从ACL 2020和ICLR 2020看知识图谱嵌入的近期研究进展

©PaperWeekly 原创 · 作者|舒意恒
学校|南京大学硕士生
研究方向|知识图谱
本文介绍三篇发表于 ACL 2020 或 ICLR 2020 关于知识图谱嵌入的近期研究进展。
1. ACL 2020 | A Relational Memory-based Embedding Model for Triple Classification and Search Personalization 用于三元组分类和搜索个性化的基于关系记忆的嵌入模型
2. ACL 2020 | A Re-evaluation of Knowledge Graph Completion Methods 知识图谱补全方法的重新评估
3. ICLR 2020 | You Can Teach An Old Dog New Tricks! On Training Knowledge Graph Embeddings 旧瓶装新酒,训练知识图谱嵌入
其中,第 1 篇文章主要使用序列模型对三元组进行建模,用于三元组分类和搜索个性化任务。第 2 篇和第 3 篇文章是实证类的研究,回顾了现有的知识图谱嵌入方法,并从独特的角度提出了质疑,对研究者在今后的研究具有一定启发意义。


论文标题:A Relational Memory-based Embedding Model for Triple Classification and Search Personalization
论文作者:Dai Quoc Nguyen, Tu Dinh Nguyen, Dinh Phung
论文来源:ACL 2020
论文链接:http://arxiv.org/abs/1907.06080
开源代码:https://github.com/daiquocnguyen/R-MeN
本文关键词:knowledge graph embedding; relational memory-based; triple classification; search personalization

1.1 问题
作者认为,现有的知识图谱嵌入方法通常在记忆有效三元组方面有局限。
作者主要面向的应用场景是搜索个性化和三元组分类:三元组分类旨在预测给定的三元组是否有效;搜索个性化旨在对面向用户的搜索引擎返回的相关文档进行重新排序。
作者将其嵌入模型称为 R-MeN,它使用一个关系记忆网络来编码三元组,推断新的三元组。
具体而言,R-MeN 将每个三元组与额外的位置嵌入(positional embedding)一起转换成 3 个输入向量序列。然后,R-MeN 使用 transformer 的自注意力(self-attention)机制来引导记忆与每个输入向量进行交互,以产生一个编码向量。
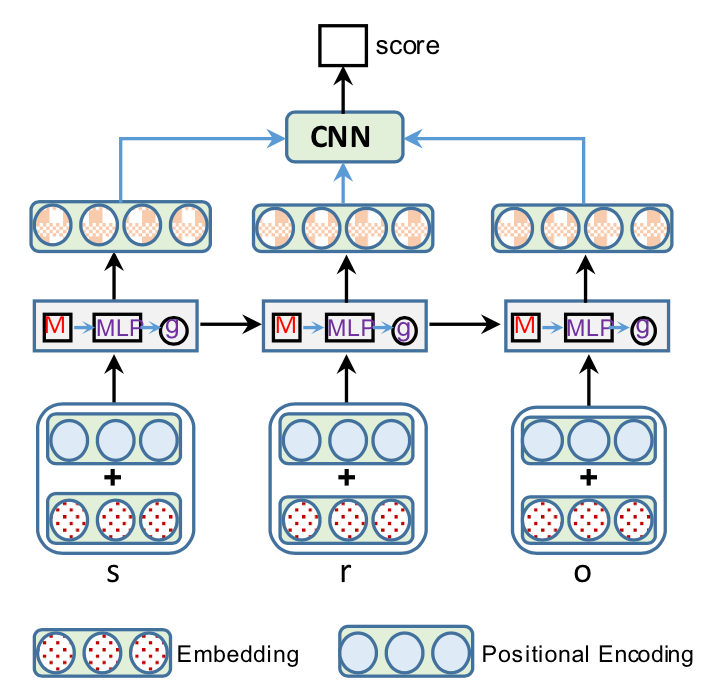
1.3.1 位置嵌入
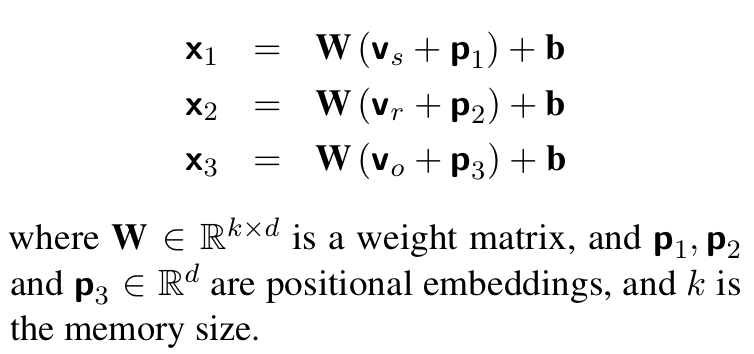
1.3.2 记忆
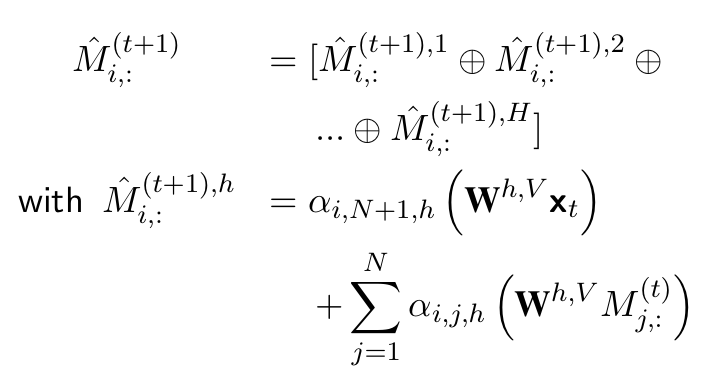


