DIVERSITY IS ALL YOU NEED: 充满睿智的论述。
两篇无监督强化学习,学习动作组合的skill技能。
互信息从state action 到 state skill;action到skill就是提升一级抽象
cpc 视频预测也应该从之前的action到skill的。
paper: 1
Variational Option Discovery Algorithms :: real hierarchical
We show that Variational Intrinsic Control (VIC) (Gregor et al. [2016]) and
the recently-proposed Diversity is All You Need (DIAYN) (Eysenbach et al. [2018]) are specific
instances of this template which decode from states instead of complete trajectories.
abs:
two algorithmic contributions. First: we highlight a tight connection between variational option discovery methods and variational autoencoders
In VALOR, the policy encodes contexts from a noise distribution into trajectories, and the decoder recovers the contexts from the complete trajectories. Second: we propose a curriculum learning approach
1
Humans are innately driven to experiment with new ways of interacting with their environments.
This can accelerate the process of discovering skills for downstream tasks and can also be viewed as a primary objective in its own right. This drive serves as an inspiration for reward-free option discovery
In our analogy, a policy acts as an encoder, translating contexts from a noise distribution into trajectories; a decoder attempts to recover the contexts from the trajectories, and rewards the policies for making contexts easy to distinguish. Contexts are random vectors which have no intrinsic meaning prior to training, but they become associated with trajectories as a result of training; each context vector thus corresponds to a distinct option. Therefore this approach learns a set of options which are as diverse as possible, in the sense of being as easy to distinguish from each other as possible. We show that Variational Intrinsic Control (VIC) (Gregor et al. [2016]) and the recently-proposed Diversity is All You Need (DIAYN) (Eysenbach et al. [2018]) are specific instances of this template which decode from states instead of complete trajectories.
We make two main algorithmic contributions:
1 .The idea is to encourage learning dynamical modes instead of goal-attaining modes, e.g. ‘move in a circle’ instead of ‘go to X’.
2. We propose a curriculum learning approach where the number of contexts seen by the agent increases whenever the agent’s performance is strong enough (as measured by the decoder) on the current set of contexts.
show that, to the extent that our metrics can measure, all three of them perform similarly, except that VALOR can attain qualitatively different behavior because of its trajectory-centric approach, and DIAYN learns more quickly because of its denser reward signal. We show that our curriculum trick stabilizes and speeds up learning for all three methods, and can allow a single agent to learn up to hundreds of modes. Beyond our core comparison, we also explore applications of variational option discovery in two interesting spotlight environments: a simulated robot hand and a simulated humanoid. Variational option discovery finds naturalistic finger-flexing behaviors in the hand environment, but performs poorly on the humanoid, in the sense that it does not discover natural crawling or walking gaits. We consider this evidence that pure information-theoretic objectives can do a poor job of capturing human priors on useful behavior in complex environments
using a (particularly good) pretrained VALOR policy as the lower level of a hierarchy. In this experiment, we find that the VALOR policy is more useful than a random network as a lower level, and equivalently as useful as learning a lower level from scratch in the environment.
2
option Discovery
Several approaches for option discovery are primarily information-theoretic: Gregor et al. [2016], Eysenbach et al. [2018], and Florensa et al. [2017] train policies to maximize mutual information between options and states or quantities derived from states; by contrast, we maximize information between options and whole trajectories
Universal Policies
Universal Policies: Variational option discovery algorithms learn universal policies (goal- or instruction- conditioned policies)
By contrast, variational option discovery is unsupervised and finds its own instruction space.
