11月5日,在Wave Summit+2019深度学习开发者峰会上,飞桨全新发布和重要升级了最新的21项进展,在深度学习
开发者社区引起了巨大的反响。机器之心
现场亲历了发布会的全部环节,并
且在《半年21项全新发布和升级,百度飞桨团队「码力」全开》这篇文章中作了详细介绍,再次引发国货当自强的评论。
很多未到场的开发者觉得遗憾,希望可以了解飞桨发布会背后的更多技术细节。机器之心策划了一个系列稿件,分别从核心框架、基础模型库、端到端开发套件、工具组件和服务平台五个层面分别详细解读飞桨的核心技术与最新进展,敬请关注。
今天给大家带来的是飞桨系列解读文章之核心框架揭秘,本文对飞桨最重要的核心框架的进行解读,公布了大量珍贵的资料内容,很多飞桨核心框架的关键性内容属于首次深度解读。
![]()
飞桨全景图,本文主要针对核心框架部分进行深度解读。
本次核心框架重要升级
1.1.开发-易用性提升
1.2.训练-速度优化
1.3.预测-部署能力强化
从Release note中可以看到,本次的升级点还是比较多的。而且从字里行间也可以看得出,每一个几十字的点,背后其实是非常重的工作量。但是毕竟缺少细节,我们再来详细解读一下发布会PPT的重点内容。
飞桨核心框架升级重点图文解读
2.1.核心框架易用性的全面提升
![]()
首先是算子的全面性,对于任何一个算法,基本算子库是基础,对于完善和全面性都有很高的要求。
飞桨通过这次新版本的发布,基本上可以保证支持全部AI主流领域的模型。
其次是API接口的升级,这里有两个层面:
一是数据层,飞桨本次升级把IO的接口做了非常全面的梳理和进一步的呈现,易用性大幅提升。
二是分布式训练的易用性。
在单机上开发好的算法,在训练时面对非常大规模数据时需要进行分布式训练,代码也需要调整,对于不了解分布式训练的开发者困难很大。
通过本次发布,只需要新增5行代码再加上对于执行语句的少量修改,就可以把单机版改成分布式并行训练。
![]()
最后,根据开发者持续以来的反馈,飞桨不断的完善文档的内容,并且提供中英双语文档。
本次发布,飞桨在中文的文档上进行了非常多的升级和完善,本着打造艺术品的标准来打磨API文档。
可以为开发者提供更清晰,有示例,甚至有时候会得到一些灵感的文档。
2.2.分布式训练的高性能
分布式训练的高性能,是飞桨的核心优势技术之一,这也与飞桨本身就是源于大数据的产业实践分不开的,在CPU和GPU方向分布式性能都有很好的性能优势。
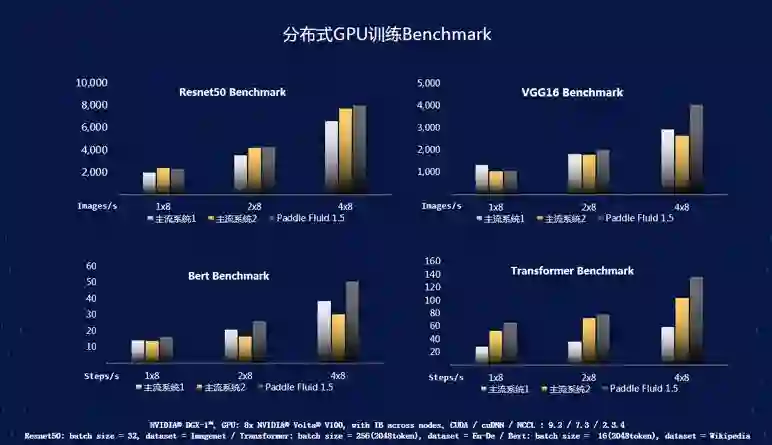
通过GPU分布式训练下的Benchmark,可以看到在8x8 v100硬件条件下,相比其他主流实现可以获得20%-100%的速度提升。
![]()
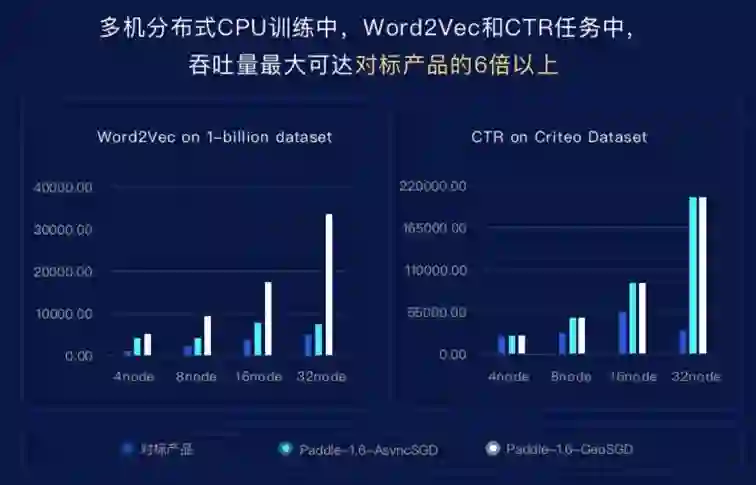
通过多机分布式CPU训练Benchmark比较,基于飞桨自研的高性能异步训练算法Geo-SGD,可以看到分布式训练在Word2Vec和CTR任务中,飞桨吞吐量最大可达对标产品的6倍以上。
