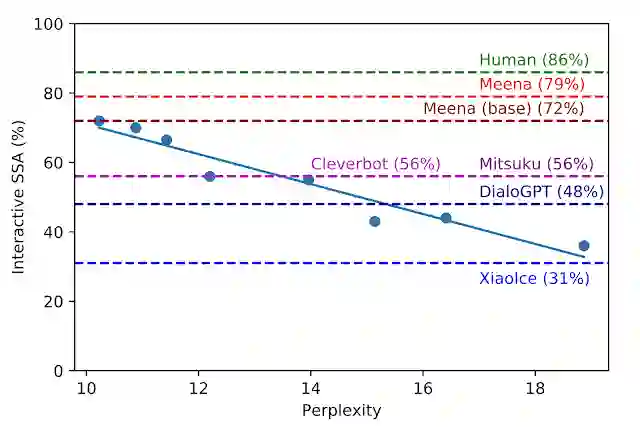
SSA 与困惑度:每个蓝点代表 Meena 模型的不同版本。图上绘制的回归线表明 SSA 和困惑度之间存在很强的相关性。虚线分别对应人类、其他机器人、Meena(基础)、端到端训练的模型,以及具有过滤机制和优化解码功能的最终完整的 Meena 的 SSA 表现
我们最好的端到端训练 Meena 模型称为 Meena(基础),其困惑度为 10.2(值越小越好),转换为 SSA 评分相当于 72%。相较于其他聊天机器人的 SSA 评分,我们的 SSA 评分为 72%,与普通人类 86% 的 SSA 评分相差不远。完整版 Meena 具有过滤机制和优化解码功能,可将 SSA 评分进一步提高至 79%。
未来研究与挑战
如先前所提倡的,我们将继续通过改进算法、架构、数据和计算来降低神经对话模型的困惑度。
尽管本项研究中只专注于合理度和具体度,但我们在后续工作中也会考虑其他属性,例如个性和事实性。此外,解决模型中的安全性和偏差问题也是我们的研究重点,而由于存在诸多与此相关的挑战,我们目前尚未公布外部研究演示。但是,我们正在评估与外部化模型 checkpoint 相关的风险和优势,并且可能选择在未来几个月中实施这一方案,以帮助推进该领域的研究。
个性
https://arxiv.org/abs/1801.0724事实性
https://arxiv.org/abs/1811.01241
致谢
感谢以下成员对此项目做出的巨大贡献:David So、Jamie Hall、Noah Fiedel、Romal Thoppilan、Zi Yang、Apoorv Kulshreshtha、Gaurav Nemade、Yifeng Lu。同时,也要感谢 Quoc Le、Samy Bengio 和 Christine Robson 给予的领导支持。感谢以下人士对本文草稿提出反馈意见:Anna Goldie、Abigail See、YizheZhang、Lauren Kunze、Steve Worswick、Jianfeng Gao、Daphne Ippolito、Scott Roy、Ilya Sutskever、Tatsu Hashimoto、Dan Jurafsky、Dilek Hakkani-tur、Noam Shazeer、Gabriel Bender、Prajit Ramachandran、Rami Al-Rfou、Michael Fink、Mingxing Tan、Maarten Bosma 和 Adams Yu。同时也要感谢众多帮助收集与各种聊天机器人的对话的志愿者们。最后,感谢 Noam Shazeer、Rami Al-Rfou、Khoa Vo、Trieu H.Trinh、Ni Yan、Kyu Jin Hwang 和 Google Brain 团队对本项目的帮助。
推荐阅读
抛开模型,探究文本自动摘要的本质——ACL2019 论文佳作研读系列
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。