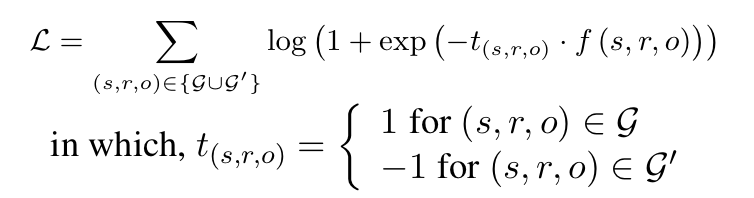
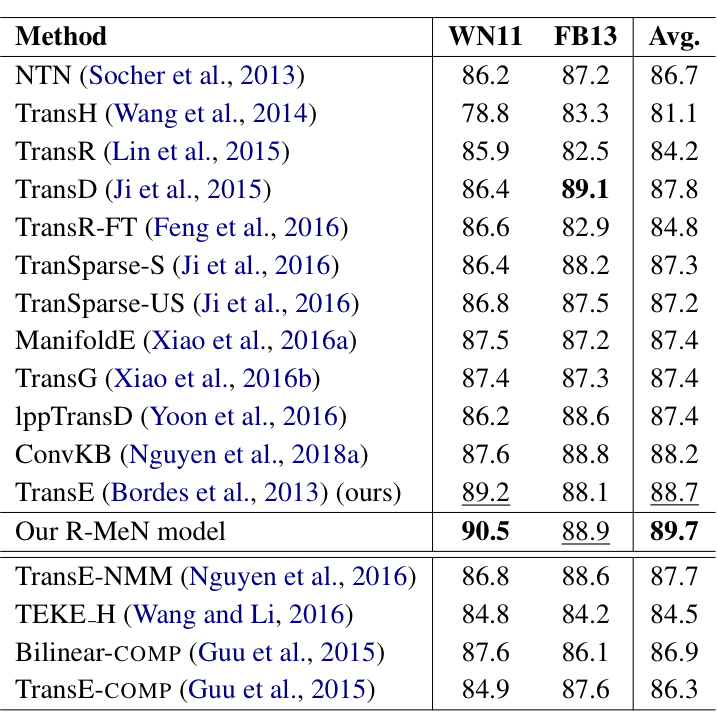
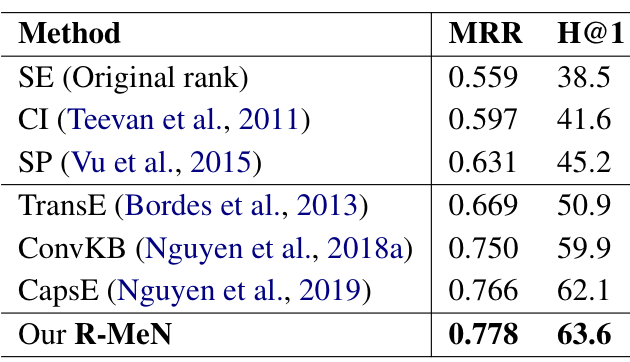
1.4 实验
作者在两个任务上使用了三个数据集:
-
三元组分类:WN11 和 FB13 -
搜索个性化:SEARCH17
1.4.3 消融实验
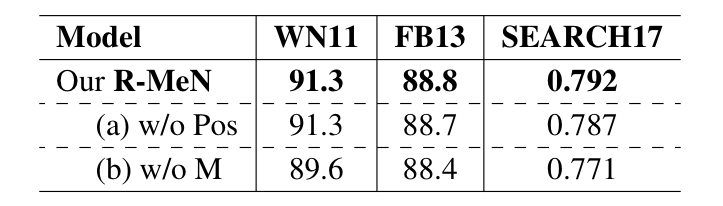
R-MeN 基于 transformer 的自注意力机制,以 CNN 为解码器的记忆交互的形式对知识图谱学习嵌入。本文的主要贡献在于假设三元组的三个元素的相对位置信息对于三元组分类问题是有效的,并且通过序列建模取得了好的效果。


