ICCV 2019 | 从多视角RGB图像生成三维网格模型Pixel2Mesh++

本文发表于 ICCV 2019,由复旦大学、Google 公司和 NURO 公司合作完成。文章提出了从几张已知相机位置的多视角彩色图片生成三角网格模型(3D Mesh)的网络结构。


Github 链接:
https://github.com/walsvid/Pixel2MeshPlusPlus
模型架构
得益于深度学习的强大表征能力,也来越多的工作关注三维形状生成任务。之前的工作大多直接从先验中直接学习形状,而本文使用图卷积神经网络(GCN [1]),从多视角图片的交叉信息学习进一步提升形状质量。相比于直接建立从图像到最终 3D 形状的映射,本文预测一系列形变,逐渐将由多视角图片生成的粗略形状精细化。
受传统多视角几何的启发,本文从粗略形状的网格顶点周围采样候选的形变位置,利用多视角图片的统计一致性特征来推理形变的可能位置。大量的实验表明,本文的模型可以生成准确的 3D 形状,不仅从输入角度看似合理,而且可以与任意视点很好地对齐。得益于物理驱动的网络结构模块,本文的精细化粗略形状(Coarse Mesh Refinement)的网络结构还展现了跨不同语义类别、不同输入图像数量和初始网格质量的泛化能力。
研究动机
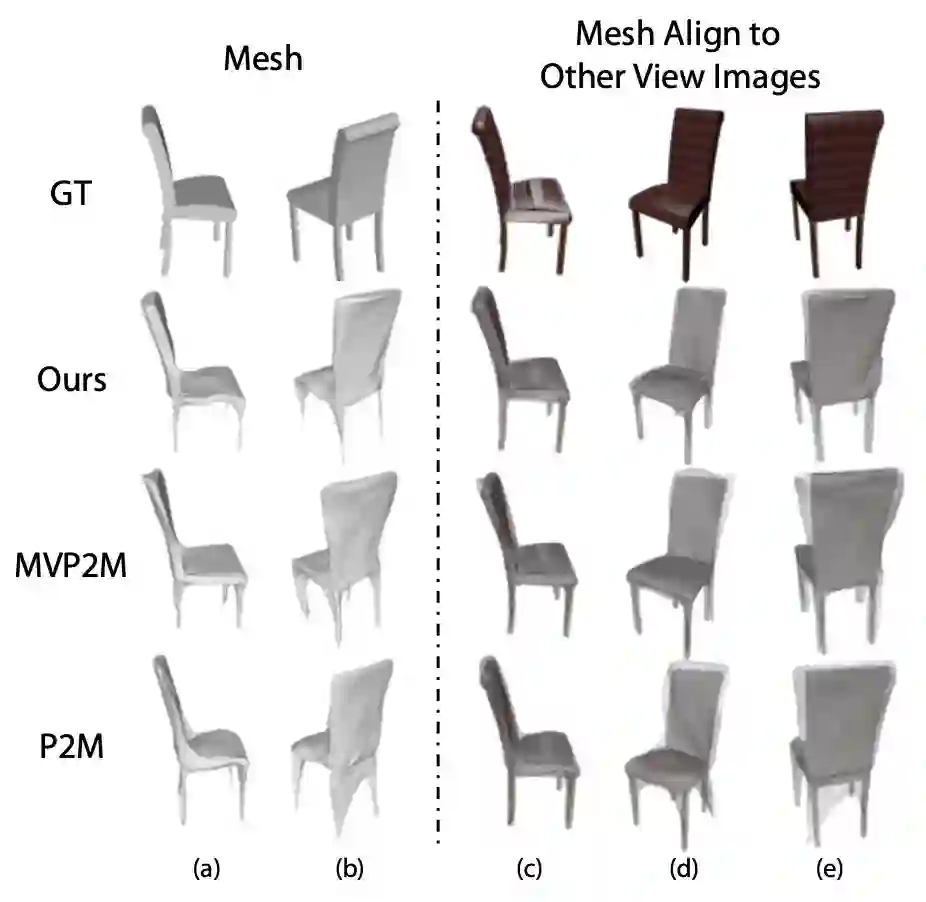
▲ 图1. 不同方法在多个视角的3D-2D对齐情况
凭借深度学习的惊人表示能力,许多文章已经证明了可以仅从单个彩色图像成功生成 3D 形状。然而,由于仅从一个角度观察物体视觉证据有限,基于单个图像的方法通常会在被遮挡的区域中产生粗糙的几何形状,并且在推广到非训练域数据的情况下进行测试时效果不佳,例如跨语义类别。
添加更多的几张图像是为三维形状生成系统提供有关 3D 形状的更多信息的一种行之有效的方法。一方面,多视图图像提供了更多的视觉外观信息。另一方面,传统的多视角几何方法(Multi-view Geometry)从视图之间的对应关系中准确地推断出3D形状,已经有很好的定义,并且不易受到泛化问题的影响。
