![]()
本文解读的是CVPR2020 接收论文《EfficientDet: Scalable and Efficient Object Detection》,论文作者来自谷歌团队。
作者 | 谷 歌
论文地址:
https://arxiv.org/pdf/1911.09070.pdf
开源地址:https://github.com/google/automl/tree/master/efficientdet
目标检测作为计算机视觉的核心应用之一,在机器人技术、无人驾驶汽车等精度要求高、计算资源有限的场景中变得越来越重要。不幸的是,现有的许多高精度检测器还无法应对这些限制。更重要的是,现实世界中的目标检测应用程序运行在各种平台上,往往需要不同的资源。
由此自然而然要提出的一个问题是,如何设计精确、高效,并且还能够适用于各类存在资源限制问题的场景的目标检测器?
在CVPR 2020 论文《EfficientDet:可扩展、高效的目标检测》中,谷歌研究者们引入了一系列新的可扩展的高效的目标检测器。EfficientDet 基于此前关于可扩展神经网络的一项工作EfficientNet,并结合一种新的双向特征网络BiFPN以及新的扩展规则,在比当前最先进的检测器缩小了9倍以及使用了更少得多的计算量的同时,实现了当前最高的精度。
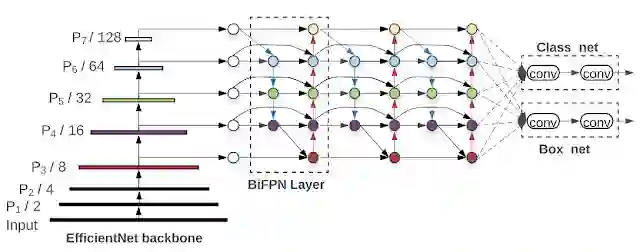
EfficientDet 架构。EfficientDet 使用EfficientNet作为骨干网络,并结合使用了最新提出的BiFPN特征网络。
EfficientDet背后的灵感源自谷歌研究者们通过对现有最先进的检测模型进行系统研究以找到提高计算效率的解决方案的尝试。
一般而言,目标检测器主要由三个部分组成:从给定图像中提取特征的骨干网络;从骨干网络中提取多级特征作为输入并输出一系列表示图像显著特征的融合特征的特征网络;以及使用融合特征预测每个目标的类和位置的最终的类/方框网络。经过验证这些部分的各种设计方式,他们最终确定了提高性能和效率的关键优化。
此前的检测器主要依靠ResNets、ResNeXt或AmoebaNet作为骨干网络,然而这些网络要么功能较弱,要么效率较低。因此一个优化是,通过采用EfficientNet作为骨干网络,以极大地提高效率。例如,从采用ResNet-50作为骨干网络的RetinaNet 基准开始,他们的消融研究表明,近用EfficientNet-B3替代ResNet-50 ,便能够提高3%的精度,与此同时还能减少20%的计算量。
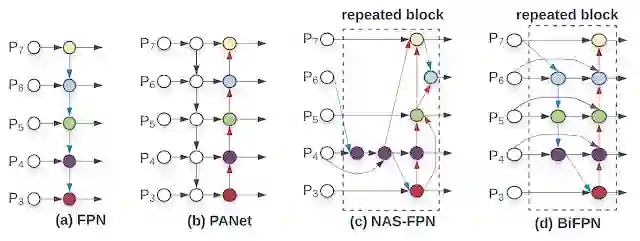
另一个优化是提高特征网络的效率。虽然以往的检测器大多采用自上而下的特征金字塔网络(FPN),但他们发现自上而下的FPN本质上受到单向信息流的限制。可替代FPN的网络 ,比如PANet,添加了一个额外的自下而上的流,往往要以增加计算量为代价。
采用神经架构搜索(NAS)的尝试,则找到了更复杂的NAS-FPN架构。然而,这种网络架构虽然有效,但对于特定的任务来说,也是不规则的、高度优化的,这使得它很难适应其他任务。
为了解决这些问题,他们提出了一种新的双向特征网络 BiFPN,该网络结合了FPN、PANet、NAS-FPN的多级特征融合思想,即使得信息既能够自上而下,也能够自下而上地流动,同时使用规则和高效的连接。
BiFPN 和此前的特征网络的对比。BiFPN 允许特征(从低分辨率的P3层到高分辨率的P7层)既能够自下而上也能够自上而下地反复流动。
为了进一步提高效率,谷歌研究者还提出了一种新的快速归一化融合技术。
传统的方法通常对输入到FPN的所有特征一视同仁,即使对于那些分辨率差别很大的特征亦如是。然而,他们发现不同分辨率下的输入特征对输出特征的贡献往往并不相等。因此,他们为每个输入特征添加一个额外的权重,并让网络了解每个特征的重要性。同时,他们也用更便宜些的
深度可分离卷积
来代替所有的正则卷积。通过这些优化,BiFPN进一步提高了4%的精度,同时降低了50%的计算成本。
第三个优化涉及在不同的资源约束下实现更好的精度和效率权衡。谷歌研究者此前的相关工作已经表明,联合缩放网络的深度、宽度和分辨率,可以显著提高图像识别的效率。
受此启发,他们针对目标检测器提出了一种新的复合缩放方法,它可以联合缩放分辨率、深度和宽度。每个网络部分,即骨干网络、特征网络和边框/类预测网络,都将拥有一个单一的复合缩放因子,该因子使用基于启发式的规则控制所有的缩放维度。这种方法可以通过计算给定目标资源约束的缩放因子,便能够轻易地确定如何缩放模型。
