用了那么久的Lombok,你知道它的原理么?

序言
知识点
-
Java编译过程 -
了解Lombok原理 -
了解插入式注解处理器
分析
Java编译器是如何解析Java源代码的?
编译器编译源代码都有哪些步骤?
我们在编译器工作的时候,怎么才能去增加内容或者是进行代码分析?
回答
如何解析源代码
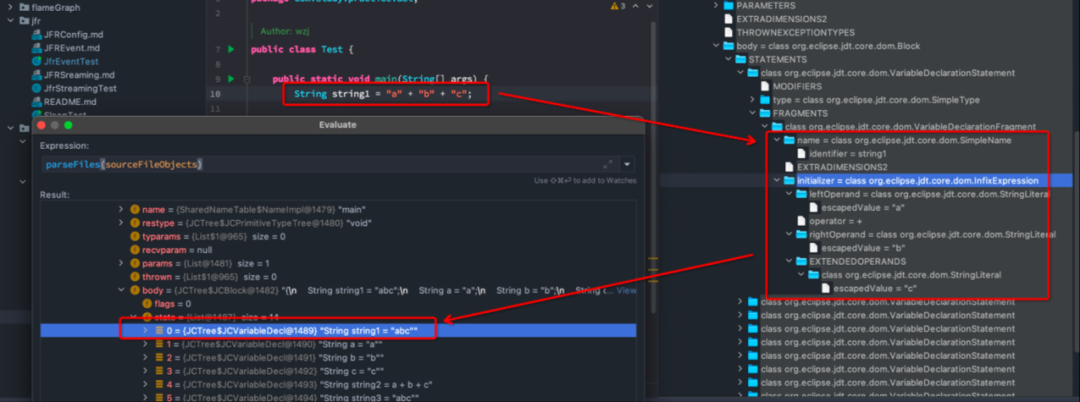
代码编译都有哪些步骤
整个编译过程大致如下:

图片来自openjdk
1.初始化插入注解处理器
2.解析与填充符号表过程
a.词法分析、语法分析。将源代码的字符流转变为标记集合,构造出抽象语法树。
b.填充符号表。产生符号地址和符号信息。
3.插入式注解处理器的注解处理过程:插入式注解处理器的执行阶段。后面我会给大家带来两个此方面的实用实战例子。
4.分析与字节码生成过程
我们知道了上面的理论之后,接下来我们进行实战。带着大家一起去修改AST(抽象树)。添加自己的代码。
实战
如何自己实现一个自动添加Setter/Getter的工具
首先,我们创建一个自己的注解。
// 注解只在源码中保留// 用于修饰类public MySetterGetter {}
创建一个需要生成setter/getter方法的实体类
// 打上我们的注解public class Test {private String wzj;}
接下来就来看一看如何来生成我们想要的字符串。
整体代码如下:
("com.study.practice.nameChecker.MySetterGetter")(SourceVersion.RELEASE_8)public class MySetterGetterProcessor extends AbstractProcessor {// 主要是输出信息private Messager messager;private JavacTrees javacTrees;private TreeMaker treeMaker;private Names names;public synchronized void init(ProcessingEnvironment processingEnv) {super.init(processingEnv);this.messager = processingEnv.getMessager();this.javacTrees = JavacTrees.instance(processingEnv);Context context = ((JavacProcessingEnvironment)processingEnv).getContext();this.treeMaker = TreeMaker.instance(context);this.names = Names.instance(context);}public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {// 拿到被注解标注的所有的类Set<? extends Element> elementsAnnotatedWith = roundEnv.getElementsAnnotatedWith(MySetterGetter.class);elementsAnnotatedWith.forEach(element -> {// 得到类的抽象树结构JCTree tree = javacTrees.getTree(element);// 遍历类,对类进行修改tree.accept(new TreeTranslator(){public void visitClassDef(JCTree.JCClassDecl jcClassDecl) {List<JCTree.JCVariableDecl> jcVariableDeclList = List.nil();// 在抽象树中找出所有的变量for(JCTree jcTree: jcClassDecl.defs){if (jcTree.getKind().equals(Tree.Kind.VARIABLE)){JCTree.JCVariableDecl jcVariableDecl = (JCTree.JCVariableDecl)jcTree;jcVariableDeclList = jcVariableDeclList.append(jcVariableDecl);}}// 对于变量进行生成方法的操作for (JCTree.JCVariableDecl jcVariableDecl : jcVariableDeclList) {messager.printMessage(Diagnostic.Kind.NOTE, jcVariableDecl.getName() + " has been processed");jcClassDecl.defs = jcClassDecl.defs.prepend(makeSetterMethodDecl(jcVariableDecl));jcClassDecl.defs = jcClassDecl.defs.prepend(makeGetterMethodDecl(jcVariableDecl));}// 生成返回对象JCTree.JCExpression methodType = treeMaker.Type(new Type.JCVoidType());return treeMaker.MethodDef(treeMaker.Modifiers(Flags.PUBLIC), getNewSetterMethodName(jcVariableDecl.getName()), methodType, List.nil(), parameters, List.nil(), block, null);}/*** 生成 getter 方法* @param jcVariableDecl* @return*/private JCTree.JCMethodDecl makeGetterMethodDecl(JCTree.JCVariableDecl jcVariableDecl){ListBuffer<JCTree.JCStatement> statements = new ListBuffer<>();// 生成表达式JCTree.JCReturn aReturn = treeMaker.Return(treeMaker.Ident(jcVariableDecl.getName()));statements.append(aReturn);JCTree.JCBlock block = treeMaker.Block(0, statements.toList());// 无入参// 生成返回对象JCTree.JCExpression returnType = treeMaker.Type(jcVariableDecl.getType().type);return treeMaker.MethodDef(treeMaker.Modifiers(Flags.PUBLIC), getNewGetterMethodName(jcVariableDecl.getName()), returnType, List.nil(), List.nil(), List.nil(), block, null);}/*** 拼装Setter方法名称字符串* @param name* @return*/private Name getNewSetterMethodName(Name name) {String s = name.toString();return names.fromString("set" + s.substring(0,1).toUpperCase() + s.substring(1, name.length()));}/*** 拼装 Getter 方法名称的字符串* @param name* @return*/private Name getNewGetterMethodName(Name name) {String s = name.toString();return names.fromString("get" + s.substring(0,1).toUpperCase() + s.substring(1, name.length()));}/*** 生成表达式* @param lhs* @param rhs* @return*/private JCTree.JCExpressionStatement makeAssignment(JCTree.JCExpression lhs, JCTree.JCExpression rhs) {return treeMaker.Exec(treeMaker.Assign(lhs, rhs));}}