Intrinsic Motivation:
However, none of these approaches were combined with learning universal policies, and so suffer from a problem of knowledge fade
Variational Autoencoders
Novelty Search:
3 Variational Option Discovery Algorithms
其他方法的互信息最大? 转到 DIVERSITY IS ALL YOU NEED:
实现细节参考论文即可。
paper 2 :
--------------------------
DIVERSITY IS ALL YOU NEED:
LEARNING SKILLS WITHOUT A REWARD FUNCTION
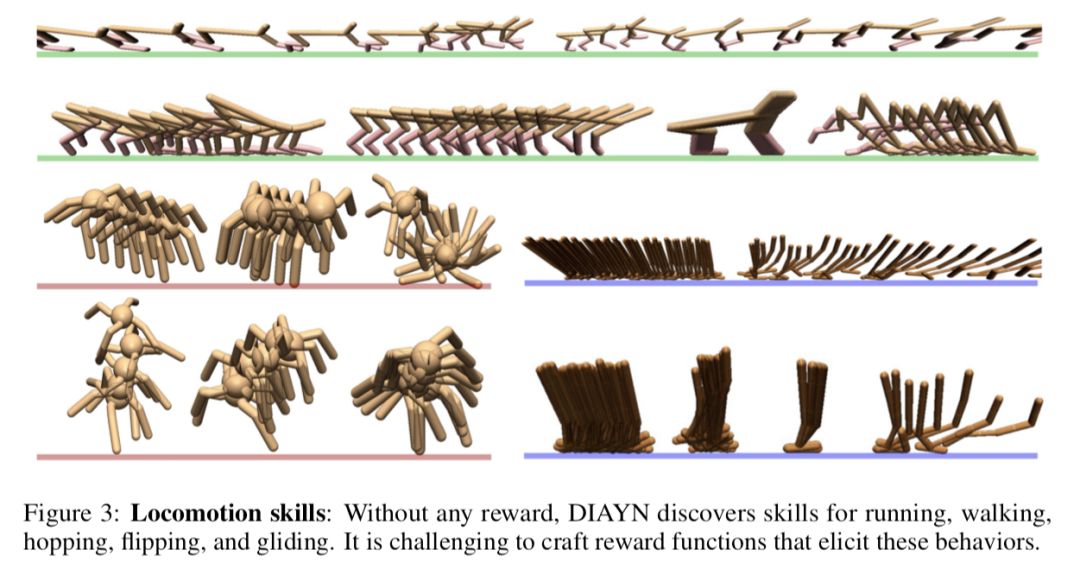
DIVERSITY IS ALL YOU NEED: 充满睿智的论述。
互信息从state action 到 state skill;action到skill就是提升一级抽象
cpc 视频预测也应该从之前的action到skill的。
abs:
propose “Diversity is All You Need”(DIAYN), a method for learning useful skills without a reward function. Our proposed method learns skills by maximizing an information theoretic objective using a maximum entropy policy. On a variety of simulated robotic tasks, we show that this simple objective results in the unsupervised emergence of diverse skills, such as walking and jumping. In a number of reinforcement learning benchmark environments, our method is able to learn a skill that solves the benchmark task despite never receiving the true task reward. We show how pretrained skills can provide a good parameter initialization for downstream tasks, and can be composed hierarchically to solve complex, sparse reward tasks. Our results suggest that unsupervised discovery of skills can serve as an effective pretraining mechanism for overcoming challenges of exploration and data efficiency in reinforcement learning.
1
intelligent creatures can explore their environments and learn useful skills even without supervision, so that when they are later faced with specific goals, they can use those skills to satisfy the new goals quickly and efficiently.
Learning useful skills without supervision may help address challenges in exploration in these environments. For long horizon tasks, skills discovered without reward can serve as primitives for hierarchical RL, effectively shortening the episode length. In many practical settings, interacting with the environment is essentially free, but evaluating the reward requires human feedback (Christiano et al., 2017). Unsupervised learning of skills may reduce the amount of supervision necessary to learn a task. While we can take the human out of the loop by designing a reward function, it is challenging to design a reward function that elicits the desired behaviors from the agent
A skill is a latent-conditioned policy that alters that state of the environment in a consistent way.
learning objective that ensures that each skill individually is distinct and that the skills collectively explore large parts of the state space.
These skills are useful for a number of applications, including hierarchical reinforcement learning and imitation learning.
A key idea in our work is to use discriminability between skills as an objective. Further, skills that are distinguishable are not necessarily maximally diverse – a slight difference in states makes two skills distinguishable, but not necessarily diverse in a semantically meaningful way. To combat problem, we want to learn skills that not only are distinguishable, but also are as diverse as possible. By learning distinguishable skills that are as random as possible, we can “push” the skills away from each other, making each skill robust to perturbations and effectively exploring the environment. By maximizing this objective, we can learn skills that run forward, do backflips, skip backwards, and perform face flops (
five contributions. First, we propose a method for learning useful skills without any rewards. We formalize our discriminability goal as maximizing an information theoretic objective with a maximum entropy policy. Second, we show that this simple exploration objective results in the unsupervised emergence of diverse skills
Third, we propose a simple method for using learned skills for hierarchical RL and find this methods solves challenging tasks. Four, we demonstrate how skills discovered can be quickly adapted to solve a new task. Finally, we show how skills discovered can be used for imitation learning.
2
Previous work on hierarchical RL has learned skills to maximize a single, known, reward function by jointly learning a set of skills and a meta-controller
One problem with joint training (also noted by Shazeer et al. (2017)) is that the meta-policy does not select “bad” options, so these options do not receive any reward signal to improve.
Our work prevents this degeneracy by using a random meta-policy during unsupervised skill-learning, such that neither the skills nor the meta-policy are aiming to solve any single task. A second importance difference is that our approach learns skills with no reward. Eschewing a reward function not only avoids the difficult problem of reward design, but also allows our method to learn task-agnostic.
