字节跳动 | AMBERT:一种多粒度Tokenization的预训练语言模型

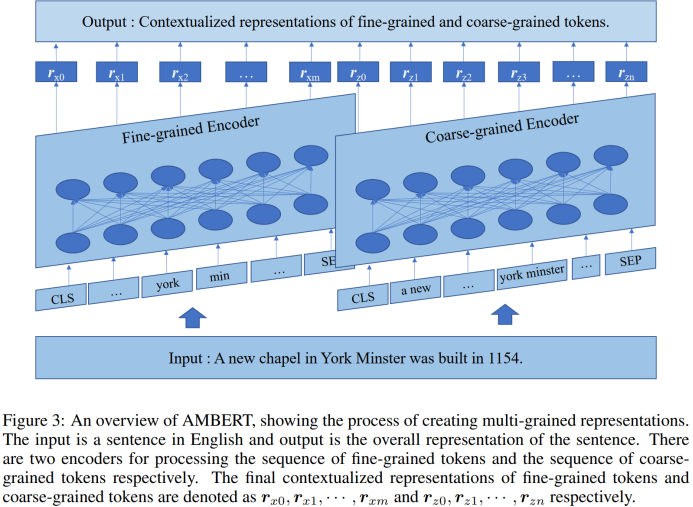
预训练
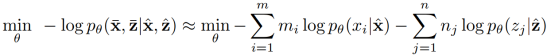
微调
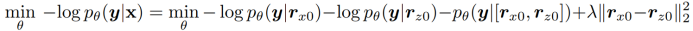
AMBERT-Combo:
AMBERT-Hybrid:
用单个encoder而不是两个encoder去同时编码两种粒度的句子,也就是把粗细粒度的句子先拼接起来再送到BERT里,这就会让自注意力在不同粒度的句子中进行交互。
数据说明
中文预训练数据集使用一个包含2500万文档(57G未压缩文本))的今日头条语料库(估计不会公开的,sad+1)。英文预训练数据集则来自Wikipedia和OpenWebText的1390万文档(47G未压缩文本)的语料库。对于中文,粗细粒度分别是词和字,在CLUE上进行评测。分词工具则是字节跳动内部开发的分词工具(估计也不会开源了sad+10086)。这两种token的生成过程都利用了WordPiece技术,最终产生的中文词典分别包含21128个字和72635个词。对于英文,粗细粒度分别短语和词。英文单词是天然的细粒度token,至于粗粒度是先利用KenLM构建n-gram,用频率足够高的短语构建短语级别的字典,这些短语的最后一个单词高度依赖于其前置单词。最后利用贪心算法对文本进行短语级切分,得到30522个单词和77645个短语。英文评测任务是在GLUE上进行的,此外还在英文阅读理解数据集SQuAD和RACE进行进一步实验。
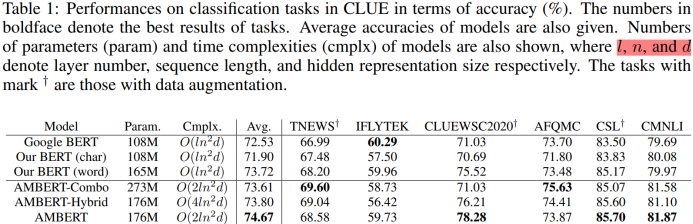
中文CLUE上的实验结果如Table 1和Table 2所示。从实验结果看,AMBERT在CLUE上确实一枝独秀,在其中4个任务上取得最优结果,但在WSC和CMRC数据集上与最优结果存在较大差距,特别是CMRC数据集上堪称大型翻车现场(3个百分点的差距)。
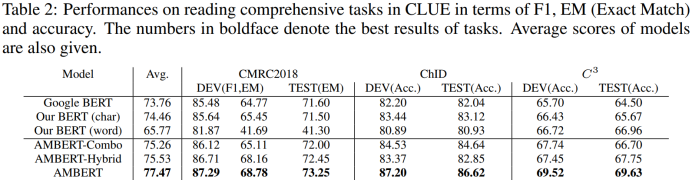
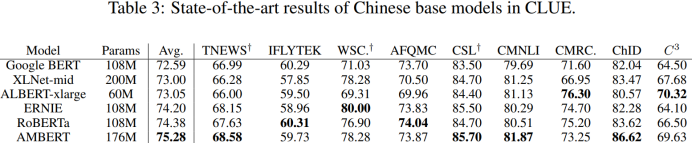
实验结果:英文数据集
