刘铁岩:如何四两拨千斤,高效地预训练NLP模型?

作者 | Mr Bear

1
大规模模型预训练
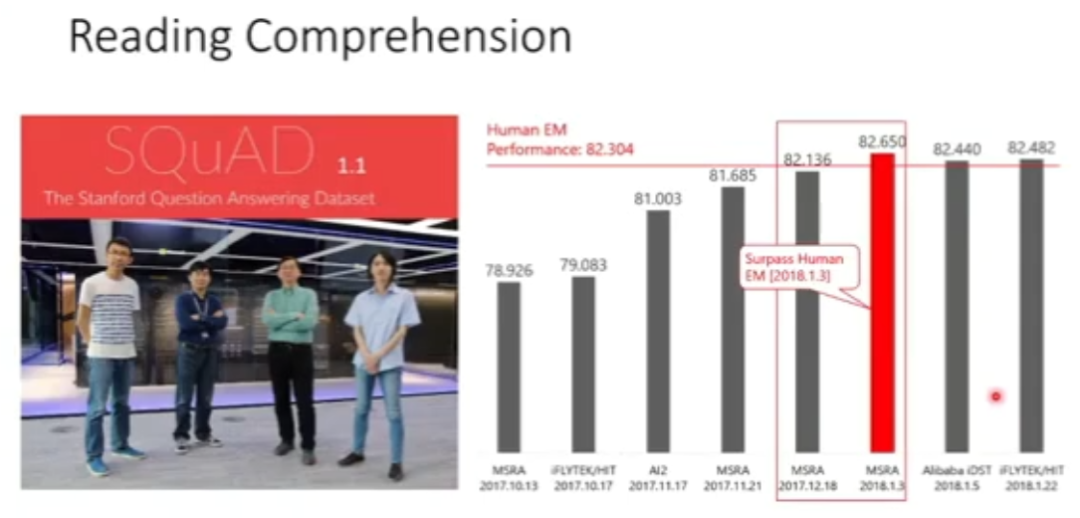 图 1:自然语言理解
图 1:自然语言理解
 图 2:机器翻译
图 2:机器翻译
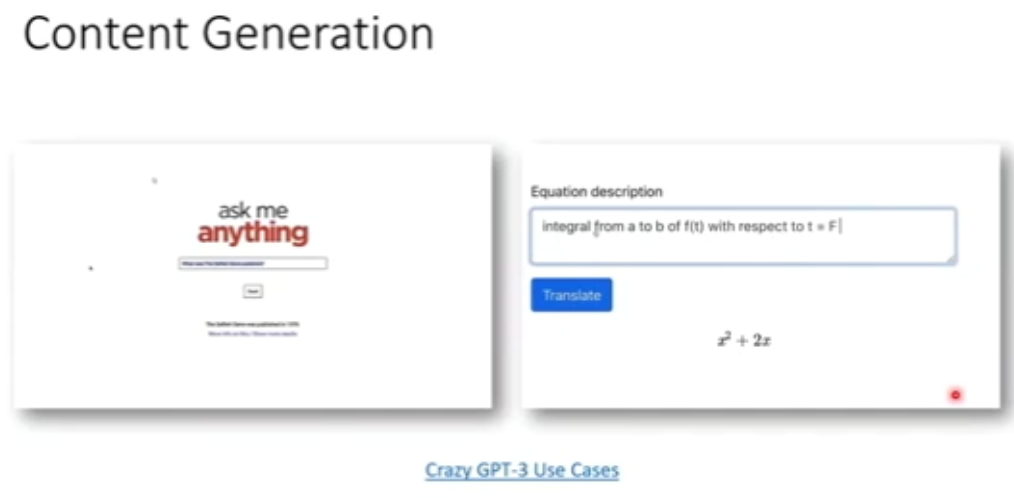 图 3:内容生成
图 3:内容生成