![]()
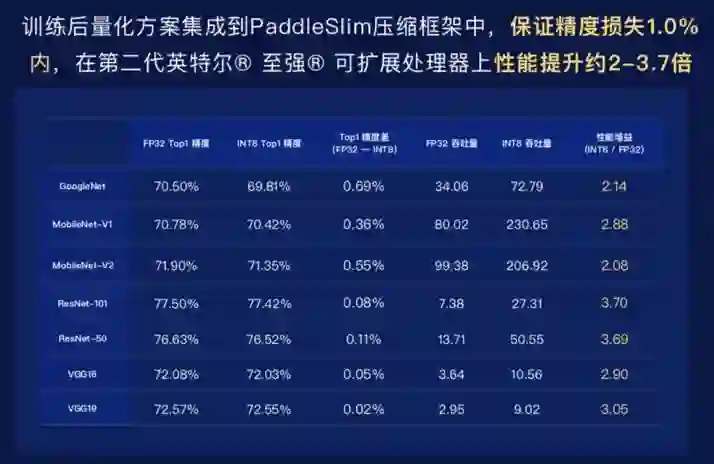
同时飞桨与英特尔也开展密切合作,在最新的英特尔至强可扩展处理器上,在保证精度基本不变的情况下,通过INT8的量化训练,性能的提升也能达到2到3.7倍,非常适合实际业务使用。
![]()
2.3.打通端到端的部署全流程
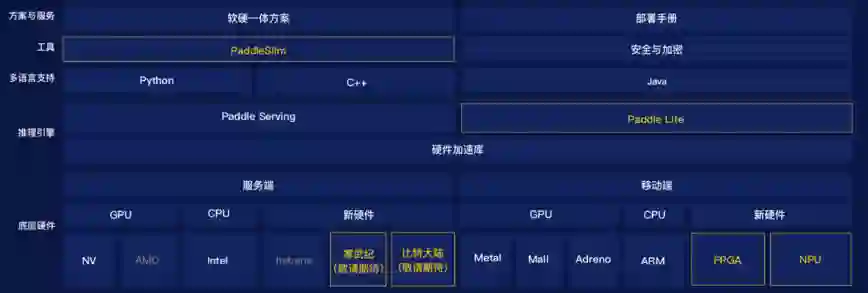
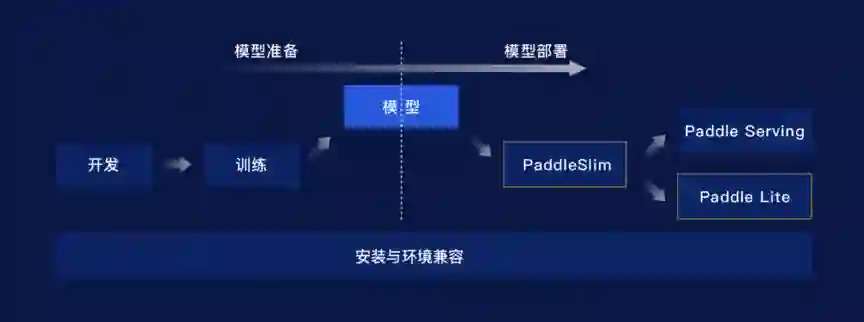
除了开发的易用性和训练的高性能,飞桨在打通端到端部署方面,也发布了一些最新进展。
![]()
从整个端到端部署涉及到的工作内容上看,需要做的工作还是非常多的,首先就是要适配不同的硬件。
在最新的版本里面,飞桨新增了对于华为NPU的适配,以及对于边缘设备上FPGA的适配。
后续还会进一步发布跟寒武纪和比特大陆适配,敬请期待。
![]()
从整个打通端到端部署的流程来看,在搭建模型和训练模型之后,会根据部署环境的特点,对模型做压缩处理,其目标包括压缩模型存储体积和提升推理速度。
目前针对移动设备端环境常见的一个常用且比较成熟的压缩策略是INT8量化,该方法可以大幅压缩模型的体积,并提升预测效率。
![]()
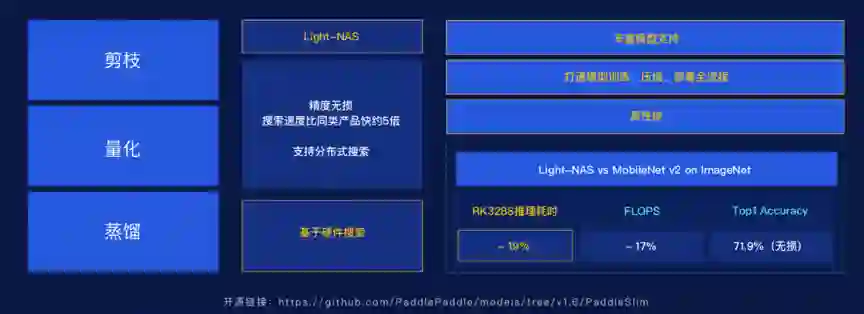
飞桨在上一个版本已经支持了剪枝、量化、蒸馏等压缩方法。
这次的升级重点是优化和增强自动化网络结构设计,我们直接把候选模型在具体硬件上的推理速度作为搜索的一个约束条件。
基于这种策略,搜索到的模型可能更好的适配目标硬件,在保证精度的情况下获得更多的速度收益。
在ImageNet1000类分类任务上,通过Light-NAS搜索到的模型,精度无损,在某款移动端硬件上的实际推理速度提升了20%。
除了模型压缩策略增强之外,PaddleSlim通过打通检测库提供了更丰富的模型支持,同时保证了压缩产出的模型支持用PaddleLite直接部署。
了解完PaddleSlim的升级点之后,Paddle Lite 2.0版本也是正式发布。
主要特点:
![]()
一是非常高的易用性。
在移动端开发应用程序或者是在边缘设备上开发应用程序涉及到非常多的设备环境的连调工作,Paddle Lite里面提供大量的示例代码,以及操作的指南,方便大家能够快速的去实现在不同的设备场景上进行部署。
二是非常广泛的硬件支持。
Paddle Lite目前已经支持了8种主流的硬件,同时还支持华为的NPU和边缘设备的FPGA。
而且Paddle Lite整个架构设计非常便于新硬件的扩展。
新的硬件适配,只要去Paddle Lite里面新增这个硬件相关的Kernel就可以了,与框架代码是高度解耦的。
可以非常便捷的适配新硬件。
三是性能优势。
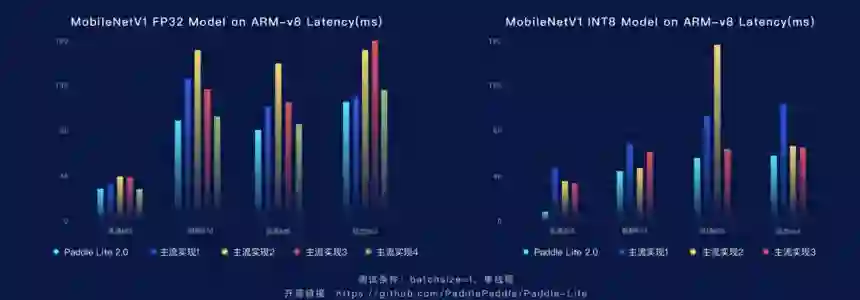
Paddle Lite一个非常显著的优势是在性能方面处在领先状态。
