IJCAI 2020 | 微软亚洲研究院精选论文摘录

编者按:受疫情影响,2020国际人工智能联合会议 IJCAI 将延期至2021年举办。本届 IJCAI 的审稿堪称史上最严,接收率仅为12.6%,是 IJCAI 史上最低的接收率。微软亚洲研究院今年共入选了18篇论文,本文精选了其中的5篇进行介绍,涵盖强化学习、机器翻译、虚拟机配置、个性化推荐、语音增强等领域的最新成果。
深度强化学习模型表达力的指标研究
I4R: Promoting Deep Reinforcement Learning by the Indicator for Expressive Representations
论文链接:
https://www.researchgate.net/publication/342796344_I4R_Promoting_Deep_Reinforcement_Learning_by_the_Indicator_for_Expressive_Representations
在深度强化学习算法中,深度神经网络作为特征提取器(如图1),其表达能力对算法的表现是很重要的。不同于监督学习,强化学习(RL)任务中的输入通常相似度比较高,细粒度的输入差异对应着不同的动作(Action)(如图2)。因此,强化学习需要表达能力更强的特征提取器。这促使我们研究深度强化学习模型表达力的指标,以及其与强化学习算法的表现之间的关系。
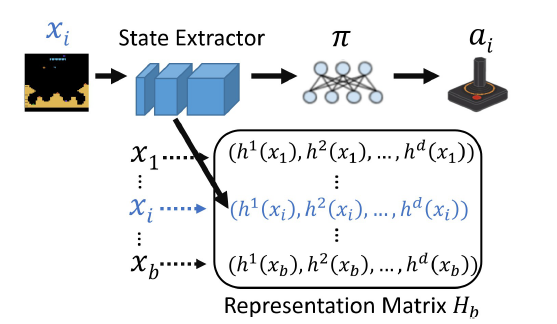
图1:特征提取器及特征矩阵
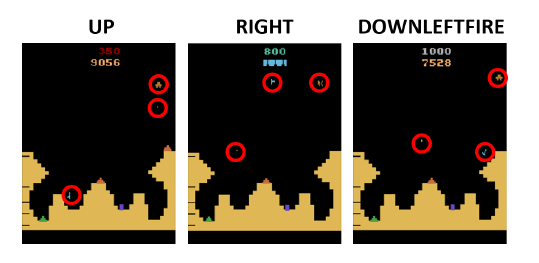
图2:在 Atari 游戏中的原始帧,细粒度的局部差异用红色圆圈标记
首先,我们选择了3个 RL 模型玩 Gravitar 游戏,其中模型1分数最高,模型3分数最低。通过可视化三个模型的特征,如图3所示,分数越高的模型提取的特征越分散。我们进一步观察特征矩阵的特征值分布,如图4所示,分数越高的模型奇异值分布越均匀,而不是集中在少数奇异值上。由此,我们提出强化学习模型表达的指标,称为 NSSV,定义如下:
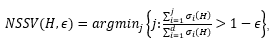
其中 σ_j (H) 代表特征矩阵 H 的第 j 大奇异值。观察了 NSSV 与 Reward 之间的关系后,发现 NSSV 的值与 Reward 的趋势一致(如图5)。
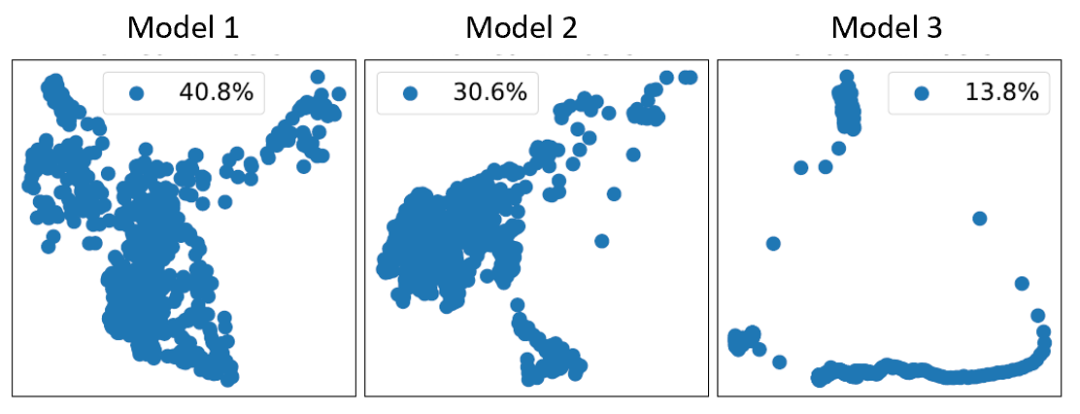