and Jung et al. (2011) use the mutual information between states and actions as a notion of empowerment for an intrinsically motivated agent. Our method maximizes the mutual information between states and skills, which can be interpreted as maximizing the empowerment of a hierarchical agent whose action space is the set of skills
and Gregor et al. (2016) showed that a discriminability objective is equivalent to maximizing the mutual information between the latent skill z and some aspect of the corresponding trajectory
Three important distinctions allow us to apply our method to tasks significantly more complex than the gridworlds in Gregor et al. (2016). First, we use maximum entropy policies to force our skills to be diverse. Our theoretical analysis shows that including entropy maximization in the RL objective results in the mixture of skills being maximum entropy in aggregate. Second, we fix the prior distribution over skills, rather than learning it. Doing so prevents our method from collapsing to sampling only a handful of skills. Third, while the discriminator in Gregor et al. (2016) only looks at the final state, our discriminator looks at every state, which provides additional reward signal. These three crucial differences help explain how our method learns useful skills in complex environments.
we aim to acquire complex skills with minimal supervision to improve efficiency (i.e., reduce the number of objective function queries) and as a stepping stone for imitation learning and hierarchical RL. We focus on deriving a general, information-theoretic objective that does not require manual design of distance metrics and can be applied to any RL task without additional engineering.
While these previous works use an intrinsic motivation objective to learn a single policy, we propose an objective for learning many, diverse policies.
3
the aim of the unsupervised stage is to learn skills that eventually will make it easier to maximize the task reward in the supervised stage. Conveniently, because skills are learned without a priori knowledge of the task, the learned skills can
be used for many different tasks.
3.1
3.1 HOW IT WORKS
Our method for unsupervised skill discovery, DIAYN (“Diversity is All You Need”), builds off of three ideas. First, for skills to be useful, we want the skill to dictate the states that the agent visits. Different skills should visit different states, and hence be distinguishable. Second, we want to use states, not actions, to distinguish skills, because actions that do not affect the environment are not visible to an outside observer. For example, an outside observer cannot tell how much force a robotic arm applies when grasping a cup if the cup does not move. Finally, we encourage exploration and incentivize the skills to be as diverse as possible by learning skills that act as randomly as possible. Skills with high entropy that remain discriminable must explore a part of the state space far away from other skills, lest the randomness in its actions lead it to states where it cannot be distinguished.
公式看论文吧。
4 EXPERIMENTS
4.1 ANALYSIS OF LEARNED SKILLS
Question 1. What skills does DIAYN learn?
Question 2. How does the distribution of skills change during training?
Question 3. Does discriminating on single states restrict DIAYN to learn skills that visit disjoint sets of states?
Our discriminator operates at the level of states, not trajectories. ref Variational Option Discovery Algorithms
Question 4. How does DIAYN differ from Variational Intrinsic Control (VIC)
In contrast, DIAYN fixes the distribution over skills, which allows us to discover more diverse skills.
4.2 HARNESSING LEARNED SKILLS
Three less obvious applications are adapting skills to maximize a reward, hierarchical RL, and imitation learning.
4.2.1 ACCELERATING LEARNING WITH POLICY INITIALIZATION
we propose that DIAYN can serve as unsupervised pre-training for more sample-efficient finetuning of task-specific policies.
Question 5. Can we use learned skills to directly maximize the task reward?
4.2.2 USING SKILLS FOR HIERARCHICAL RL
In theory, hierarchical RL should decompose a complex task into motion primitives, which may be reused for multiple tasks. In practice, algorithms for hierarchical RL can encounter many problems: (1) each motion primitive reduces to a single action (Bacon et al., 2017), (2) the hierarchical policy only samples a single motion primitive (Gregor et al., 2016), or (3) all motion primitives attempt to do the entire task. In contrast, DIAYN discovers diverse, task-agnostic skills, which hold the promise of acting as a building block for hierarchical RL.
Question 6. Are skills discovered by DIAYN useful for hierarchical RL?
To use the discovered skills for hierarchical RL, we learn a meta-controller whose actions are to choose which skill to execute for the next k steps (100 for ant navigation, 10 for cheetah hurdle). The meta-controller has the same observation space as the skills.
VIME attempts to learn a single policy that visits many states.
Figure 7: DIAYN for Hierarchical RL: By learning a meta-controller to compose skills learned by DIAYN, cheetah quickly learns to jump over hurdles and ant solves a sparse-reward navigation task.
Question 7. How can DIAYN leverage prior knowledge about what skills will be useful?
4.2.3 IMITATING AN EXPERT
Question 8. Can we use learned skills to imitate an expert?
5 CONCLUSION
In this paper, we present DIAYN, a method for learning skills without reward functions. We show that DIAYN learns diverse skills for complex tasks, often solving benchmark tasks with one of the learned skills without actually receiving any task reward. We further proposed methods for using the learned skills (1) to quickly adapt to a new task, (2) to solve complex tasks via hierarchical RL, and (3) to imitate an expert. As a rule of thumb, DIAYN may make learning a task easier by replacing the task’s complex action space with a set of useful skills. DIAYN could be combined with methods for augmenting the observation space and reward function. Using the common language of information theory, a joint objective can likely be derived. DIAYN may also more efficiently learn from human preferences by having humans select among learned skills. Finally, the skills produced by DIAYN might be used by game designers to allow players to control complex robots and by artists to animate characters.