性能的优势不仅仅是在FP32这种场景下,尤其是在现在移动端已经广泛普及的INT8上,领先优势会更加明显。
![]()
对比不同的推理框架使用MobileNetV1在ARM-v8上面推理延时,在FP32上大家可以看到,Paddle Lite 2.0已经具备全面领先的优势。
而右侧INT8的条件下,性能优势更加显著。
在真正的移动端下的推理场景,真正达到的性能的优势对于实际的应用是至关重要的,时延上的优势直接关系到最终开发产品的用户体验。
飞桨核心框架技术完整公开解读
飞桨深度学习框架核心技术,主要包括前端语言、组网编程范式、核心架构、算子库以及高效率计算核心五部分。
3.1.核心架构
飞桨核心架构采用分层设计,如图3所示。前端应用层考虑灵活性,采用Python实现,包括了组网 API、IO API、OptimizerAPI和执行 API等完备的开发接口;框架底层充分考虑性能,采用C++来实现。框架内核部分,主要包含执行器、存储管理和中间表达优化;内部表示方面,包含网络表示(ProgramDesc)、数据表示(Variable)和计算表示(Operator)几个层面。框架向下对接各种芯片架构,可以支持深度学习模型在不同异构设备上的高效运行。
![]()
3.2.关键技术
(1)前端语言
为了方便用户使用,选择Python作为模型开发和执行调用的主要前端语言,并提供了丰富的编程接口API。Python作为一种解释型编程语言,代码修改不需要重新编译就可以直接运行,使用和调试非常方便,并且拥有丰富的第三方库和语法糖,拥有众多的用户群体。同时为了保证框架的执行效率,飞桨底层实现采用C++。对于预测推理,为方便部署应用,则同时提供了C++和Java API。
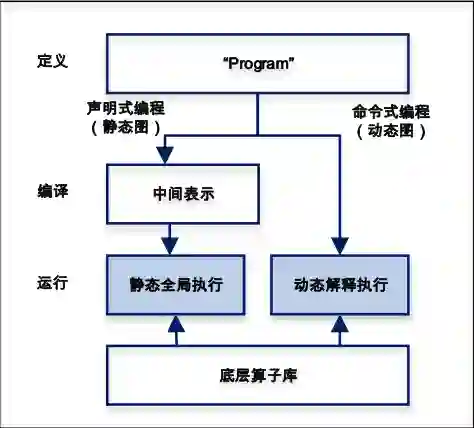
(2)组网编程范式
飞桨中同时兼容命令式编程(动态图)与声明式编程(静态图)两种编程范式,飞桨以程序化“Program”的形式动态描述神经网络模型计算过程,并提供对顺序、分支和循环三种执行结构的支持,可以组合描述任意复杂的模型,并可在内部自动转化为中间表示的描述语言。“Program”的定义过程就像在写一段通用程序。使用声明式编程时,相当于将“Program”先编译再执行,可类比静态图模式。首先根据网络定义代码构造“Program”,然后将“Program”编译优化,最后通过执行器执行“Program”,具备高效性能;同时由于存在静态的网络结构信息,能够方便地完成模型的部署上线。而命令式编程,相当于将“Program”解释执行,可视为动态图模式,更加符合用户的编程习惯,代码编写和调试也更加方便。飞桨后面会增强静态图模式下的调试功能,方便开发调试;同时提升动态图模式的运行效率,加强动态图自动转静态图的能力,快速完成部署上线;同时更加完善接口的设计和功能,整体提升框架易用性。
![]()
(3)显存管理
飞桨为用户提供技术领先、简单易用、兼顾显存回收与复用的显存优化策略,在很多模型上的表现优于其他开源框架。