图3:特征的二维可视化
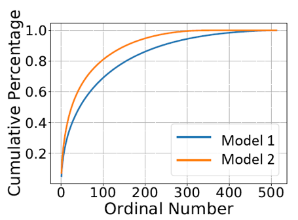
图4:特征矩阵的奇异值分布函数
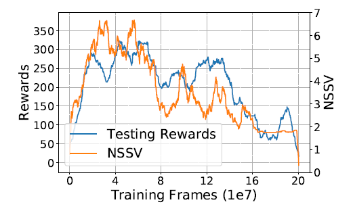
图5:NSSV 和 Reward 曲线
我们进而提出了增强模型表达力的深度强化学习算法(Exp-DRL),即优化以下带正则的损失函数:L=loss-α⋅NSSV(H),其中正则项 NSSV(H) 约束优化过程中的 NSSV 值变大可以增强模型的表达能力。由于 NSSV(H) 无法直接被优化,因此约束 σ_max (H)-σ_min (H) 以及 σ_max (H)/σ_min (H) 来达到约束 NSSV 变大的效果。
我们在 Atari game 上验证了所提出算法的有效性。表1给出了算法 Exp-DQN 和 Exp-A3C 在 Atari game 上的表现。平均来看,它们可以取得更高的分数,并且 Exp-DQN 在20个(共30)游戏中打败了 DQN,Exp-A3C 在48个(共55)游戏中打败了 A3C。图6给出了训练过程中 A3C 和 Exp-A3C 算法的 NSSV 和 Reward 曲线。可以看出 Exp-A3C 有效地增大了 NSSV,并且提升了算法在 Atari game 上的表现。以上实验结果验证了 Exp-DRL 这类算法的有效性。
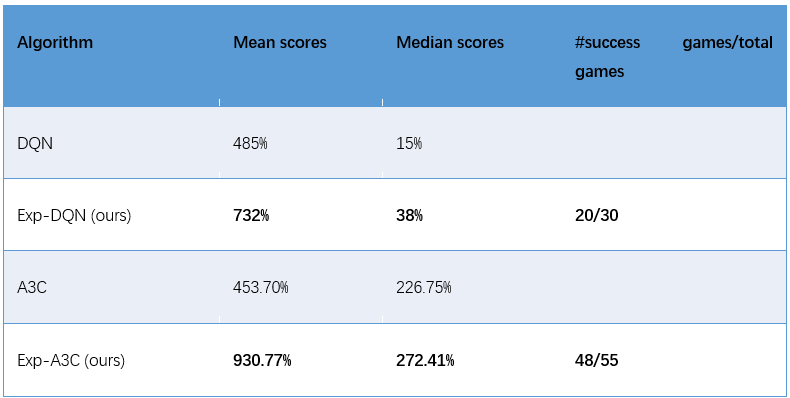
表1:Atari games 上的分数
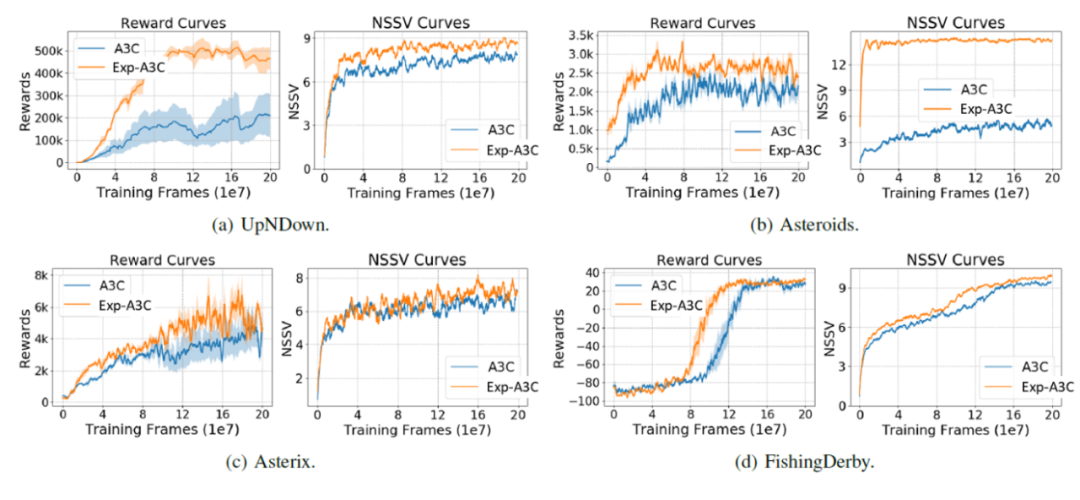
图6:A3C 和 Exp-A3C 算法的 NSSV 和 Reward 曲线
云计算场景中的智能虚拟机配置
Intelligent Virtual Machine Provisioning in Cloud Computing
论文链接:
https://www.microsoft.com/en-us/research/uploads/prod/2020/04/UAHS_IJCAI_2020_updated.pdf
近年来,云计算(Cloud Computing)已经成为一种新的计算范式,并且可以高效地为用户提供多种在线服务。虚拟机配置(Virtual Machine Provisioning)是云计算场景中最为常见且关键的操作。实际上,工业云平台每天都会配置数量众多的虚拟机,但是云平台无法通过简单的配置方案(Provisioning Plan)来高效地利用计算资源。所以,如何设计高效的虚拟机配置方案是云计算场景中至关重要的问题。此外,在实践中从零开始配置虚拟机需要相对较长的时间,而漫长的配置时间会降低用户体验。因此提前配置虚拟机是一个行之有效的解决方案。