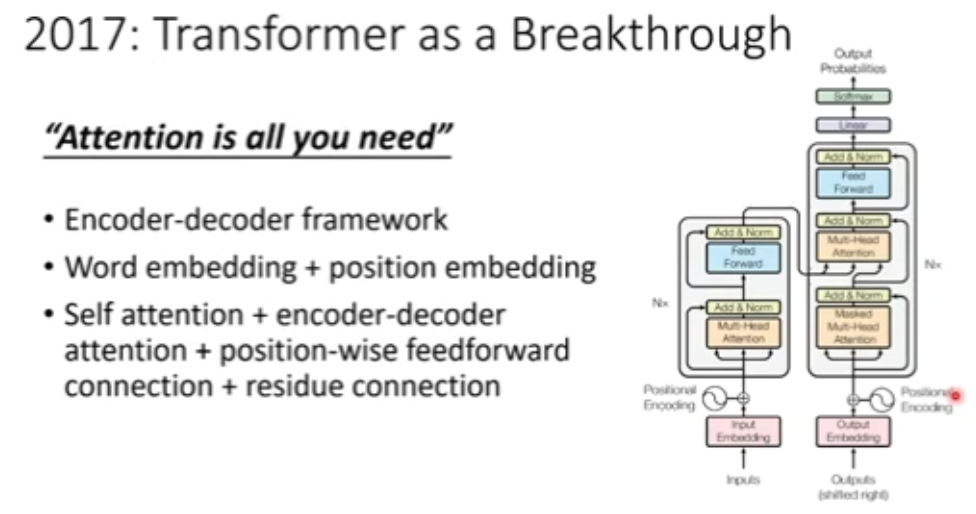 图 4:Transformer 模型
图 4:Transformer 模型
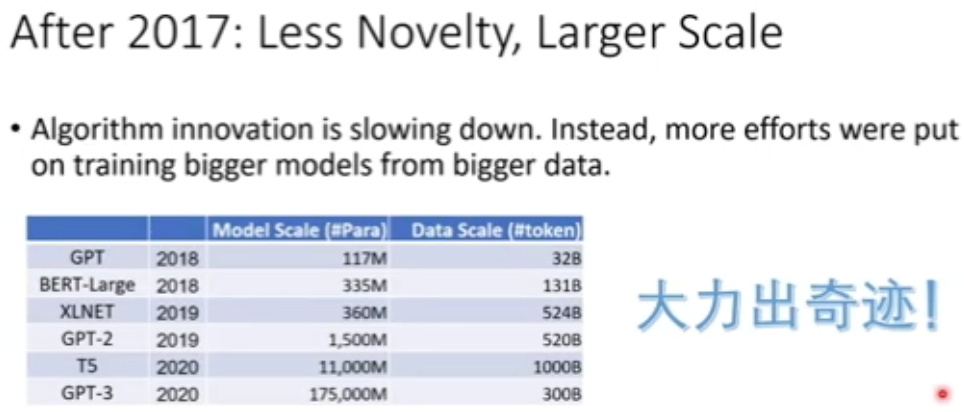 图 5:大规模预训练——大力出奇迹
图 5:大规模预训练——大力出奇迹
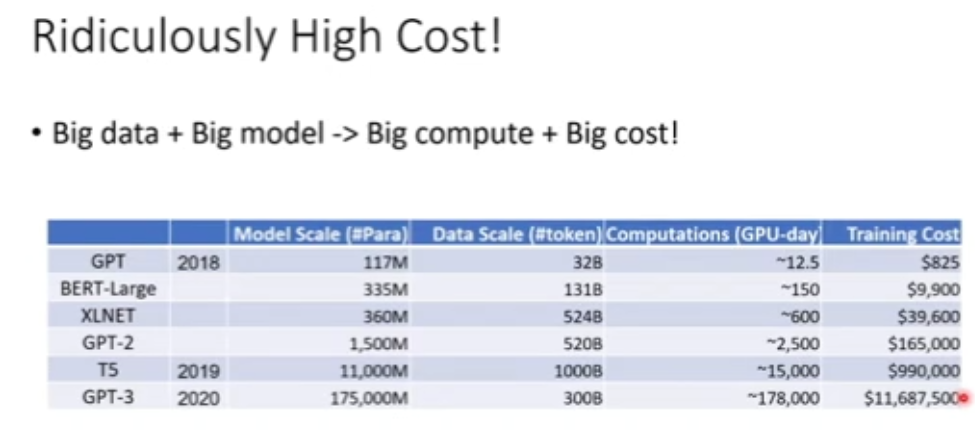 图 6:大规模预训练高昂的计算开销
图 6:大规模预训练高昂的计算开销
2
如何打破魔咒?