不过传统方法在多视角图片数量非常有限的情况下难以显式解出形状,但多视角的形状信息则可能直接由神经网络隐式编码和学习。虽然多视角图片有着更好的研究动机,但是这个方向上的研究文献还很少,而且如图 1 所示,将基于单张图片的模型简单扩展为多视图版本效果不佳。
模型架构
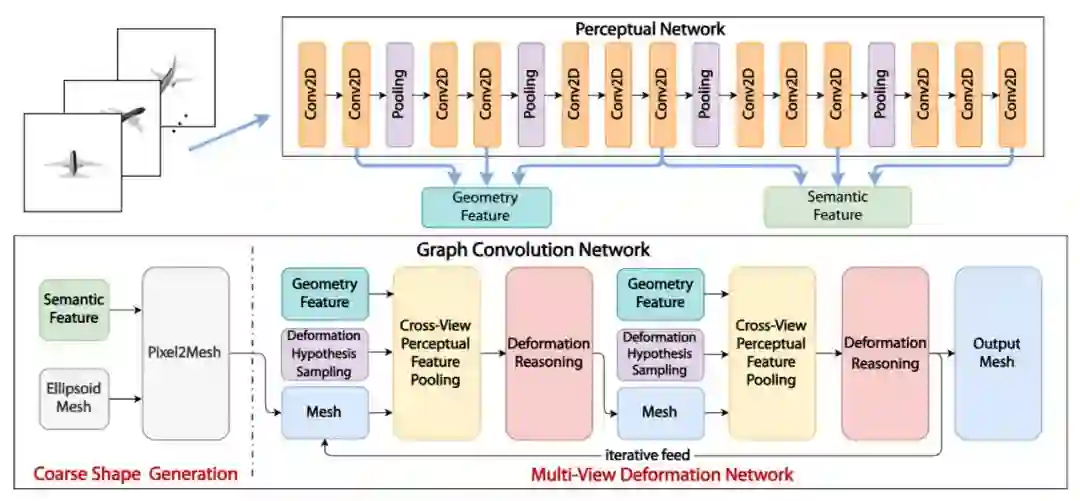
▲ 图2. System Pipeline
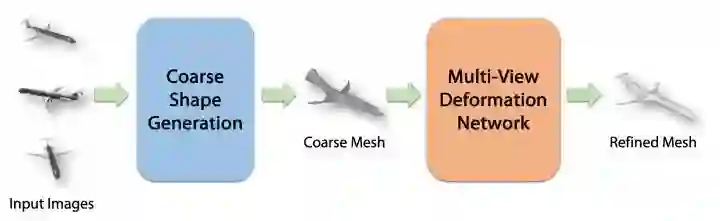
Pixel2Mesh++ 的网络结构如图 2 所示。网络以同一个物体在不同视角的彩色图片作为输入,假设已知不同视角之间的相机参数,最终网络预测一个在主视角相机坐标系下的三维网格模型。
网络由从粗到精的模式进行生成,首先生成合理但粗略的形状,稍后再添加形状细节。由于现有的三维形状生成网络甚至能在仅给出单张图片的情况下提供合理的粗略形状,本文使用 Pixel2Mesh 从单张或多张图片生成粗略形状,作为第一步的粗略形状生成,然后使用 Multi-View Deformation Network (MDN) 进行进一步的细化。
Multi-View Deformation Network是本文网络结构的核心,它首先使用 Deformation Hypothesis Sampling 来获得潜在的形变候选位置,然后用 Cross-View Perceptual Feature Pooling 来从多张图片中汇集跨视角的特征信息,最后由 Deformation Reasoning 模块学习从特征中推断出最佳的变形位置。
MDN 的模型本质上是 GCN,并且可以与其他基于 GCN 的模型(例如 Pixel2Mesh [2])共同训练。但不同点在于 MDN 中的图除了直接表示 3D Mesh 的顶点,还有顶点位置与形变假设(Deformation Hypothesis)组成的局部 GCN。
Deformation Hypothesis Sampling
为每个顶点选择形变的假设位置等价于在顶点周围的 3D 空间中采样点,为了尽可能均匀采样,本文从 Level-1 Icosahedron 上采样 42 个点,并在 Icosahedron 表面和 Mesh 的顶点之间构建局部个 GCN 结构,用以预测 Mesh 顶点的形变。具体结构如图 3 所示。