本篇论文将以上的应用场景形式化定义为预备虚拟机配置(Predictive Virtual Machine Provisioning, PreVMP)问题。在 PreVMP 问题中,虚拟机的未来配置需求是未知的,因此需要提前预测即将到来的虚拟机配置需求,然后依据预测的结果进行虚拟机配置方案的优化。
PreVMP 问题是典型的预测+优化(Prediction+Optimization)问题。针对预测+优化问题,直观的解决方法是两阶段方法(Two-Stage Method),首先利用历史数据预测未来需求,然后再基于预测的结果优化配置方案。两阶段方法的不足之处在于其假设预测的结果是准确的,然而在实践中预测误差是无法避免的。
为了有效地求解 PreVMP 问题,我们提出了 UAHS 求解方法(Uncertainty-Aware Heuristic Search)。UAHS 包括3个组件:1)超参数选择组件,2)预测组件,3)优化组件。
UAHS 方法的架构如下图所示:1)UAHS 在预测阶段不仅会预测需求,并且会对预测不确定性进行建模;2)UAHS 在优化阶段采用了一种创新的优化算法,该优化算法利用预测不确定性来指导优化的方向;3)UAHS 利用贝叶斯优化方法将预测组件和优化组件进行有效的结合,这样可以有效地提升 UAHS 的实际性能。
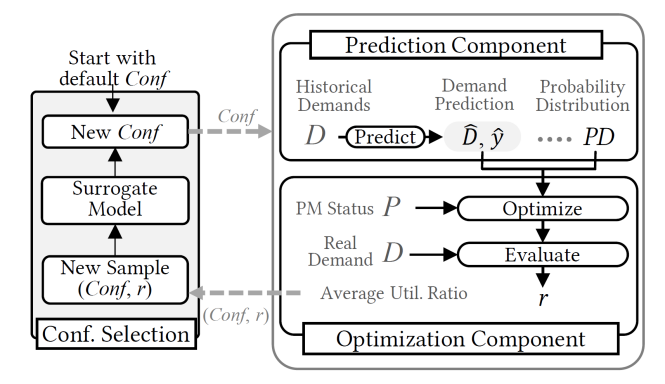
图7:UAHS 方法的架构
我们将 UAHS 方法与多种先进的求解方法进行了实验对比(相关的实验结果可见下表)。实验结果表明,相比较于已有的求解方法,UAHS 展现出了更好的求解性能。
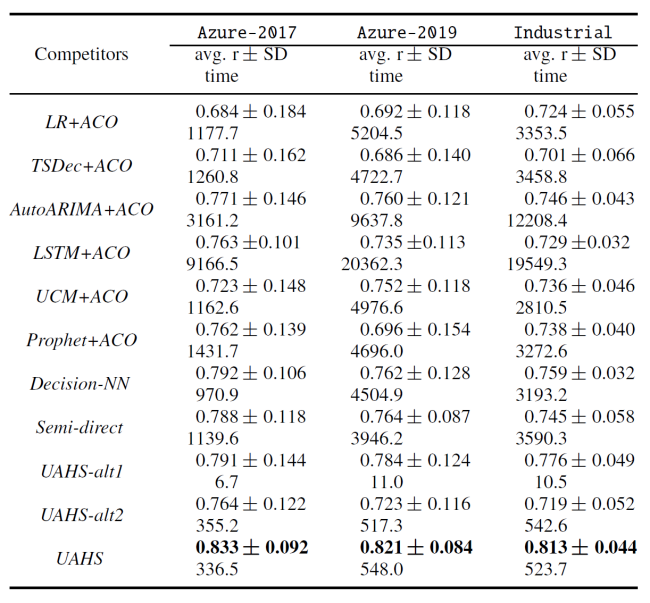
表2:不同方法在求解 PreVMP 上的实际性能对比
UAHS 方法已经被成功应用于微软云平台Azure的预配置服务(Pre-Provisioning Service,PPS)中。Azure 可以通过复用预先配置的虚拟机来极大程度地降低虚拟机配置的时间。在 UAHS 方法部署之后,大约93%符合预配置条件的用户虚拟机配置请求可以复用预先配置的虚拟机,同时虚拟机配置的时间降低了42%。这些结果充分地表明了 UAHS 可以在实际应用中带来性能的提升。
面向非自回归机器翻译的任务级课程学习