结合新的骨干网络和BiFPN,他们首先创建了一个小尺寸的EfficientDet-D0 基线,然后应用复合缩放法得到了 EfficientDet-D1至D7。每一个连续的模型都要花费较高的计算成本,涉及到每秒浮点运算次数(FLOPS)从30亿次到3000亿次的各类系统资源限制,并且能提供更高的精度。
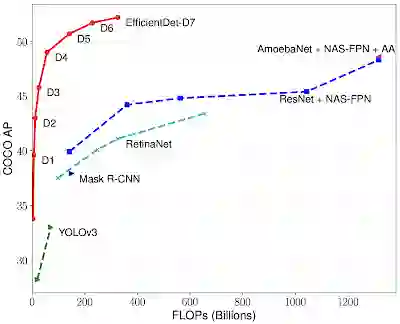
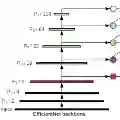
他们在一个广泛用于目标检测的基准数据集——COCO数据集上对EfficientDet 进行了评估。其中,EfficientDet-D7的平均精度(mAP)为52.2,比现有最先进的模型高出1.5个点,同时使用的参数还减少了4倍、计算量减少了9.4倍。
相同设置下,EfficientDet 在COCO 测试集上达到的最佳精度是52.2mAP,比现有最先进的模型高出1.5个点(3045B FLOPs后的精度未展示)。而在同样的精度下,EfficientDet 模型比此前的检测器,大小上减少了4到9倍,计算量上减少了13至42倍。
与此同时,他们还比较了EfficientDet和先前模型在参数大小和CPU/GPU延迟方面的表现。在差不多的精度下,EfficientDet模型在GPU上比其他探测器快2-4倍,在CPU上比其他探测器快5-11倍。
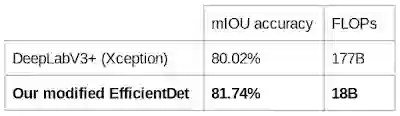
虽然EfficientDet 模型主要是为目标检测而设计的,但谷歌研究者也检验了它们在其他任务(如语义分割)上的性能。为了执行分割任务,他们稍微修改了EfficientDet-D4,将检测头和检测的损失函数替换为分割头和分割的损失函数,同时保留了相同大小的骨干网络和BiFPN。
此模型与在Pascal VOC 2012(一个广泛用于分割基准的数据集)上性能最好的分割模型—— DeepLabV3+ 的比较结果如下:
在没有在COCO数据集上进行预训练的相同设置下, EfficientDet 在Pascal VOC 2012数据集上实现的性能要高于DeepLabV3+ ,其中计算量减少了9.8倍。
基于 EfficientDet的表现,谷歌研究者表示,希望它能够作为未来目标检测相关研究工作的新基石,并且有助于研究者开发出高精度的目标检测模型,更好地服务于更多现实世界的应用。
via
https://ai.googleblog.com/2020/04/efficientdet-towa rds-scalable-and.html
1、ACL 2020 - 复旦大学系列解读
直播主题:不同粒度的抽取式文本摘要系统
主讲人:王丹青、钟鸣
直播时间:4月 25 日,(周六晚) 20:00整。
直播主题:结合词典的中文命名实体识别【ACL 2020 - 复旦大学系列解读之(二)】
主讲人:马若恬, 李孝男
直播时间:4月 26 日,(周日晚) 20:00整。
直播主题:ACL 2020 | 基于对抗样本的依存句法模型鲁棒性分析
【ACL 2020 - 复旦大学系列解读之(三)】
主讲人:曾捷航
直播时间:4月 27 日,(周一晚) 20:00整。
2、ICLR 2020 系列直播
直播主题:ICLR 2020丨Action Semantics Network: Considering the Effects of Actions in Multiagent Systems
主讲人:王维埙
回放链接:http://mooc.yanxishe.com/open/course/793
直播主题:ICLR 2020丨通过负采样从专家数据中学习自我纠正的策略和价值函数
主讲人:罗雨屏
回放链接:http://mooc.yanxishe.com/open/course/802
直播主题:ICLR 2020丨分段线性激活函数塑造了神经网络损失曲面
主讲人:何凤翔
回放链接:http://mooc.yanxishe.com/open/course/801(回放时间:4月25日下午10点)
扫码关注[ AI研习社顶会小助手] 微信号,发送关键字“ICLR 2020+直播” 或 “ACL 2020+直播”,即可进相应直播群,观看直播和获取课程资料。
![]()