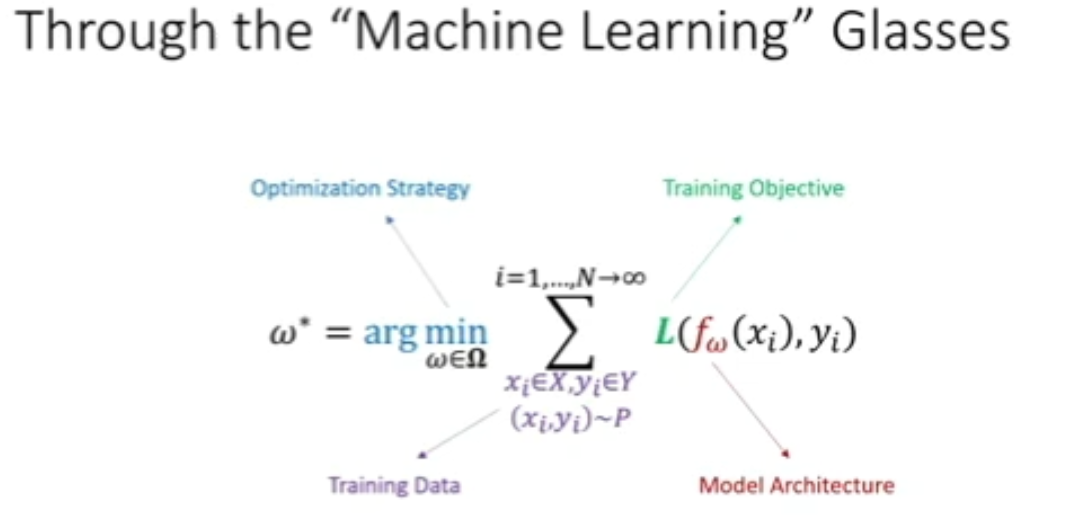 图 7:预训练的机器学习视角
图 7:预训练的机器学习视角
-
紫色的部分为满足一定底层的概率分布的训练数据; -
红色部分为模型架构(例如,神经网络的层数、每层的连接结构、是否包含注意力机制、是否包含跳跃链接等); -
绿色的部分为训练的目标函数; -
蓝色的部分为最大化或最小化目标函数的优化策略。
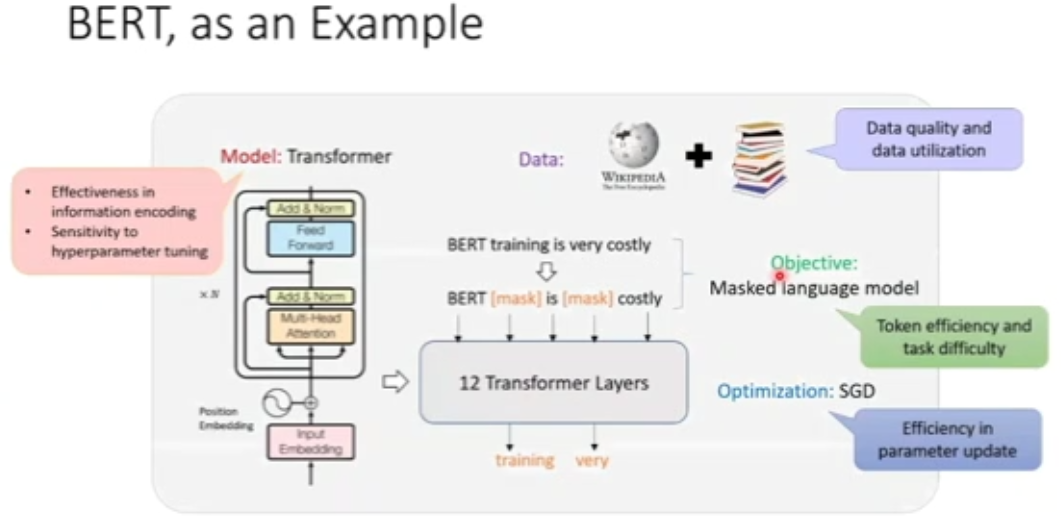 图 8:BERT 简析
