PySpark源码解析,教你用Python调用高效Scala接口,搞定大规模数据分析
机器之心专栏
作者:汇量科技-陈绪
相较于Scala语言而言,Python具有其独有的优势及广泛应用性,因此Spark也推出了PySpark,在框架上提供了利用Python语言的接口,为数据科学家使用该框架提供了便利。

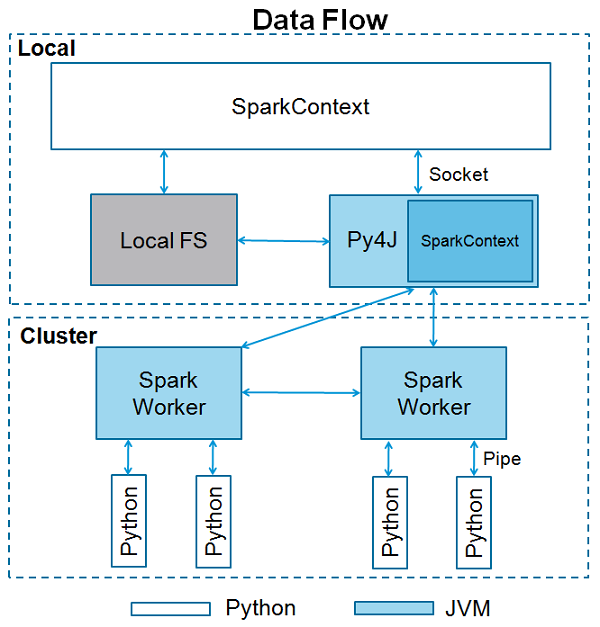
PySpark 的多进程架构;
Python 端调用 Java、Scala 接口;
Python Driver 端 RDD、SQL 接口;
Executor 端进程间通信和序列化;
Pandas UDF;
总结。
PySpark项目地址:https://github.com/apache/spark/tree/master/python
def _ensure_initialized(cls, instance=None, gateway=None, conf=None):
"""
Checks whether a SparkContext is initialized or not.
Throws error if a SparkContext is already running.
"""
with SparkContext._lock:
if not SparkContext._gateway:
SparkContext._gateway = gateway or launch_gateway(conf)
SparkContext._jvm = SparkContext._gateway.jvmSPARK_HOME = _find_spark_home()
# Launch the Py4j gateway using Spark's run command so that we pick up the
# proper classpath and settings from spark-env.sh
on_windows = platform.system() == "Windows"
script = "./bin/spark-submit.cmd" if on_windows else "./bin/spark-submit"
command = [os.path.join(SPARK_HOME, script)]gateway = JavaGateway(
gateway_parameters=GatewayParameters(port=gateway_port, auth_token=gateway_secret,
auto_convert=True))
# Import the classes used by PySpark
java_import(gateway.jvm, "org.apache.spark.SparkConf")
java_import(gateway.jvm, "org.apache.spark.api.java.*")
java_import(gateway.jvm, "org.apache.spark.api.python.*")
java_import(gateway.jvm, "org.apache.spark.ml.python.*")
java_import(gateway.jvm, "org.apache.spark.mllib.api.python.*")
# TODO(davies): move into sql
java_import(gateway.jvm, "org.apache.spark.sql.*")
java_import(gateway.jvm, "org.apache.spark.sql.api.python.*")
java_import(gateway.jvm, "org.apache.spark.sql.hive.*")
java_import(gateway.jvm, "scala.Tuple2")gateway = JavaGateway()
jvm = gateway.jvm
l = jvm.java.util.ArrayList()def _initialize_context(self, jconf):
"""
Initialize SparkContext in function to allow subclass specific initialization
"""
return self._jvm.JavaSparkContext(jconf)
# Create the Java SparkContext through Py4J
self._jsc = jsc or self._initialize_context(self._conf._jconf)def newAPIHadoopFile(self, path, inputFormatClass, keyClass, valueClass, keyConverter=None,
valueConverter=None, conf=None, batchSize=0):
jconf = self._dictToJavaMap(conf)
jrdd = self._jvm.PythonRDD.newAPIHadoopFile(self._jsc, path, inputFormatClass, keyClass,
valueClass, keyConverter, valueConverter,
jconf, batchSize)
return RDD(jrdd, self)object PythonEvals extends Strategy {
override def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case ArrowEvalPython(udfs, output, child, evalType) =>
ArrowEvalPythonExec(udfs, output, planLater(child), evalType) :: Nil
case BatchEvalPython(udfs, output, child) =>
BatchEvalPythonExec(udfs, output, planLater(child)) :: Nil
case _ =>
Nil
}
}def compute(
inputIterator: Iterator[IN],
partitionIndex: Int,
context: TaskContext): Iterator[OUT] = {
// ......
