谷歌给NeRF动了个小手术,2D变3D,照片视角随心换

新智元报道
新智元报道
来源:arxiv等
编辑:白峰
【新智元导读】近日,Google研究人员又开发了一个3D场景转换的新模型,该模型基于之前大火的神经辐射场,可以在变化的场景和遮挡下重构出逼真的3D动态场景。

3D场景重构神器:神经辐射场

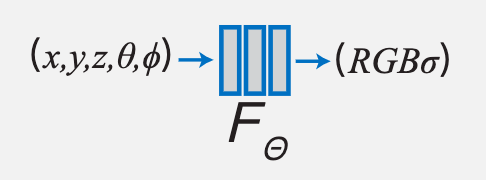
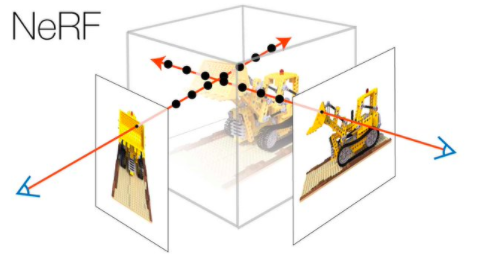


对NeRF动个小手术,让它适应变化的场景
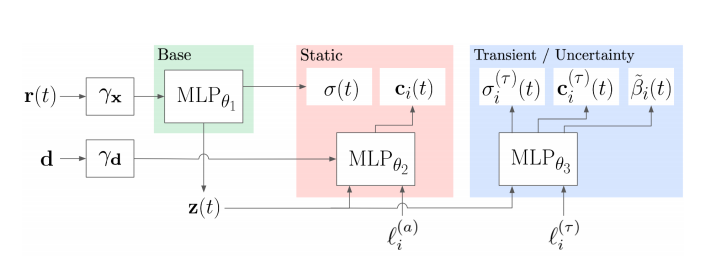 NeRF-W架构
NeRF-W架构
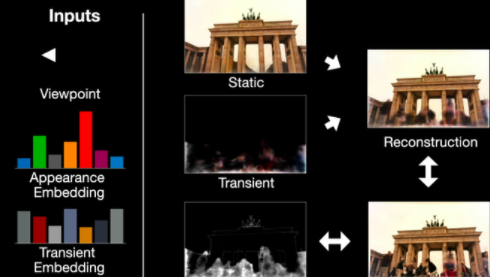




登录查看更多
相关内容
专知会员服务
37+阅读 · 2020年2月27日
Arxiv
4+阅读 · 2018年1月23日



相关VIP内容
专知会员服务
37+阅读 · 2020年2月27日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年1月23日