代码有点多,我们逐一拆解说明:
下面这是整个代码结构的脑图,后面的讲解会基于这个顺序。
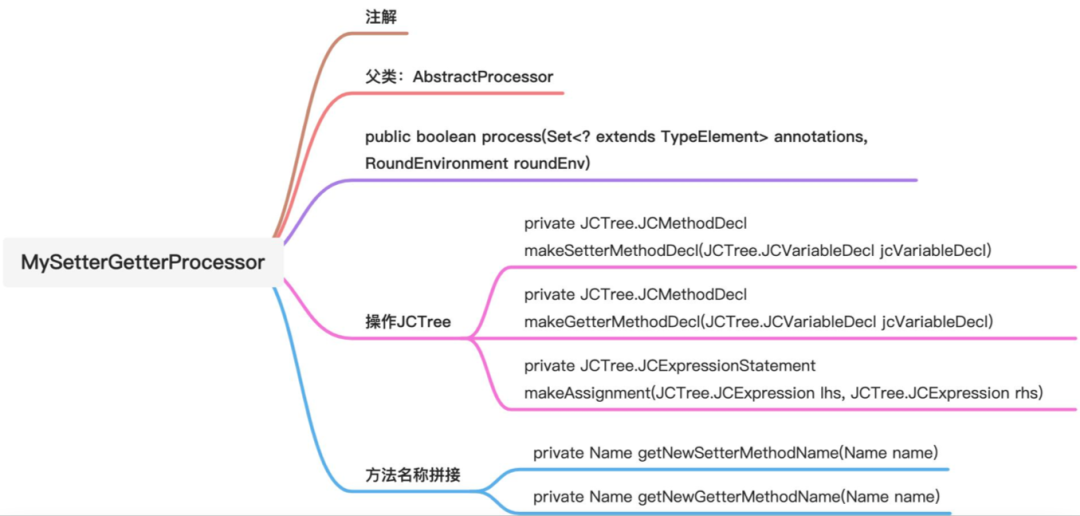
a. 注解
b. 父类
AbstractProcessor是本次的核心类,编译器在编译的时候会扫描此类的子类。其中有一个子类必须实现的核心方法 public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv),此方法如果是返回为true就说明编译的那个类抽象树的结构又变化,需要重新进行词法分析和语法分析(可以查看上面提到的那个编译流程图)。如果返回的是false就说明没有变化。
c. process方法
主要的操作逻辑是:
1.拿到所有被我们MySetterGetter标注的类。
2.遍历所有的类,生成类的抽象树结构。
3.对类进行操作:
4.返回 true,说明类结构变了,需要重新解析。如果是false说明没有变,不用重新解析。
d. 操作JCTree树
主要是在操作抽象树,可以查看文末附件中的文章进行学习。
这一块儿和字符串拼接没啥区别,用过反射的同学应该也都清楚这个操作了。
到此为止,我们就已经介绍完了Lombok的原理。怎么样是不是很简单。接下来,就让我们把它运行起来,投入到实战之中。
f. 运行
最后来看一下如何正确的运行这个我们写的工具。
1. 环境
我的系统环境是 macOs Monterey;
java版本是
openjdk version "1.8.0_302"OpenJDK Runtime Environment (Temurin)(build 1.8.0_302-b08)OpenJDK 64-Bit Server VM (Temurin)(build 25.302-b08, mixed mode)
2. 编译processor
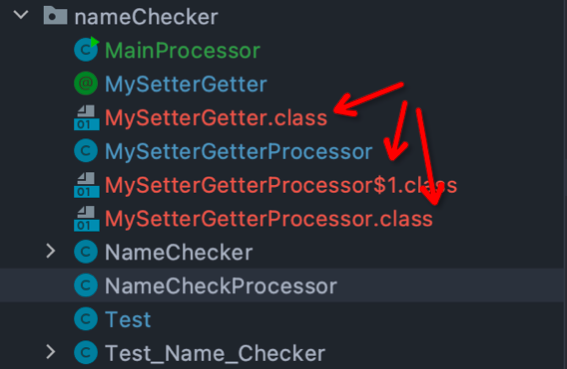
在你存放 MySetterGetter 和 MySetterGetterProcessor 两个类的目录下进行编译。
javac -cp $JAVA_HOME/lib/tools.jar MySetterGetter.java MySetterGetterProcessor.java执行成功后会出现这三个class文件。
3. 声明插入式注解处理器
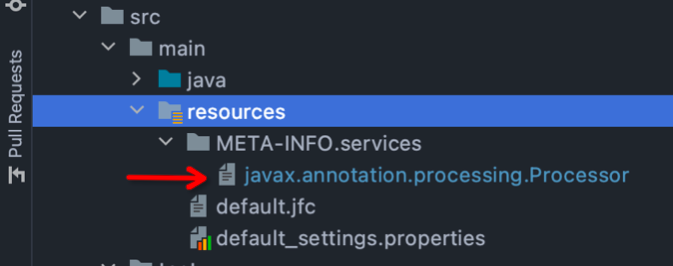
1.在你的工程的resources下面创建一个包,名称为:META-INFO.services
2.然后创建一个文件,名称为:javax.annotation.processing.Processor
4. 用我们的工具去编译目标类
比如我们本次是要编译那个test.java。
它的内容再回顾一下:
// 打上我们的注解public class Test {private String wzj;}
然后我们就去编译它(注意类前面的路径。这个你们得换成自己的工程目录。)
javac -processor com.study.practice.nameChecker.MySetterGetterProcessor com/study/practice/nameChecker/Test.java执行之后如果没有修改我的代码的话会打印这几个字符串:
process 1process 2: wzj has been processedprocess 1
最后会生成Test.class文件。
5. 成果
最后的class文件解析出来就是这个样子的。如下图所示:
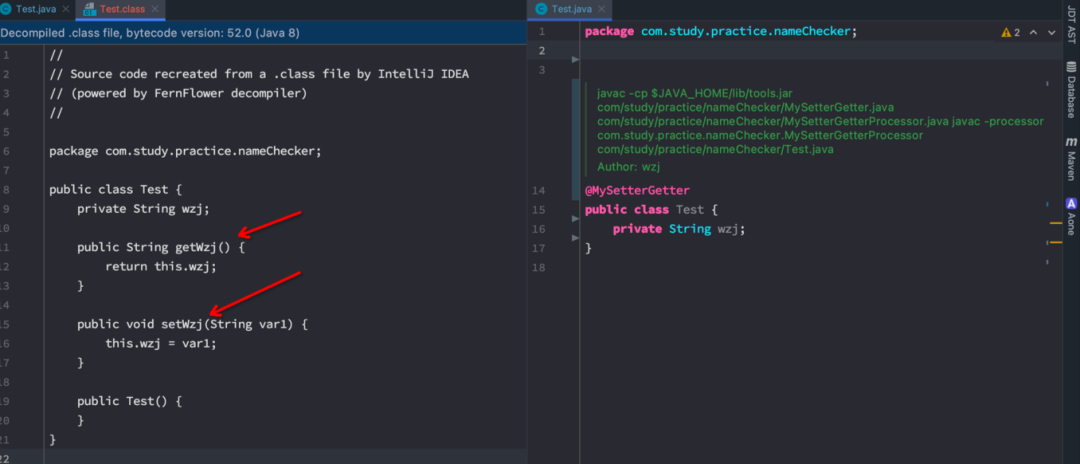
看到Setter/Getter方法就说明我们已经大功告成了!是不是很简单。
到此为止,我们就学会了如何自己写一个属于自己的简易Lombok的插件了。
附件
ModelScope开源模型社区评测征集令
ModelScope开源模型社区评测专场重磅来袭,发布你的评测,免费使用模型库搭建属于你的应用,有机会获得AirPods和阿里云定制礼品,更有多重福利点击链接查看活动详情。