val worker: Socket = env.createPythonWorker(pythonExec, envVars.asScala.toMap)
// Start a thread to feed the process input from our parent's iterator
val writerThread = newWriterThread(env, worker, inputIterator, partitionIndex, context)
writerThread.start()
val stream = new DataInputStream(new BufferedInputStream(worker.getInputStream, bufferSize))
val stdoutIterator = newReaderIterator(
stream, writerThread, startTime, env, worker, releasedOrClosed, context)
new InterruptibleIterator(context, stdoutIterator)val arrowWriter = ArrowWriter.create(root)
val writer = new ArrowStreamWriter(root, null, dataOut)
writer.start()
while (inputIterator.hasNext) {
val nextBatch = inputIterator.next()
while (nextBatch.hasNext) {
arrowWriter.write(nextBatch.next())
}
arrowWriter.finish()
writer.writeBatch()
arrowWriter.reset()protected ArrowBlock writeRecordBatch(ArrowRecordBatch batch) throws IOException {
ArrowBlock block = MessageSerializer.serialize(out, batch, option);
LOGGER.debug("RecordBatch at {}, metadata: {}, body: {}",
block.getOffset(), block.getMetadataLength(), block.getBodyLength());
return block;
}if __name__ == '__main__':
# Read information about how to connect back to the JVM from the environment.
java_port = int(os.environ["PYTHON_WORKER_FACTORY_PORT"])
auth_secret = os.environ["PYTHON_WORKER_FACTORY_SECRET"]
(sock_file, _) = local_connect_and_auth(java_port, auth_secret)
main(sock_file, sock_file)eval_type = read_int(infile)
if eval_type == PythonEvalType.NON_UDF:
func, profiler, deserializer, serializer = read_command(pickleSer, infile)
else:
func, profiler, deserializer, serializer = read_udfs(pickleSer, infile, eval_type)def dump_stream(self, iterator, stream):
import pyarrow as pa
writer = None
try:
for batch in iterator:
if writer is None:
writer = pa.RecordBatchStreamWriter(stream, batch.schema)
writer.write_batch(batch)
finally:
if writer is not None:
writer.close()
def load_stream(self, stream):
import pyarrow as pa
reader = pa.ipc.open_stream(stream)
for batch in reader:
yield batchdef arrow_to_pandas(self, arrow_column):
from pyspark.sql.types import _check_series_localize_timestamps
# If the given column is a date type column, creates a series of datetime.date directly
# instead of creating datetime64[ns] as intermediate data to avoid overflow caused by
# datetime64[ns] type handling.
s = arrow_column.to_pandas(date_as_object=True)
s = _check_series_localize_timestamps(s, self._timezone)
return s
def load_stream(self, stream):
"""
Deserialize ArrowRecordBatches to an Arrow table and return as a list of pandas.Series.
"""
batches = super(ArrowStreamPandasSerializer, self).load_stream(stream)
import pyarrow as pa
for batch in batches:
yield [self.arrow_to_pandas(c) for c in pa.Table.from_batches([batch]).itercolumns()]def multiply_func(a, b):
return a * b
multiply = pandas_udf(multiply_func, returnType=LongType())
df.select(multiply(col("x"), col("x"))).show()进程间通信消耗额外的 CPU 资源;
编程接口仍然需要理解 Spark 的分布式计算原理;
Pandas UDF 对返回值有一定的限制,返回多列数据不太方便。
登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文