Task-Level Curriculum Learning for Non-Autoregressive Neural Machine Translation
论文链接:https://www.ijcai.org/Proceedings/2020/0534.pdf
非自回归翻译(Non-Autoregressive Translation, NAT)通过并行的生成目标语言的句子,能达到非常快的推理速度,但与自回归翻译( Autoregressive Translation, AT)相比,其准确性较差。由于 AT 和 NAT 可以共享模型结构,而 AT 是比 NAT 更容易的任务,因此我们认为可以逐渐将模型训练从较简单的 AT 任务切换到较难的 NAT 任务。
为了平滑地将训练过程从 AT 到 NAT 过渡,在论文中,我们引入了半自回归翻译(Semi-Autoregressive Translation, SAT)作为中间任务。SAT 包含一个超参数 k,每个 k 值定义了具有不同并行度的 SAT 任务。SAT 的极端情况涵盖了 AT 和 NAT:当 k = 1时,它归为 AT;当 k = N 时,它归为 NAT(N 是目标句子的长度)。以 SAT 为中间任务,我们提出了面向 NAT 的任务级课程学习(Task-Level Curriculum Learning)方法(TCL-NAT),它将 k 从1逐渐切换至 N 来逐渐增加模型训练的任务难度,以提升 NAT 的翻译精度。
具体而言,可将训练过程分为三个阶段:AT 训练(k = 1),SAT 训练(1<k<N)和 NAT 训练(k = N)。SAT 训练又包含多个阶段,其中以 k = 2、4、8 ... 的方式逐步地、以指数方式地移动 k。为了更好地切换任务,我们设计了用来控制各个 k 训练步数的规划函数,包括线性,对数和指数函数。另一方面,为了使切换过程平稳并减小不同阶段之间的差距,我们进一步引入了任务窗口 w,该参数表示每个阶段中同时训练的任务数。例如,当 w = 2时,第一阶段 k = 1,2的任务同时训练,第二阶段 k = 2,4的任务同时训练,依此类推。
实验表明,与以前的 NAT 基线相比,TCL-NAT 显着提高了翻译精度,并将 NAT 和 AT 模型之间的性能差距降低到1-2 BLEU,这说明了我们提出的方法的有效性。
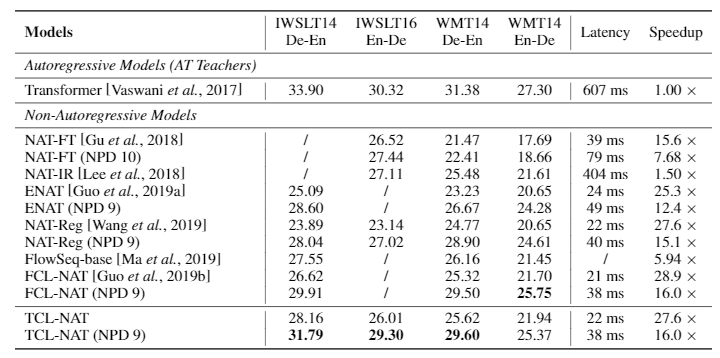