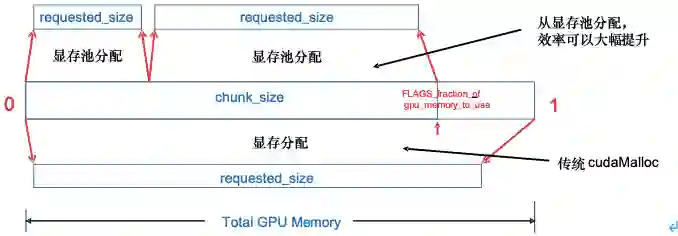
原生的CUDA系统调用(cudaMalloc)和释放(cudaFree)均是同步操作,非常耗时。为了加速显存分配,飞桨实现了显存预分配的策略,具体方式如图4所示。设置一个显存池chunk,定义其大小为chunk_size。若分配需求requested_size不超过chunk_size,则框架会预先分配chunk_size大小的显存池chunk,并从中分出requested_size大小的块返回。之后每次申请显存都会从chunk中分配。若requested_size大于chunk_size,则框架会调用cudaMalloc分配requested_size大小的显存。chunk_size一般依据初始可用显存大小按比例确定。同时飞桨也支持按实际显存占用大小的动态自增长的显存分配方式,可以更精准地控制显存使用,以节省对显存占用量,方便多任务同时运行。
![]()
显存垃圾及时回收机制GC(Garbage Collection)的原理是在网络运行阶段释放无用变量的显存空间,达到节省显存的目的。GC策略会积攒一定大小的显存垃圾后再统一释放。GC内部会根据变量占用的显存大小,对变量进行降序排列,且仅回收前面满足占用大小阈值以上的变量显存。GC策略默认生效于使用Executor或Parallel Executor做模型训练预测时。
Operator内部显存复用机制(Inplace)的原理是Operator的输出复用Operator输入的显存空间。例如,数据整形(reshape)操作的输出和输入可复用同一片显存空间。Inplace策略可通过构建策略(BuildStrategy)设置生效于Parallel Executor的执行过程中。
(4) 算子库
飞桨算子库目前提供了500余个算子,并在持续增加,能够有效支持自然语言处理、计算机视觉、语音等各个方向模型的快速构建。同时提供了高质量的中英文文档,更方便国内外开发者学习使用。文档中对每个算子都进行了详细描述,包括原理介绍、计算公式、论文出处,详细的参数说明和完整的代码调用示例。
飞桨的算子库覆盖了深度学习相关的广泛的计算单元类型。比如提供了多种循环神经网络(Recurrent Neural Network,RNN),多种卷积神经网络(Convolutional Neural Networks, CNN)及相关操作,如深度可分离卷积(
Depthwise Deparable Convolution)、空洞卷积(Dilated Convolution)、可变形卷积(Deformable Convolution)、池化兴趣区域池化及其各种扩展、分组归一化、多设备同步的批归一化,另外涵盖多种损失函数和数值优化算法,可以很好地支持自然语言处理的语言模型、阅读理解、对话模型、视觉的分类、检测、分割、生成、光学字符识别(Optical Character Recognition,OCR)、OCR检测、姿态估计、度量学习、人脸识别、人脸检测等各类模型。