Table 4和Table 6是AMBERT在GLUE上的实验结果。在多数数据集上AMBERT要优于其他baseline模型,且多粒度的效果确实好于单粒度。但是如果放到更大范围的模型比较,AMBERT整体上逊色于RoBERTa,但是优于其他模型。另外,从机器阅读理解数据集的对比结果Table 5可以看出,在SQuAD上AMBERT大大优于Google官方的BERT,而在检测span任务中,单词级的BERT通常表现良好,短语级BERT较差。另外,在RACE的dev set 和 test set上,AMBERT发挥稳定,全场最佳。
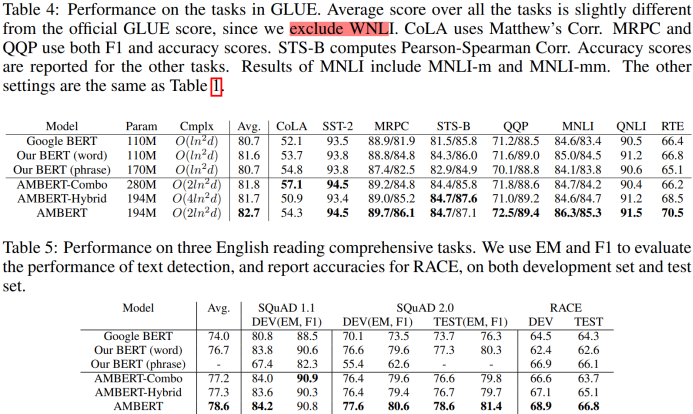
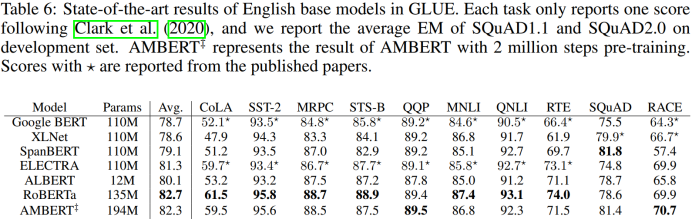
文章提出多粒度的预训练模型AMBERT,联合使用粗细粒度的语言单元对句子进行切分,从而充分利用二者各自的优势。在中文和英文的自然语言理解任务上证明该模型的有效性,尤其是对中文而言提升效果更加显著。但是,在中文数据集上的比较上有几个不足:
(1) 中文的分词工具属于字节跳动内部,尚未开源。
(2) 更重要的是,预训练的数据集也是字节跳动内部的数据集,而不是通常中文预训练使用的中文维基百科语料。作者自己也一再强调,只能作为参考。
(3) 预训练模型包含代码和模型均没有发布。
基于现况,如此就在CLUE上其他模型比较,似乎有失公允。到底是分词、数据、还是模型优势?虽然作者也一直在强调,对比仅仅作为参考,仅作为参考,作为参考,为参考,参考。。。但是,作为一个既没有开放源码也没有发布预训练模型的预训练语言模型,应该是第一个吧,所以各相关从业人员于此颇有微词。未来或许可期,先让子弹飞一会,让我们拭目以待。




登录查看更多
相关内容
专知会员服务
64+阅读 · 2020年4月28日
专知会员服务
21+阅读 · 2019年12月12日
Arxiv
15+阅读 · 2018年10月11日


相关VIP内容
专知会员服务
64+阅读 · 2020年4月28日
专知会员服务
21+阅读 · 2019年12月12日
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日