![]()
喜欢冲浪的早期网民可能听说过一个叫「Usenet」的讨论组应用。它的功能类似于我们今天用的贴吧、论坛,但使用方法却更接近邮箱客户端。
三四十年前,在没有浏览器的年代,我们的互联网前辈就在 Usenet 上交流想法,包括一些早期的码农。随着 Usenet 走向衰落,谷歌接管了该讨论组自 1981 年以来的大部分历史备份,并将其放在 Google Groups 上供所有人查看。
这些早期资料对于计算机界的「考古挖掘」非常有帮助,比如追溯某个词的词源、记录某种语言的演变。
然而,最近,
谷歌却突然关闭了其中的两个小组(Forth 和 Lisp),引发了社区的不满
。
Forth 和 Lisp 是两种非常「古老」的语言,年龄上和「上古语言」Cobol 不相上下(都诞生于上世纪五六十年代),Lisp 甚至比 Cobol 还大一岁。因此,这两个讨论组也称得上是历史悠久。
虽然随着新语言的不断崛起,这两种语言逐渐失去了自己的优势,变得不再流行,但我们还是希望关于他们的一些早期资料可以保留下来。这些资料说不定可以帮我们解决一些历史遗留问题(参见前段时间疯狂招聘「高龄程序员」的 COBOL)。
一位网友在 LWN.net 上发帖表示,「(这件事)所造成的影响是极具破坏性的,意味着两个社区的历史和集体记忆正在被擦除。」
![]()
由于 Usenet 在中国并未流行起来,我们可能无法体会这些外国网友的心情。但有一点是共通的:我们并不希望互联网上有价值的一些东西永远消失。
谷歌的这一举动不禁让我们联想起 GitHub 前不久实施的「北极代码库」项目。除了代码之外,整个互联网资料的保存问题或许也该多讨论一下了。
上世纪七十年代,互联网和浏览器都还没有出现。那个年代的「上网」也叫「拨号上网」,就是通过调制解调器拨一个电话号码才能将自己的电脑与其他电脑(主机)相连,如果想换一台主机就得重新拨号。
![]()
这种上网方式有一个弊端:如果你想登录离你比较远的主机,首先电话费会比较贵;其次,当时的主机能力比较差,负担不起太多远程用户的同时登录。因此,登录同一台主机的通常是地理位置比较接近的用户。
1979 年,杜克大学的研究生汤姆 · 特拉斯科特与吉姆 · 埃利斯设计出了
一种分布式的互联网交流系统,取名为 Usenet(也叫 Newsgroup)
。
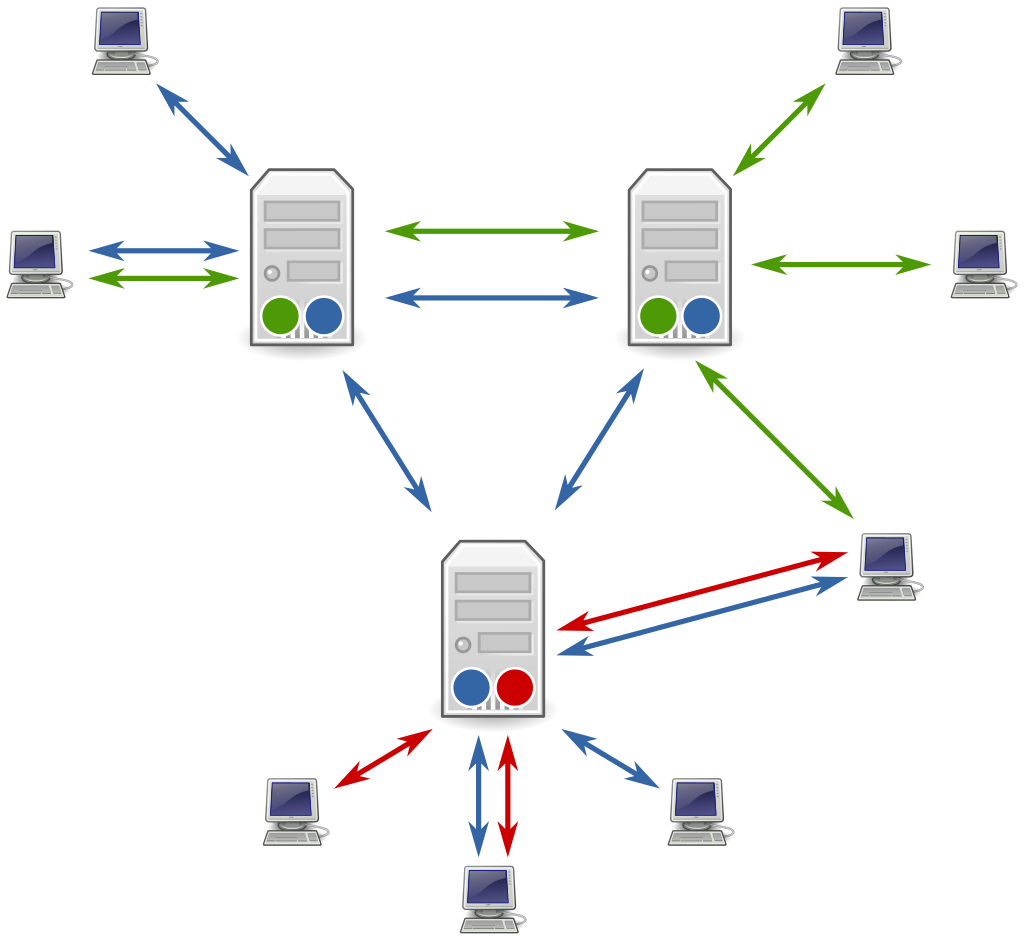
Usenet 分布在一个不断变化的大型服务器集群中,这些服务器在「新闻源」中相互存储和转发消息。它与 BBS/Web 论坛的主要区别在于其缺少中央服务器和管理员。
![]()
知名科技博主阮一峰曾在 2007 年的一个帖子中介绍过 Usenet 的运行机制:
![]()
从上面这个机制描述中我们可以看出,
在 Usenet 上的交流其实是一个不断上传下载的过程,使用起来真的很不方便,而且多数情况下还要付费
。
因此,经过了十几年的发展之后,这个讨论组从 90 年代开始衰落。PC Magazine 的萨沙 · 西根在 2008 年表示「Usenet 已经奄奄一息了」。
一个不符合时代发展潮流的工具逐渐退出历史舞台是一种必然,但问题在于:
上面存储的历史资料何去何从
?