图 8:BERT 简析
 图 9:预训练的计算开销
图 9:预训练的计算开销
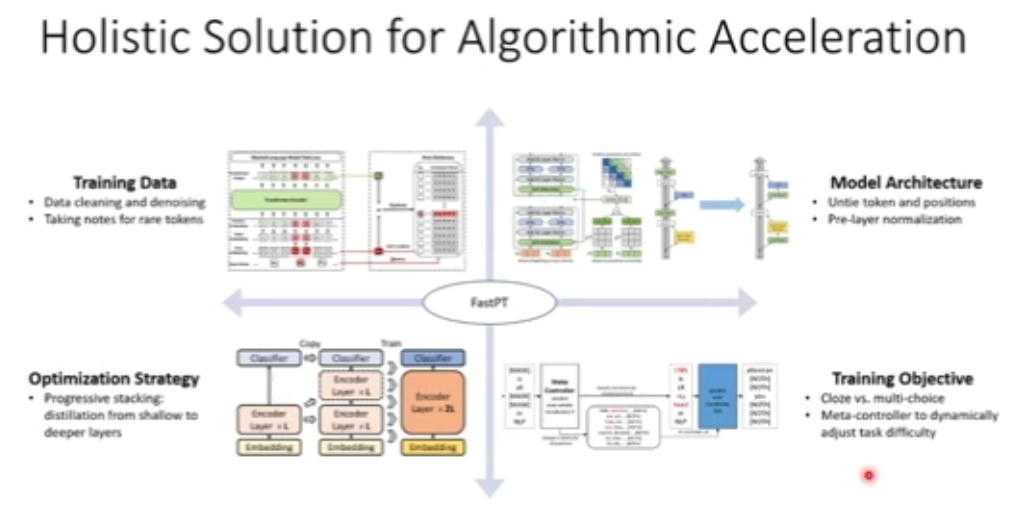 图 10:算法加速整体解决方案
图 10:算法加速整体解决方案
3
大数据≠好数据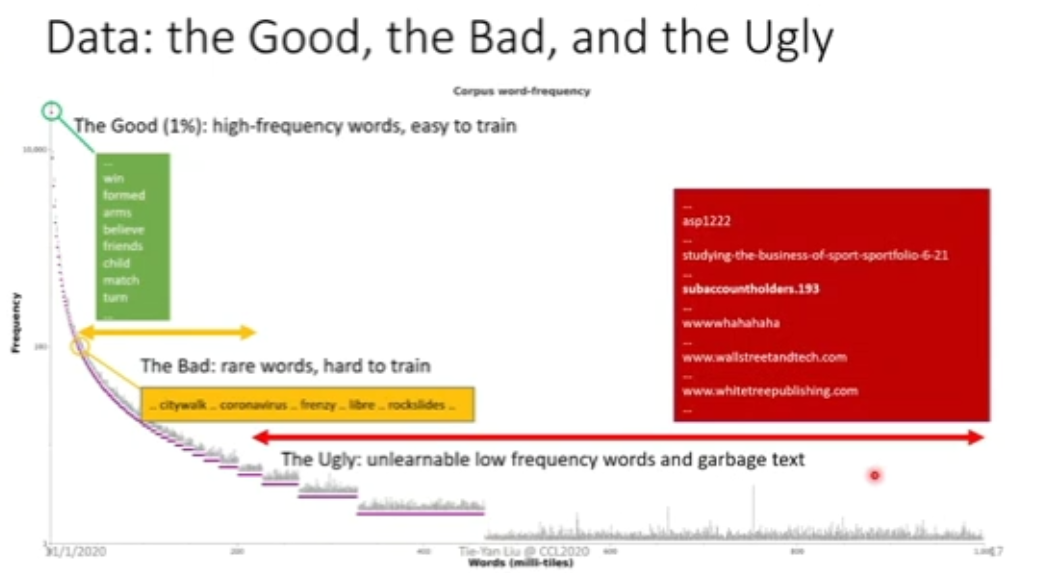
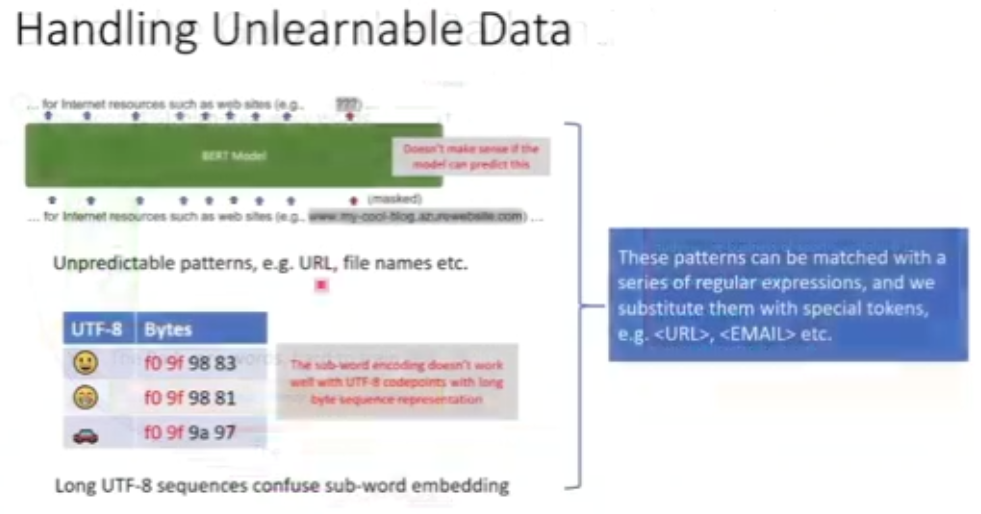 图 12:不可学习的数据