飞桨的算子库除了在数量上进行扩充之外,还在功能性、易用性、便捷开发上持续增强:例如针对图像生成任务,支持生成算法中的梯度惩罚功能,即支持算子的二次反向能力;而对于复杂网络的搭建,将会提供更高级的模块化算子,使模型构建更加简单的同时也能获得更好的性能;对于创新型网络结构的需求,将会进一步简化算子的自定义实现方式,支持Python算子实现,对性能要求高的算子提供更方便的、与框架解耦的C++实现方式,可使得开发者快速实现自定义的算子,验证算法。
(5)高效率计算核心
飞桨提供了大量不同粒度的Operator(Op)实现。细粒度的Op能够提供更好的灵活性,而粗粒度的Op则能提供更好的计算性能。飞桨提供了诸如softmax_with_cross_entropy等组合功能Op,也提供了像fusion_conv_inception、fused_elemwise_activation等融合类Operator。其中大部分普通Op,用户可以直接通过Python API配置使用,而很多融合的Op,执行器在计算图优化的时候将会自动进行子图匹配和替换。
飞桨主要通过两种方式来实现对不同硬件的支持:人工调优的核函数实现和集成供应商优化库。
针对CPU平台,飞桨一方面提供了使用指令Intrinsic函数和借助于xbyak JIT汇编器实现的原生Operator,深入挖掘编译时和运行时性能;另一方面,飞桨通过引入OpenBLAS、Intel® MKL、Intel® MKL-DNN 和nGraph,对Intel CXL等新型芯片提供了性能保证。
针对GPU平台,飞桨既为大部分Operator用CUDA C实现了经过人工精心优化的核函数,也集成了cuBLAS、cuDNN等供应商库的新接口、新特性。
注:以上核心框架解读部分内容已经正式发表在中英文期刊《数据与计算发展前沿》(CN 10-1649/TP,ISSN 2096-742X)
本文对于飞桨核心框架的深度解读,也是飞桨全新发布完整解读的系列文章之(一),后续还会继续推出五篇系列文章,敬请期待。
想与更多的深度学习开发者交流,请加入飞桨官方QQ群:
796771754。
如果您想详细了解更多飞桨PaddlePaddle的相关内容,请参阅以下文档。
-
官网地址:
https://www.paddlepaddle.org.cn/
-
核心框架:
https://github.com/PaddlePaddle/Paddle
-
分布式训练:
https://github.com/PaddlePaddle/Fleet
-
PaddleLite:
https://github.com/PaddlePaddle/Paddle-Lite
-
PaddleSlim:
https://github.com/PaddlePaddle/models/tree/release/1.6/PaddleSlim
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com