【开源】北大团队大规模稀疏数据机器学习库xLearn,c++ trending 已超TensorFlow
新智元AI World 2017世界人工智能大会开场视频
中国人工智能资讯智库社交主平台新智元主办的 AI WORLD 2017 世界人工智能大会11月8日在北京国家会议中心举行,大会以“AI 新万象,中国智能+”为主题,上百位AI领袖作了覆盖技术、学术和产业最前沿的报告和讨论,2000多名业内人士参会。新智元创始人兼CEO杨静在会上发布全球首个AI专家互动资讯平台“新智元V享圈”。
全程回顾新智元AI World 2017世界人工智能大会盛况:
新华网图文回顾
http://www.xinhuanet.com/money/jrzb20171108/index.htm
爱奇艺
上午:http://www.iqiyi.com/v_19rrdp002w.html
下午:http://www.iqiyi.com/v_19rrdozo4c.html
阿里云云栖社区
https://yq.aliyun.com/webinar/play/316?spm=5176.8067841.wnnow.14.ZrBcrm
新智元报道
编辑:弗格森
【新智元导读】 机器学习博士马超近日在微博上介绍他和导师肖臻教授一起开发的一款专门针对大规模稀疏数据的机器学习库xLearn并开源。并称, vision 是将 xLearn 打造成和 xgboost,MXNet一样的工业事实标准。

该项目由肖臻教授和马超博士合作完成。
肖臻教授 美国康奈大学博士 之前任美国AT&T 和 IBM 科学家。研究方向分布式系统和机器学习。在国际顶级刊物发表论文60余篇,论文引用超过4000次。
马超,北大云计算课题组博士生,研究方向分布式系统与大规模机器学习。同时担任亚马逊AWS 应用科学家实习生,负责MXNet 分布式性能优化。
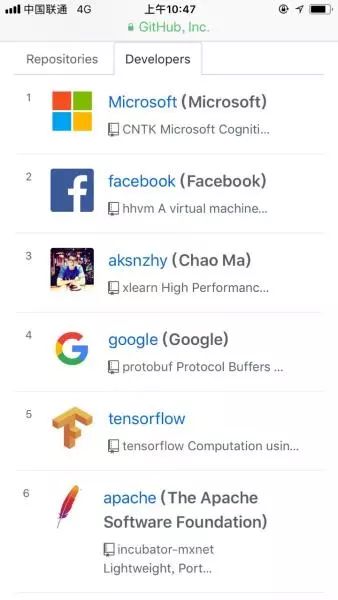
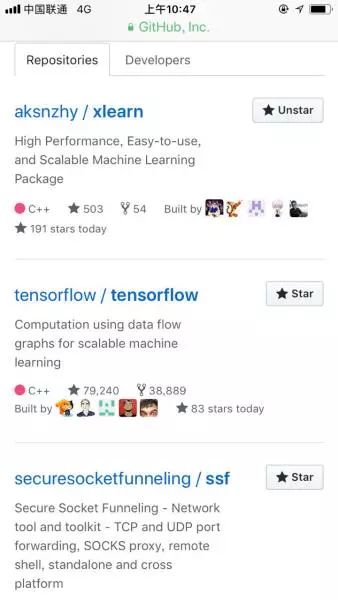
目前在c++ trending 上,xLearning已经超过 tensorflow
马超在微博上介绍:
在机器学习里,除了深度学习和树模型 (GBDT, RF) 之外,如何高效地处理高维稀疏数据也是非常重要的课题,Sparse LR, FM, FFM 这些算法被广泛运用在实际生产和kaggle比赛中。现有的开源软件例如 liblinear, libfm, libffm 都只能针对特定的算法,并且可扩展性、灵活性、易用性都不够友好。基于此,我在博士期间开发了 xLearn,一款专门针对大规模稀疏数据的机器学习库,曾在之前 NIPS 上做过展示。经过打磨,现开源(https://github.com/aksnzhy/xlearn) 。我们的 vision 是将 xLearn 打造成和 xgboost,MXNet一样的工业事实标准。
相比于已有的软件,xLearn的优势主要有(1)通用性好,我们用统一的架构将主流的算法(lr, fm, ffm 等)全部囊括,用户不用再切换于不同软件之间。(2)性能好。xLearn由高性能c++开发,提供 cache-aware 和 lock-free learning,并且经过手工 SSE/AVX 指令优化。 在单机MacBook Pro上测试 xLearn 可以比 libfm 快13倍,比 libffm 和 liblinear 快5倍(基于Criteo CTR数据 bechmark)。(3)易用性和灵活性,xLearn 提供简单的 python 接口,并且集合了机器学习比赛中许多有用的功能,例如:cross-validation,early-stopping 等。除此之外,用户可以灵活选择优化算法(例如,SGD,AdaGrad, FTRL 等)(4) 可扩展性好。xLearn 提供 out-of-core 计算,利用外存计算可以在单机处理 1TB 数据。除此之外,xLearn 也提供分布式训练功能。这里我希望更多的朋友加入这个开源项目!

马超的微博截图
性能

xLearn是由高性能的C ++代码精心设计和优化而开发的。系统旨在最大限度地利用CPU和内存,提供缓存感知计算,并支持无锁学习。通过结合这些见解,与相似系统相比,xLearn速度提高了5倍 - 13倍。
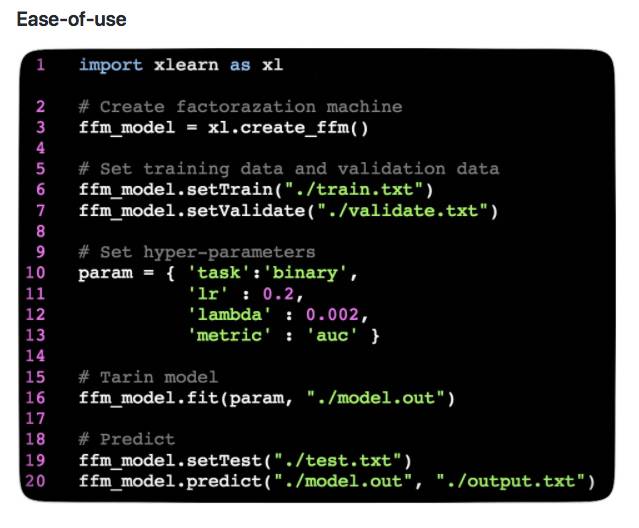
xLearn不依赖任何第三方库,因此用户只需克隆代码并使用cmake编译即可。此外,xLearn支持用户非常简单的Python API。除此之外,xLearn支持许多有用的功能,已经在机器学习竞赛中广泛使用,如交叉验证,提前停止等。
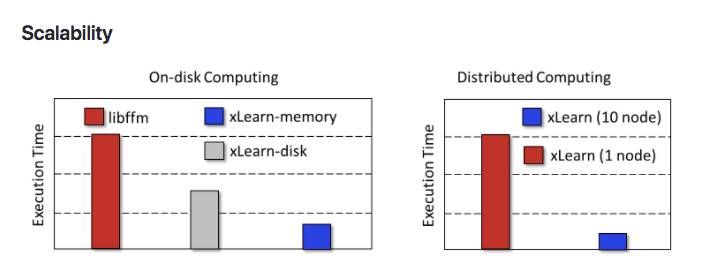
xLearn可以用来解决大规模的机器学习问题。首先,xLearn支持非核心训练,只需利用单台机器的磁盘即可处理非常大的数据(TB)。此外,xLearn还可以支持分布式训练,这种训练在许多机器上都可以扩展到数十亿个示例。