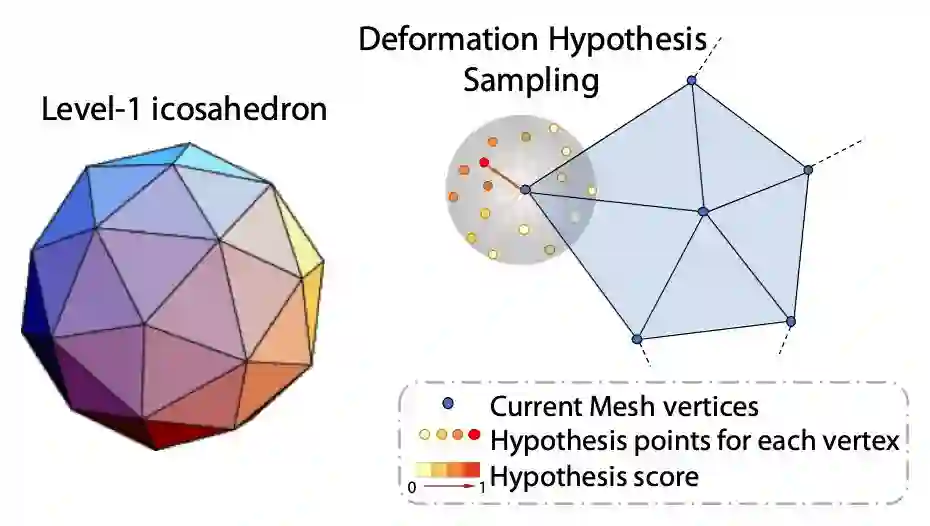
▲ 图3. Deformation Hypothesis Sampling
Cross-View Perceptual Feature Pooling
如何有效从多视角(Multi-view)图像中获取信息是多视图形状生成的关键。受 Pixel2Mesh 启发,本文也使用 VGG16 的结构来提取 perceptual feature。由于假设已知相机内参和外参,每个顶点和形变假设都能在所有的图像平面利用虚拟相机投影得到 2D 坐标。与 Pixel2Mesh 不同,本文使用更靠前的卷积层,以拥有更大的特征图空间尺寸和更局部的特征信息。
在汇集多个图像的特征时,concatenation 往往是一种无损的 aggregate 方式,但这样将导致网络结构与输入图片数量相关。在多视角形状分类任务中使用的统计特征(statistics feature)能解决这一问题。本文通过将任意数量图片的统计量信息(mean, max, std)进行拼接,得到与视角数量无关的跨视角特征。基于统计的图像特征与 3D 坐标特征拼接在一起作为后续用于推理形变位置的特征信息。具体结构如图 4 所示。
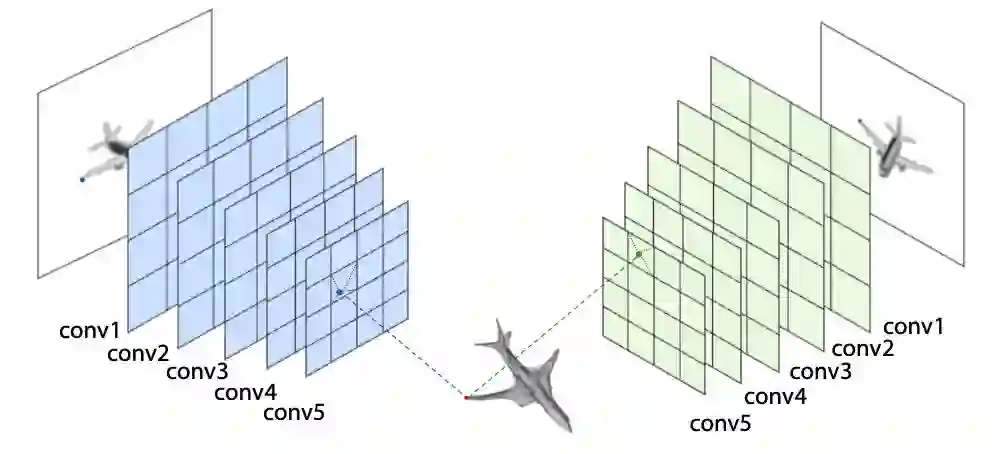
▲ 图4. Cross-View Perceptual Feature Pooling
Deformation Reasoning
为每个顶点推理最优的形变位置是 Pixel2Mesh++ 能够进一步提升形状质量的关键。值得注意的是选择最优的假设需要不可导的 argmax 操作,因此本文还提出了可导的寻找理想形变假设位置的 soft-argmax 模块。具体来说,跨视角的特征 P 通过 GCN,为每个假设学习到权重 c_i,权重再通过 softmax 层来归一化为选择的概率 s_i 其中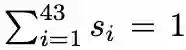
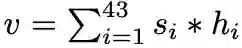