论文标题:A Re-evaluation of Knowledge Graph Completion Methods
论文作者:Zhiqing Sun,Shikhar Vashishth,Soumya Sanyal,Partha Talukdar,Yiming Yang
论文来源:ACL 2020
论文链接:http://arxiv.org/abs/1911.03903
开源代码:http://github.com/svjan5/kg-reeval
本文关键词:evaluation; knowledge graph completion

2.1 知识图谱补全简介
真实世界的知识图谱通常是不完整的,启发研究者探索自动补全知识图谱的方法。一种常见方法是将知识图谱的实体和关系嵌入连续向量或矩阵空间中,并使用设计好的评分函数度量一个三元组的可能性。
现有方法可以大致分为基于平移距离的 (translation distance) 方法和语义匹配 (semantic matching) 的方法,一部分基于神经网络的方法也被提出,如使用 CNN [2-3]、RNN [4-5]、GNN [6-7]、Capsule Network [8] 等。
2.2 观察
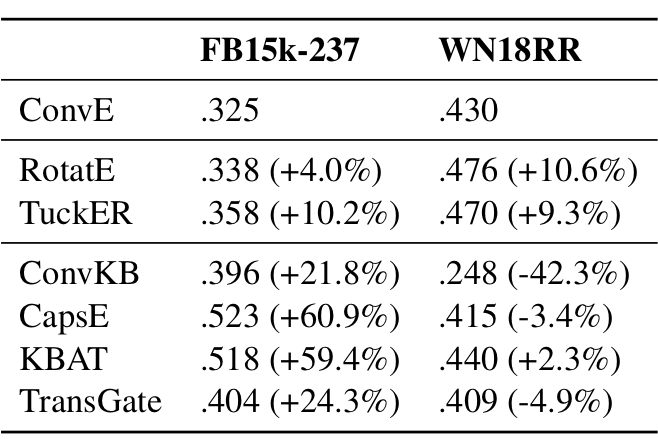
2.2.2 对评分函数的观察
三元组评分函数的不合理主要体现在:有效三元组和无效三元组分数的分布差异。
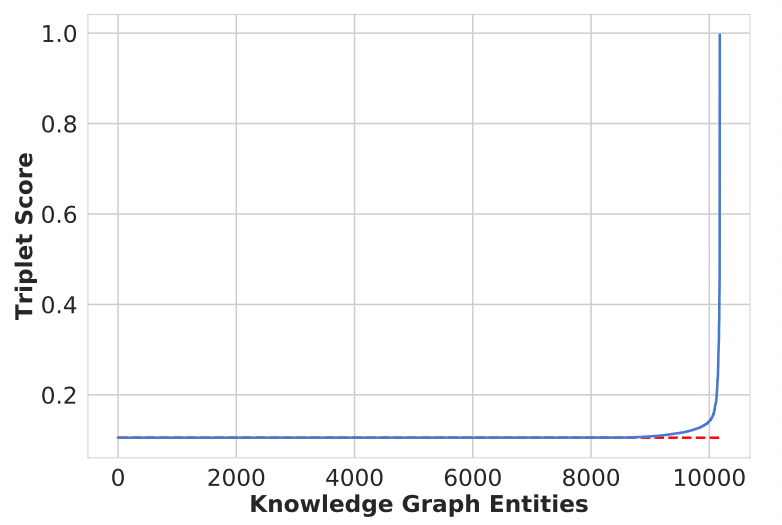
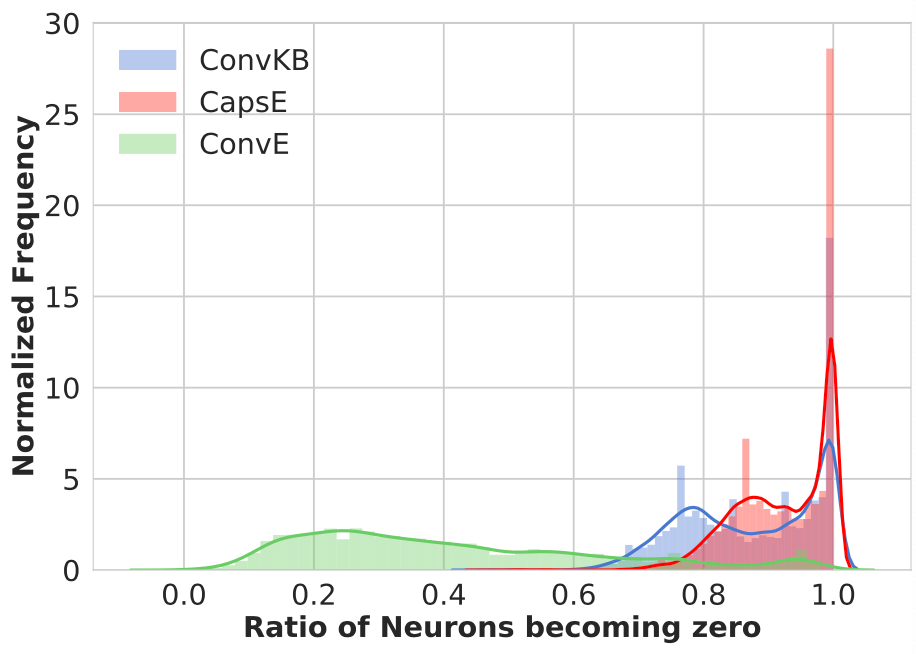
作者对不同方法使用的 ReLU 激活函数进行深入研究,发现对于 FB15k-237 数据集,大量神经元在 ReLU 激活函数之后变为 0. 因此,一些三元组表示在前向传播中变得非常相似,导致了相同的分数。