图 12:不可学习的数据
 图 13:包含不相关子词的低频词
图 13:包含不相关子词的低频词
 图 14:数据清洗实验结果
图 14:数据清洗实验结果
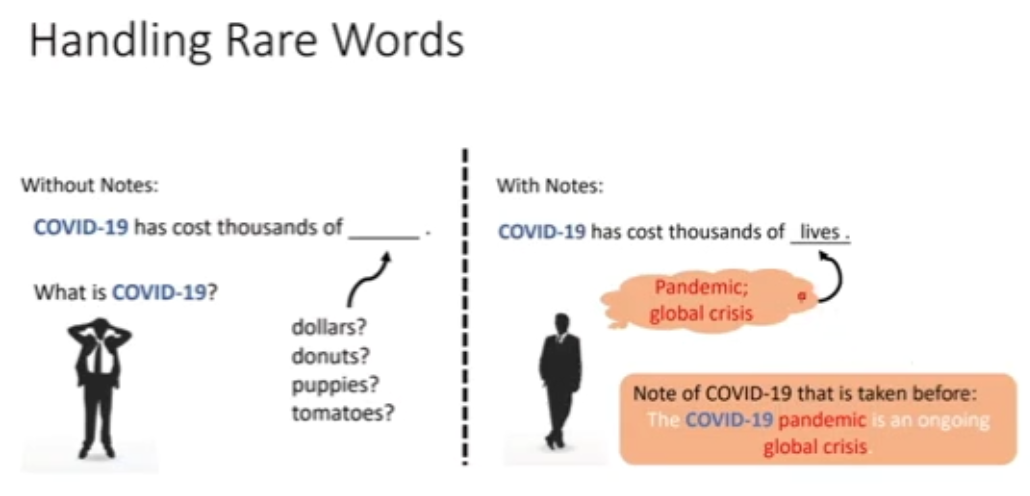 图 15:处理罕见词例
图 15:处理罕见词例
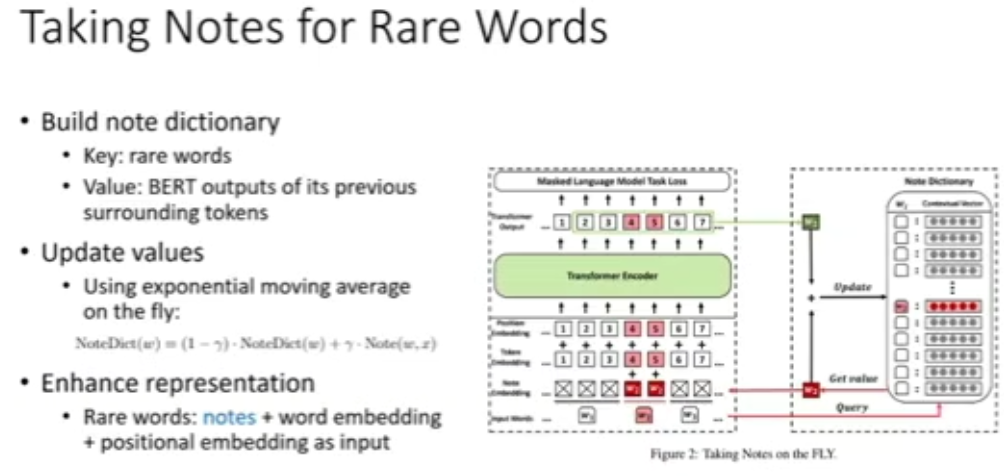 图 16:为罕见词例「记笔记」
图 16:为罕见词例「记笔记」