其实,早在 Usenet 创建之初就有人提到了这个问题。1982 年,一位名叫 Scott Orshan 的 Usenet 用户提出,「任何网站都应该永远保留它所发布的所有文章」。此外,他还提出了一种 Usenet 的分布式归档的方案。此后的数年,Usenet 一直在系统性地备份并储存积累的帖子,这些计划的参与者既包括个人,也包括商业公司,DejaNews 就是其中之一。
2001 年,谷歌收购了 DejaNews 并接手了该公司的 Usenet 存档,以此为基础创建了 Google Groups(谷歌网上论坛)。此后,谷歌又陆续收到了多方的存档捐赠,包括多伦多大学动物学系的亨利 · 斯宾塞存档(包含从 1981 年 5 月到 1991 年 6 月的帖子)、NetNews CD 系列的肯特 · 兰菲尔德和 GMD 的克里斯托弗尔(从 1991 年底至 1995 年初的存档)等。
可以说,在 Usenet 走向消亡的日子里,Google Groups 其实扮演了一个博物馆的角色,将 1981 年以来的 Usenet 讨论资料开放给所有人查阅。
然而,在大家都以为这是 Usenet 数据的最佳归宿时,谷歌却做出了一些令人失望的决定。
2020 年,已经没有太多人会去 Google Groups 搜索上世纪的材料了,但我们知道,它们就在那里,想看随时都能看。
但现在,随着两个编程语言小组的关闭,这份寄托被打破了。
有人谴责谷歌辜负了大家的信任,没有承担起保护历史档案的责任。
![]()
有人从中看到了互联网公司在保存资料方面的「不靠谱」:「20 年前谷歌接管 Usenet 存档的时候大家都很开心,还把自己的存档捐给了谷歌。但现在,大家对于谷歌云平台 5 年后还能不能用都持怀疑态度。」
![]()
这次变动也引起了 Hackernews 社区的热议,一位网友提到了自己在参观美国地质调查局的有趣经历:
![]()
「策展人表示自己不喜欢谷歌(即使谷歌和他们相隔仅几个街区)。他说,谷歌是伟大的,因为谷歌地图更加精准,有着更高的覆盖度。」
这位策展人被要求将所有的历史 arial 档案移交给谷歌进行扫描,然后告诉美国地质调查局不再进行 arial 扫描了,因为谷歌正在做这件事。然而谷歌并不会把扫描结果交还给美国地质调查局。
当时,这位网友曾经安慰策展人,表示谷歌永远也不会删除自己收集的数据。现在想来,这种担心不无道理。
「这就是整个互联网的问题。还记得那些在 20 世纪 90 年代或者 21 世纪初创建的页面吗?人们以为他们在和全世界分享这些信息。事实证明,那时候创建的页面现在大多都无法访问了,或者是被大公司排挤掉了。」
![]()
所以,有人尝试建立了个人博客,确保自己不被平台供应商所束缚,而且这种方式几乎是免费的。导流问题可以通过 Medium 的导入功能解决,但目前不确定能起到多大的效果。
![]()
也有人提到,为每个页面永久存档本就不是公司的职责。比如在英国,大英图书馆会对所有网站的年度快照进行收集保存。
![]()
其实,「互联网档案馆(Internet Archive)」等机构和个人也保存了一部分 Usenet 的早期资料,但可能没有谷歌那么丰富,尤其是 90 年代之前的一些数据。
![]()
随着时代的飞速发展,越来越多的互联网资料正在从我们的视线里消失。究竟谁应该担负起保存互联网档案的责任?这些资料要怎么保存?这些都是亟待解决的问题。
https://news.ycombinator.com/item?id=23977375
http://www.ruanyifeng.com/blog/2007/11/usenet.html
https://www.huxiu.com/article/299650.html
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com