2.3 知识图谱补全的评估准则
作者提出了新的评估准则 (protocol),并证明不合理的评估准则是基于神经网络的嵌入方法表现异常的关键原因。
作者提出评估准则的出发点基于他们的观察,即打破三元组在同一分数上的大量重复。作者没有尝试对不同补全方法的评分函数的原理分析,或者是从如何改进 ReLU 激活函数的表现进行分析,而是从评估准则和三元组分数之间的关系进行分析。
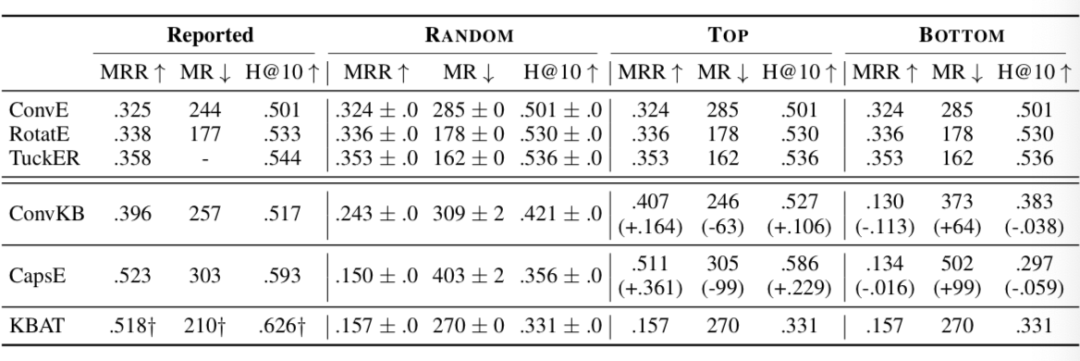
-
TOP:正确的三元组插入到 的头部 -
BOTTOM:正确的三元组插入到 的尾部 -
RANDOM:正确的三元组随机插入到 中的一个位置
2.4 实验
数据集使用 FB15k 的子集 FB15k-237,逆关系被删除防止测试时直接从训练三元组推断。
作者将分析的模型分为两类:未受影响的和受影响的,即在不同评估准则下表现一致的模型和表现不一致的模型。
评估的指标包括:MRR(mean reciprocal rank)、MR(mean rank)和 Hit@10(H@10).
作者表示,ConvE、RotatE 和 TuckER 的原论文使用的是 RANDOM,而 ConvKB、CapsE 和 KBAT 使用的是 TOP.
个人认为,NLP 社区应当鼓励质疑类的工作和无效探索的工作,除了了解什么样的方法是有作用的,研究者能了解什么样的方法是无效的也很重要。
本文的主要贡献在于,发现了不恰当的评估准则的使用导致模型的性能被夸大。但作者提出的疑惑并没有完全被解决,我想我们还可以进一步追问以下问题:
三元组分数重复程度严重,是否表示评分函数对三元组的区分能力有待加强?
-
ReLU 激活之后,许多神经元变为 0,是因为 ReLU 这个函数的不合理,还是因为神经网络结构的不合理?