表3:TCL-NAT 同基线模型的 BLEU 分数比较。标注 NPD 9 表示采用有9个候选者的 Noisy Parallel Decoding(NPD),未标注的表示只有一个候选者。
联合训练时频域和时域的语音增强
Time-Frequency and Time Domain Learning for Speech Enhancement
论文链接:https://www.ijcai.org/Proceedings/2020/0528.pdf
单通道语音增强技术的目的是将含有噪声的语音恢复成不包含噪声的语音。主流方法可以分成两类:时频域和时域。时频域方法的优点是可以利用语音和噪声在语谱图中的结构信息,缺点则是预测出的最优语音语谱图并不一定是最优的时域语音。而时域方法无法利用语音和噪声在语谱图中的结构信息,但却没有时频域方法的缺点。
本篇论文提出了一种跨域的方法来充分利用这两类方法的优点。它的特点是从输入的含噪声的时频域信号,端到端可学的预测出不含噪声的时域信号。如图8所示,系统的前半部分与标准的时频域方法一样,对时频域信号进行处理,因而可以利用语音和噪声在语谱图中的结构信息。系统的后半部分类似于时域的方法,首先用一个可学的解码器将时频域信号转换成时域信号,然后与监督信号计算损失函数。这样一个端到端可学的系统就避免了时频域方法的缺点。
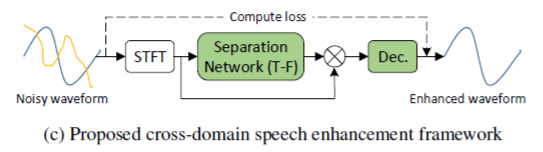
图8:跨域处理方法
此外,论文中还提出了一种注意力机制框架,目的是同时利用语音在频率方向的谐波特性,以及语音在时间上的关联特性。根据不同样本的注意力机制图具有相似性的特点,我们在该注意力机制框架下扩展出一个与样本无关的注意力机制模块,可以进一步降低计算复杂度。具体如下图所示:
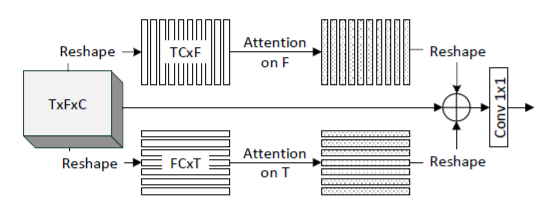
图9:注意力机制框架
实验结果如下,以客观指标作为优化目标,本文的方法在两个数据集上的 SDR 和 SSNR 都高于现有方法。
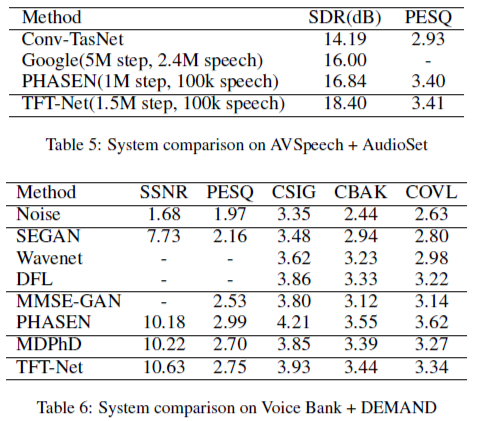
表4:实验结果
可解释对话推荐
Towards Explainable Conversational Recommendation
论文链接:https://www.microsoft.com/en-us/research/uploads/prod/2020/05/ijcai20_camera_ready_conversion.out_.pdf