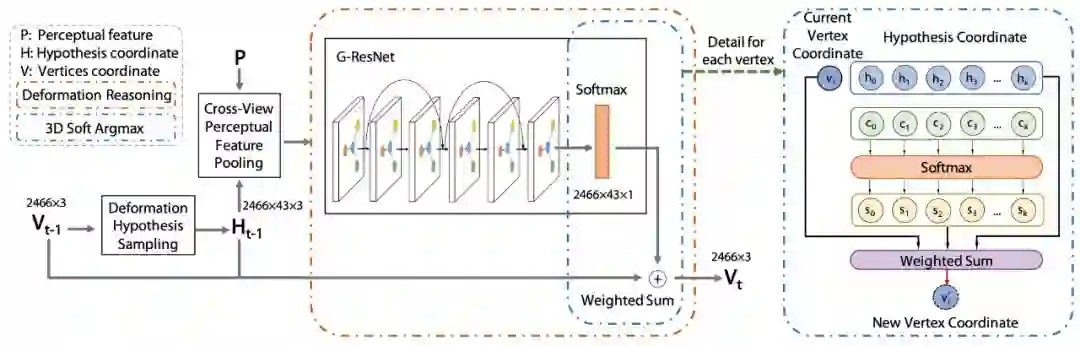
▲ 图5. Deformation Reasoning and 3D-soft-argmax
Loss function
本文继承了 Pixel2Mesh 的损失函数形式,但对 ChamferLoss 进行扩展。受 Ladický et.al [3][4] 启发,从均匀分布中利用重采样公式,在三角形面片中采样点,使得 ChamferLoss 的计算更加稳定合理。采样公式如下:
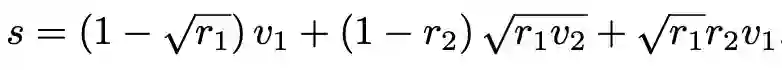
实验效果
实验比较了现有的基于多视角图片生成三维模型的方法 [5][6] 以及利用单张图片生成器 Pixel2Mesh 扩展得到的简单 Baseline。如表 1 所示,实验证明了本文方法在 F-score 的指标上优于现有方法。
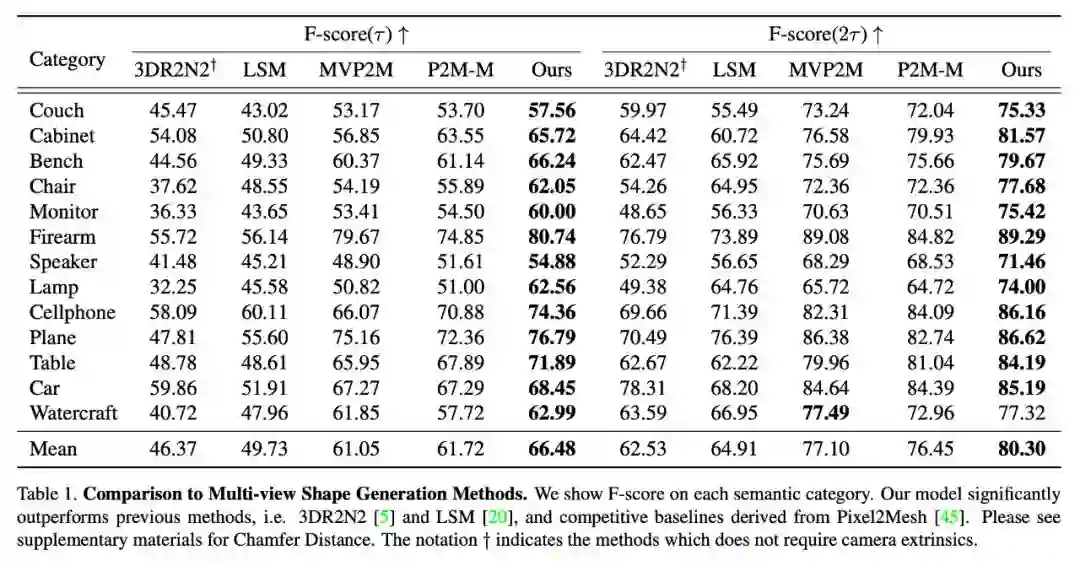
▲ 表1. 与现有方法及baseline的F-score对比
实验生成三维网格模型的结果如图 6 所示:

▲ 图6. 网格生成结果
同时本文还通过实验比较了 MDN 的强大泛化能力,包括跨语义类别、图片数量和初始粗略形状质量等,图 7 为针对 Initial Mesh 的不同质量的鲁棒性实验。
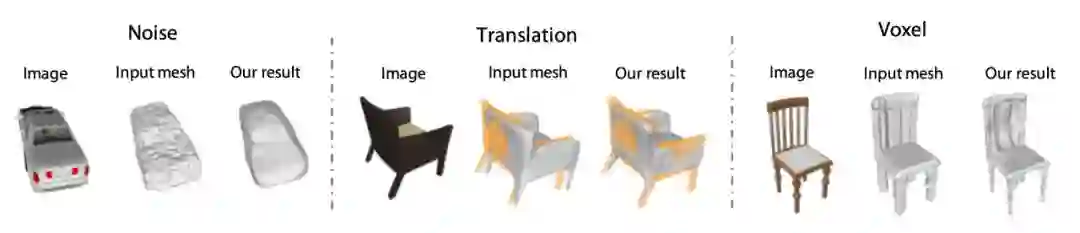
▲ 图7. 网络针对不同输入的泛化能力
全文总结
本文提出一种基于图卷积的网络框架,从多视角图像生成 3D 网格模型。Pixel2Mesh++ 模型学习如何利用交叉视图信息并迭代地生成顶点变形,以改善直接预测方法(例如:Pixel2Mesh 及其多视图扩展)。
受多视图几何方法启发,本文的模型在每个网格顶点周围的附近区域中搜索最佳位置进行顶点位置变形。与之前的方法相比,本文的模型达到了最先进的性能,所生成的形状包含准确的表面细节,而不仅仅是从输入视角上看似合理,并且在许多方面都具有良好的泛化能力。
参考文献
[1] Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In ICLR, 2016.
[2] Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, Wei Liu, and Yu-Gang Jiang. Pixel2mesh: Generating 3d mesh models from single rgb images. In ECCV, 2018.
[3] Lubor Ladicky, Olivier Saurer, SoHyeon Jeong, Fabio Maninchedda, and Marc Pollefeys. From point clouds to mesh using regression. In Proceedings of the IEEE International Conference on Computer Vision, pages 3893–3902, 2017.
[4] Smith, E. J., Fujimoto, S., Romero, A., & Meger, D. (2019). GEOMetrics: Exploiting Geometric Structure for Graph-Encoded Objects. arXiv preprint arXiv:1901.11461.
[5] Christopher B Choy, Danfei Xu, JunYoung Gwak, Kevin Chen, and Silvio Savarese. 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In ECCV, 2016.
[6] Abhishek Kar, Christian Hane, and Jitendra Malik. Learning a multi-view stereo machine. In Advances in neural information processing systems, pages 365–376, 2017.

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码