这篇文章是一篇实证角度的综述。文章标题的所谓「旧瓶装新酒」,这篇文章的「旧瓶」是什么,「新酒」又是什么呢?
作者认为,不同的嵌入方法包含不同的模型架构、训练策略和超参数优化方法。作者的目标是总结和量化这些维度对模型性能的影响。
所谓「旧瓶」是现有的模型架构,「新酒」是作者实验的训练方法,包括损失函数、负样本、正则化方法、优化方法等。作者发现,对已有模型架构使用更先进的技术进行训练,可以表现出更强的性能。
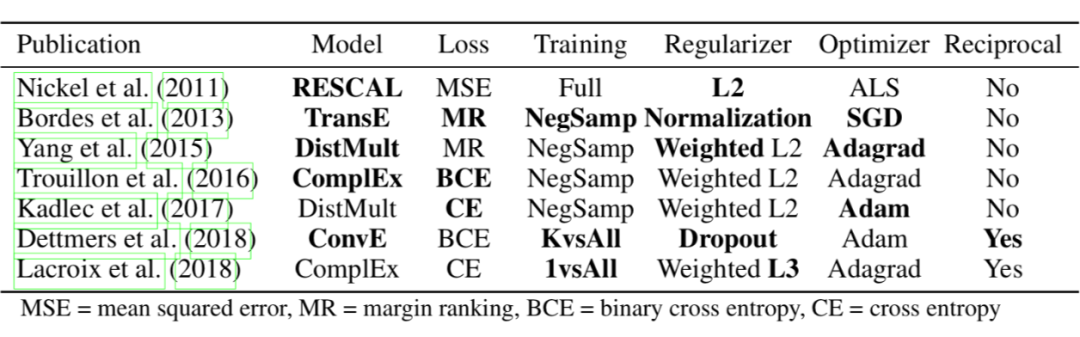
作者总结了知识图谱嵌入模型和训练策略,粗体表示首次使用某种策略的文献。
3.1 嵌入模型
3.1.1 训练类型
作者根据负样本的生成方法,将训练类型分为三类:
NegSamp:对每个正样本随机打乱三元组中的 subject/relation/object 的位置,可选地验证这样的三元组是否已存在于图中。
-
1vsAll:忽略采样,将所有打乱(即使存在于图中) subject 和 object 位置的三元组作为负样本,比 NegSamp 代价更高,但如果实体数量有限是可以接受的。 -
KvsAll:从非空的行 (i, k, *) 或 (*, k, j),而不是单个三元组,构建 batch。存在于训练数据中的标为正样本,否则为负样本。
3.1.2 损失函数
-
三元组分数与标签(正或负)之间的均方差 -