个性化推荐系统日益成为用户处理线上信息的最有效手段。近年来研究表明,个性化推荐系统的准确性(accuracy)和可解释性(explainability)都是不可或缺的,若系统能在给出切中用户兴趣的商品同时解释其推荐的原因,将会显著提升用户的满意度与信任度。
解释如同用户与推荐系统之间的桥梁,好的解释不但能帮助用户更好的理解推荐系统模型的机理与逻辑,还能够潜在地引导用户向系统反馈自己的意见(例如启发用户在推荐系统给出欠佳的结果或解释时对其进行指正),帮助系统进一步提升准确性。现有的可解释推荐系统往往忽视了后者,只给出一次推荐结果及解释,无法对用户可能的反馈加以吸纳。
因此我们提出了可解释对话推荐(explainable conversational recommendation)任务,系统籍由解释引导用户反馈,并进行整合、吸收,产生新的结果,以系统-用户对话的形式迭代地提升推荐和解释效果(如图10、11所示)。相比于现有的对话推荐模型设计问题收集用户答案的方式,可解释对话推荐用户自主反馈的方式不仅能保证模型的可解释性,也为用户减轻负担,更加友好。

图10:可解释对话推荐示例
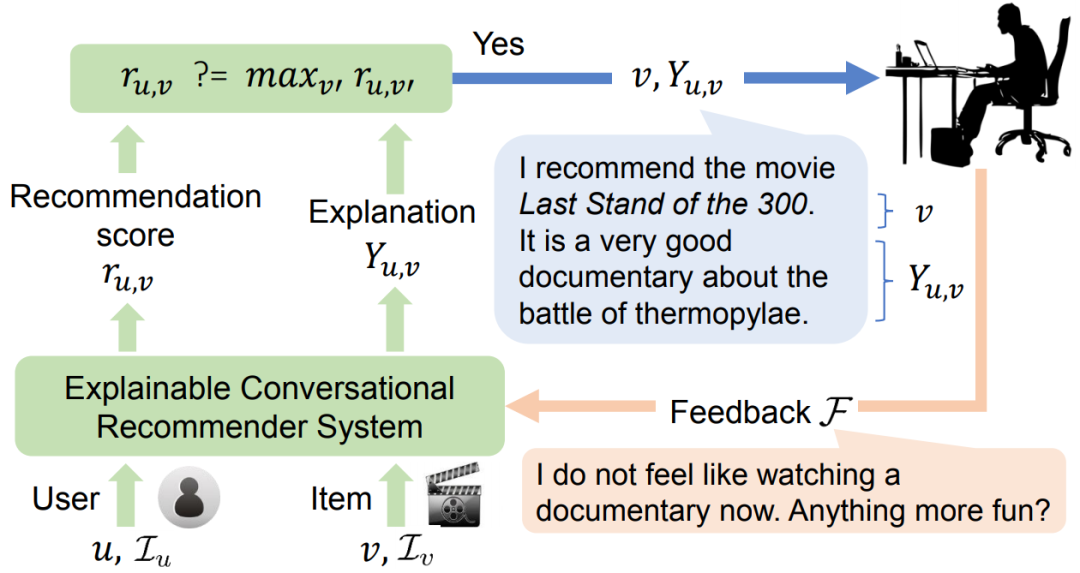
图11:可解释对话推荐流程
可解释对话推荐的目标不只是随用户反馈的增加高效稳定地提升推荐的准确性及可解释性(泛化能力,generalization),更要尽可能充分、及时地满足用户的反馈意见(满意度, satisfaction)。因此我们提出了基于增量多任务学习架构的可解释对话推荐(ECR)模型(如图12所示)。该模型通过对概念词(concept)的表示来学习关于建模推荐与解释任务的交叉知识,将推荐预测、解释生成以及用户反馈整合模块紧密结合,从而共同学习,逐步提升模型效果,达到各个设计目标。
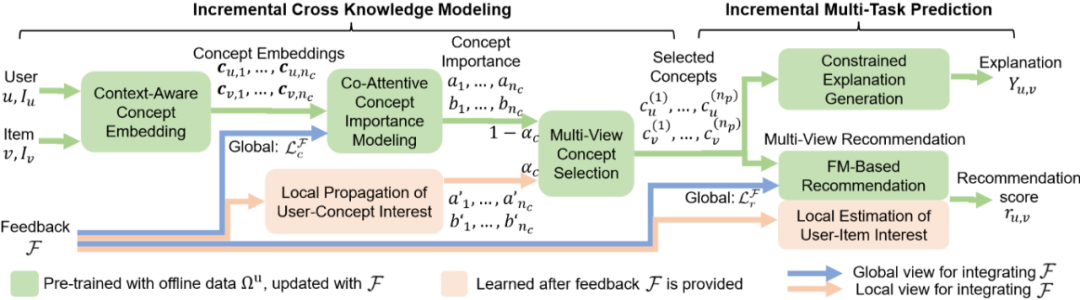
图12:ECR 模型的增量多任务学习架构
在整合用户反馈时,我们提出了一种多视角的方法使模型的增量更新过程更加有效。其中第一个视角从泛化能力出发,通过更新模型的全局(global)参数吸收用户反馈,降低误差;第二个视角从用户满意度出发,以局部传播(local propagation)的方式更直接地满足用户的反馈意见。
我们在 Amazon Electronics、Movies&TV、Yelp 三个数据集上模拟用户反馈进行了充分实验。实验结果显示提出的可解释对话推荐模型在推荐准确性、可解释性以及用户反馈满足比例上均明显优于基准算法,达到了系统设计的各个目标。

表5:模型在不同数据集上的实验结果
你也许还想看:







