Sorry,5G时代下多模态理解做不到位注定要掉队

作者|梁清华
编辑|Debra
随着 4G、5G 网络的发展,图像视频在社交网络中的比重越来越大,仅仅使用文本理解的方法无法满足微博物料召回和物料分发的需求。因此,结合文本、图像、音频、图像序列等多模态内容理解势在必行。本文是多模态内容理解专题的第三篇,在前两篇文章 《语义鸿沟、异构鸿沟、数据缺失,多模态技术如何跨过这些坎? 》 和《视频剪辑师饭碗恐不保? AI 剪片又快又好!》中,AI 前线分别介绍了快手和优酷在多模态内容理解方面的技术和应用实践,本文将详解多模态内容理解在微博场景中的实践和应用,希望读者可以对这项技术有更好的了解。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
微博(Weibo)是一种基于用户关系信息和关注机制来分享、传播以及获取简短实时信息的广播式的社交媒体、网络平台。2018 年 12 月,微博的月活跃用户数达到 4.62 亿,12 月平均日活跃用户数达到 2 亿。用户可以通过 PC、手机等多种终端接入,以文字、图片、视频等多媒体形式,实现信息的即时分享、传播互动。对于如此庞大的用户体量和广泛的兴趣标签,内容理解是社交媒体平台不可或缺的技术,在信息分发、计算广告、个性化推荐等领域都起着重要的作用。
微博又有其自有的特点。微博博文内容形式多样,微博一条博文包含文字、图像和视频等媒体。并且,微博文本较短,大部分不超过 140 字(其中大约 20% 的微博文本少于 10 个字),文本表述简洁,简称、不规范用语以及网络流行用语被广泛使用。随着 4G、5G 网络的发展,图像视频在社交网络中的比重越来越大,仅仅使用文本理解的方法无法满足微博物料召回和物料分发的需求。因此,结合文本、图像、音频、图像序列等多模态内容理解势在必行。
本文主要介绍多模态内容理解在微博场景中的实践和应用,本文接下来结构安排如下:首先简单介绍多模态信息处理,然后介绍微博场景中的典型应用和实践,最后是对多模态未来的展望。
在多媒体信息处理领域,所谓“模态”,用通俗的话说,就是“感官”,包括视觉、听觉、语义等,多模态即使用计算机将多种“感官”信息的融合。近年来,人工智能技术的蓬勃发展使得机器智能不断进步,多模态机器学习让机器像人类一样具有视觉、听觉和语义感知、理解和决策能力,正成为未来人工智能发展的必然方向,在自然人机交互、自动驾驶、VR/AR 等领域有巨大的应用价值。
从多模态的信息融合角度划分,可以分为松耦合的方法和紧耦合的方法。松耦合的方法,也就是单独处理各个模态,比如分别对图像和文本进行分析理解,包括人脸检测识别、OCR、实体识别等,然后将文本和图像的结果进行后期融合,得到最终的结果。这种方法好处在于各个模态单独处理,相互不存在强依赖关系,但这种方式对单模态的要求比较高,单模态做不好,多模态也不会做的很好。紧耦合则采用一种端到端的方式,将文本、图像、语音等模态同时输入到一个模型中进行训练,得到最终的结果,但这种方法难度较大。目前工业界应用主要以松耦合方法为主,紧耦合方法也逐渐从学术界向工业界迈进。
微博平台上图片微博和视频微博广泛流行,如何有效理解这些内容成为了新的挑战。只依赖微博文本或者图像某一种模态进行理解存在如下几点局限性和困难:
1.文本分析对歧义理解,隐喻处理存在较大困难。
文本存在歧义性,只依赖自然语言处理很难给出正确结果,比如图 1 中文本提到了“苹果”。如果仅仅依赖 NLP 技术很难识别出“苹果”在这里是指食物还是电子产品,但查看图像就能明确指的是苹果手机。
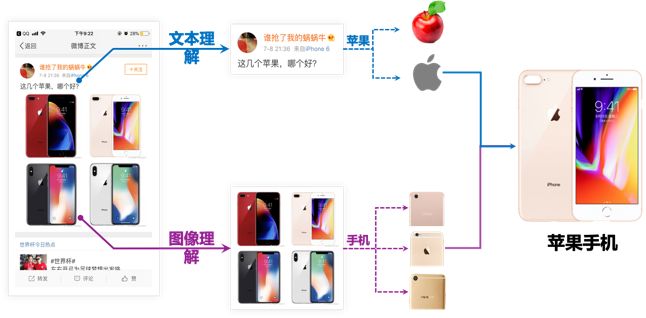
图 1:文本歧义微博示例
2.文本打标签无法处理短文本或者无文本微博。
博主有时候也会发纯图像微博或者配短文本的微博,文本分析无法理解作者的意图,如图 2。
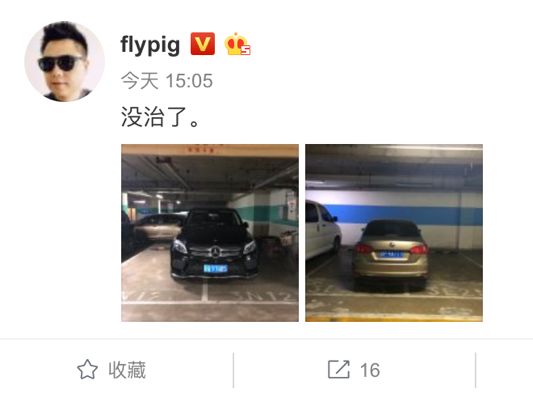
图 2:短文本微博示例
3. 图像理解需要大量的标注样本。
对于无文本或短文本微博,通过图像理解技术可以达到博文理解的目的。然而,目前图像理解需要大量的人工标注,且不利于标签数量的快速增加。
微博的内容理解输出图像标签和微博标签两种标签。一条带图微博包含的图像个数不等(0<图像个数<10),图像标签主要表达单张图像表达的主题,可以进一步用于微博理解,或者单独用于图像推荐和分发;微博标签主要表达整条微博(包括文本和图像)表达的信息,可以通过文本标签和图像标签融合得到。
我们假定长文本微博中文字和图像表达的意思是基本一致的,因此可以采用多模态内容理解方式给图像打标签,基本框架结构如图 3。通过多模态方式得到图像标签后,可以进一步结合文本信息和图像标签给微博打标签。同时,利用多模态方式,可以生产一批带标签的图像样本,用于训练图像分类模型的图像打标签(如 Inception-Resnet V2),用于只包含图像,或短文本(少于 10 字)的图像理解。反过来也可用于多模态内容理解的数据预处理。利用此框架结构,可以逐渐自动扩展标签个数,减少人工标注成本。
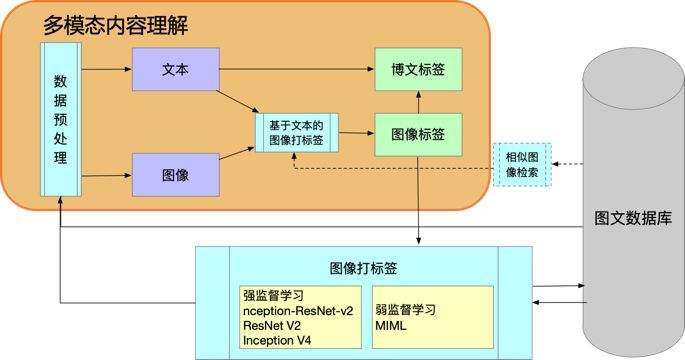
图 3. 多模态图像内容理解框架
另外,通过多模态内容理解,可以为图像提供更准确更精细的标签。如图 4,基于文本的标签结果为“投资”、“谷歌”、“无人驾驶汽车”, 图像标签为“交通工具”、“汽车”。通过多模态方式,可以为此图像打上 “无人驾驶汽车”这一精细的标签,有利于物料分发和个性化推荐。

图 4. 多模态精细标签示例
微博标签体系是一种树形结构,分为一、二、三级。文本标签反映着文本的一个主题信息,图片标签反映着图片的主题信息,只有它们的主题信息重合时,认为它们反映同一主题,具有语义一致性。优质微博一般语义一致性较好,所以训练样本尽量选择优质微博物料。然后删除文本过短样本(小于 10 个汉字),表情包等无意义的图像样本。同时我们使用 Inception-Resnet v2 网络结构训练了只包含一级标签的图像分类模型。为了保证图像和文字表达的一致性,我们选取了文本一级标签(来源文本打标签及人工审核标签)和图像一级标签一致或相关的物料,然后将图文标签二级及以下标签合并做为样本标签。流程如图 5。
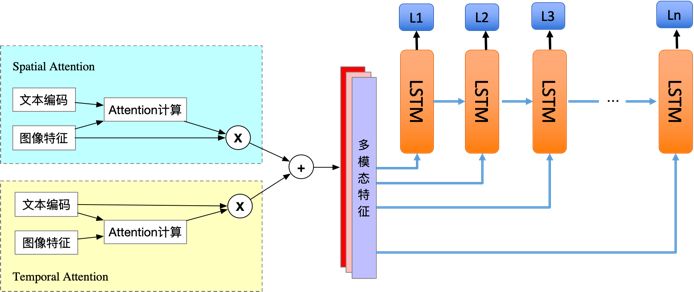
图 5. 训练样本获取流程
我们采用紧耦合的方法,主体结构为 Encoder-Decoder 框架,输入部分两个源:一个为微博文本,一个为对应图片,输出为图像对应的多标签类别。Encoder 部分对微博文本和图片两个模态融合,图像是看成一个二维空间维度信息表达,而文本句子可以看成是一个时间维度的信息表达,并且不是图像中的每个像素和文本中的单词同样重要,对内容理解帮助最大的可能只是局部信息,因此,我们采用基于 Spatial-Temporal Attention 模型融合文本和图像,在 Spatial Attention 部分通过文本增强图像特征,而在 Temporal Attention 部分通过图像增强文本特征。最后将 Encoder 的输出的多模态特征作为 Decoder 的输入,通过 Decoder 解码部分输出多个标签。Decoder 部分使用的 LSTM 模型,当然,LSTM 也可以用 GRU、SRU 等替换。

图 6. 多模态内容理解网络框架
在模型训练过程中,如果只使用样本中的文本进行 Embedding 特征训练,样本量偏少并且分布不均,造成文本编码的表达能力弱,无法使用。因此,我们采用在大规模的微博文本语料上进行单独预训练,保证了文本编码的多样性和准确性。图像特征采用 Inception-ResNet-V2 网络在 ImageNet 数据集训练得到的特征。
经过数据清洗及预处理,我们整理了 12 个一级标签,扩充一二三级标签总共 26 个,20000 条数据用于训练,人工标注 4000 条图文标签用于测试。为了结果能够反映各个标签,度量指标采用宏平均 F1 值,即先对每一个标签统计 F1 值,然后在对所有类求算术平均值。实验宏平均 F1 值为 0.94187,得到了预期的结果。

图 7. 多模态图像标签示例一
上图文本为“生活不需多丰富,一碟青菜配红酒。有生实现中国梦,再添道菜带点肉。”图像为一碟菜和一杯红酒。如果只用图像只能打上“美食”的一级标签,但结合文本的多模态打标签,可以打上更详细的标签“中餐”、“厨艺”等二级标签。

图 8. 多模态图像标签示例二
同样的,上图文本为“迷人高级灰,高颜值混搭风”, 图像内容为家装。只依赖文本,很难理解本条微博所表达的意思。但利用多模态方法,可以得到“家装家居”的一级标签,还可以得的二级标签“家居装修”。
另外,在得到图像标签后,我们也尝试采用投票机制对微博打标签,选择具有多图的微博 10000 条,约 50000 张图片,投票结果直接选择 top1 准确率为 0.84881, 修正文本标签结果占比达 10% 左右。
利用多模态技术一定程度解决人工标注图文数据的繁琐的费力工作,不足之处是初始数据的构建仍然需要图片分类接口和文本标签的接口来筛选物料,下一步我们尝试将 OCR、人脸检测等特征也融入到模型中。另外,尝试通过机器学习直接判断图像和文本表达是否一致,如果一致则采用多模态方式,否则微博标签直接使用文本标签。
上面简单介绍了多模态在图像理解中的应用探索。在当前自媒体时代,视频在社交网络中的比重也越来越重,视频内容理解的需求也随之增加。而视频本身就包含了多模态信息(图像序列、语音、图像中的文本等),多模态信息处理技术将会扮演重要的角色。我们将会加大多模态在视频理解方面的投入。同时也会在用户画像、个性化推荐等方向进行多模态方面的探索及应用落地。
对于整个业界,随着 4G、5G 网络及传感器技术的发展,在自动驾驶、自然人机交互、AR/VR 等领域数据类型也会有新的变化,如 depth 图像、全景图像、Lidar 图像、立体感音频等,这也会给多模态内容理解带来新的需求。
多模态内容理解技术方面,企业界主要还是以松耦合的方法为主;紧耦合方法也会逐渐成熟,逐渐应用于业界。主要的方向有:
一. 与知识图谱的结合。利用基于有监督深度学习的模型分别理解各个模态,同时结合知识图谱深入理解多模态中各模态的内部关系,进而提供更准确高效的方案。
二. 增加推理能力。目前无论单模态内容理解还是多模态内容理解,都是以数据驱动的技术,如何将所“感知”到的东西进行推理,以避免不合逻辑的识别结果。
另外,借助于多模态信息处理,小规模样本数据和非监督的内容理解将会有一定的突破。当前内容理解主要以数据驱动,需要大量的标注样本。多模态包含比单模态更丰富的信息,并且存在一定的信息冗余,通过多模态之间信息相互增强和补充,在小规模样本数据和非监督内容理解方面比单模态更有优势。
多模态将会为内容理解带来新的突破,值得我们关注和期待。
梁清华,微博研发中心算法工程师,2016 年 4 月毕业于北京交通大学,获信号与信息处理专业工学博士学位。长期从事图像处理和计算机视觉相关的研发工作,主要研究方向有图像内容理解,OCR,三维重建 SLAM 等。

你也「在看」吗?👇