TransE 使用的 hinge loss -
binary cross entropy [9] -
cross entropy [10]
3.1.3 对等关系
L2 正则化是嵌入模型中最常见的正则化方法,可能是非加权的,或按实体/关系频率进行加权的归一化。
Lacroix 等人提出了 L3 正则化。
TransE 在每次更新后将嵌入归一化为 unit norm.
ConvE 在隐藏层中使用了 dropout。
除现有研究的方法之外,作者还考虑了 L1 正则化,和对实体/关系嵌入使用 dropout。
3.1.5 超参数
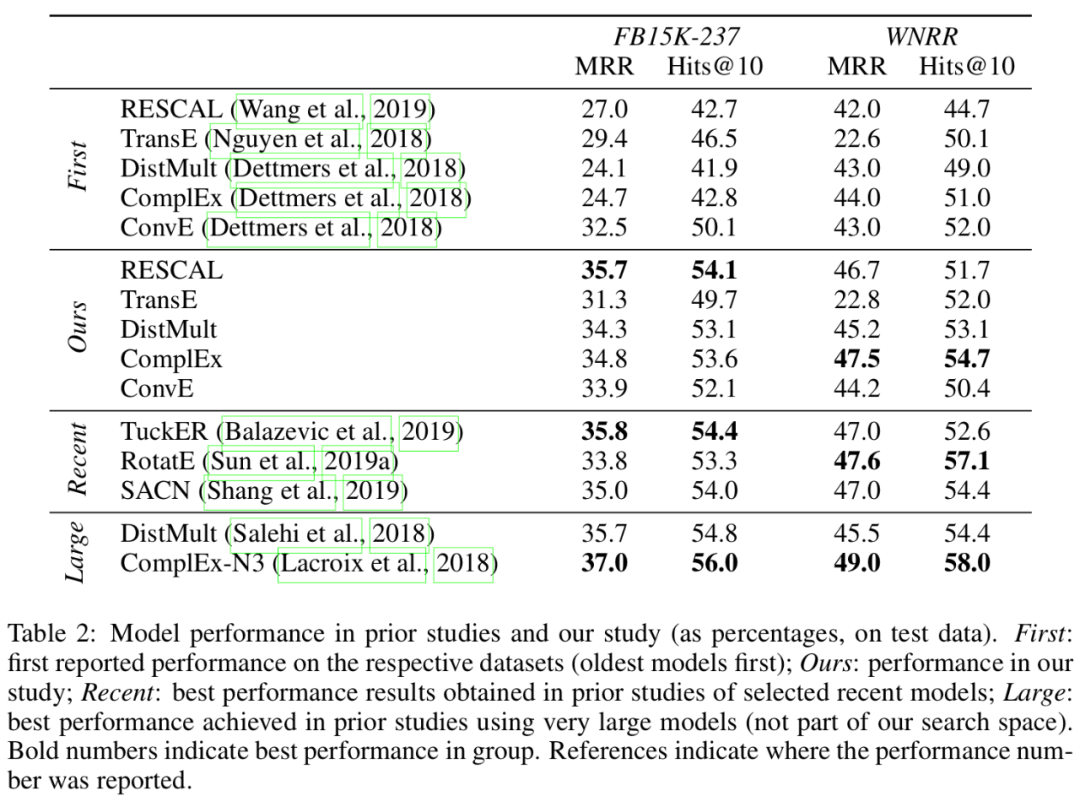

从这篇文章可以见到,关于嵌入的文章创新方向不同,但某种新的训练方法可能只在新的模型上尝试,而不是对大量的其他模型进行尝试。有时我们需要重新审视,一篇新文章的新模型,其关键优势到底是什么?能为其他工作带来多少借鉴。

三篇文章小结
知识图谱嵌入这一话题,延续之前的热度,仍然在今年的顶级会议/期刊上出现了优秀的成果。关于第 1 篇文章,再次验证了知识图谱与自然语言处理之间紧密的关系。知识图谱三元组,通过自然语言表述,在利用一些序列模型时,能在三元组分类上取得较好效果。
参考文献

点击以下标题查看更多往期内容:

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