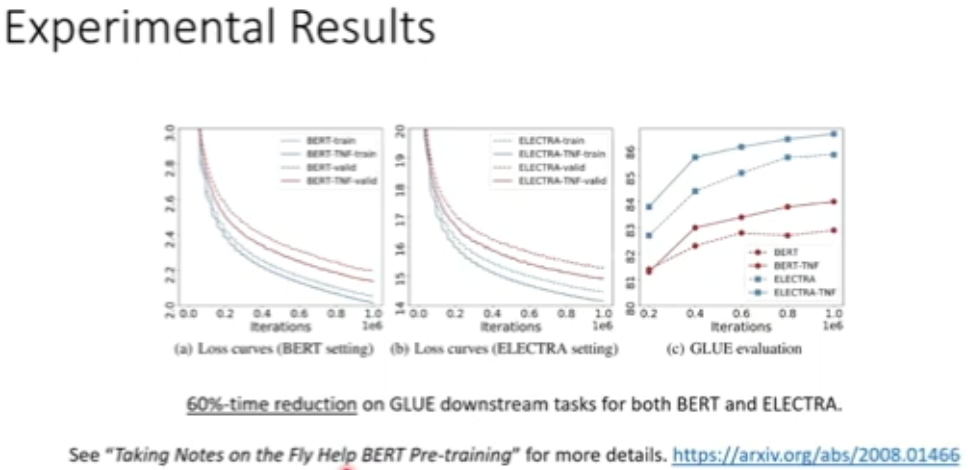 图 17:罕见词例处理实验结果
图 17:罕见词例处理实验结果
4
大模型≠好模型
 图 18:Transformer 中的位置编码
图 18:Transformer 中的位置编码
 图 19:重新思考绝对位置编码
图 19:重新思考绝对位置编码
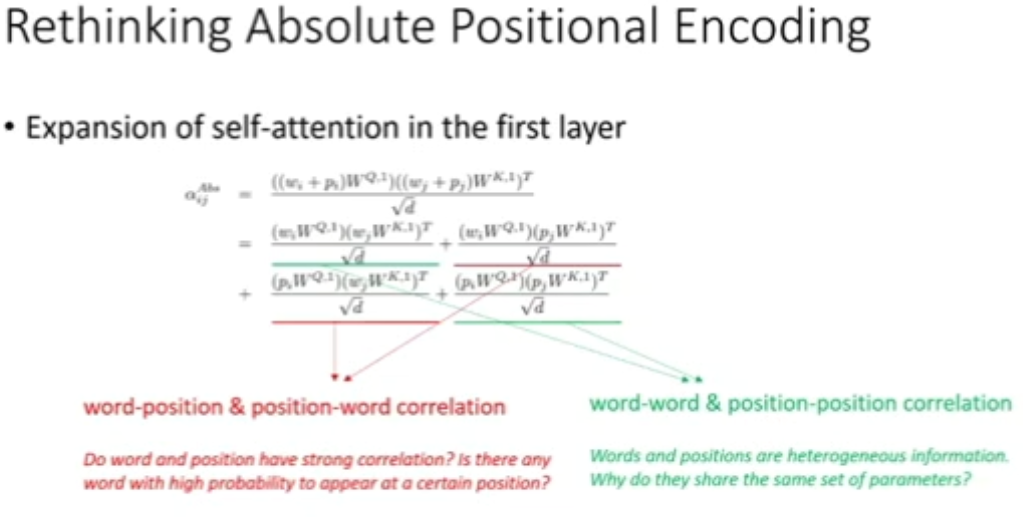 图 20:在第一层中自注意力的展开式
图 20:在第一层中自注意力的展开式
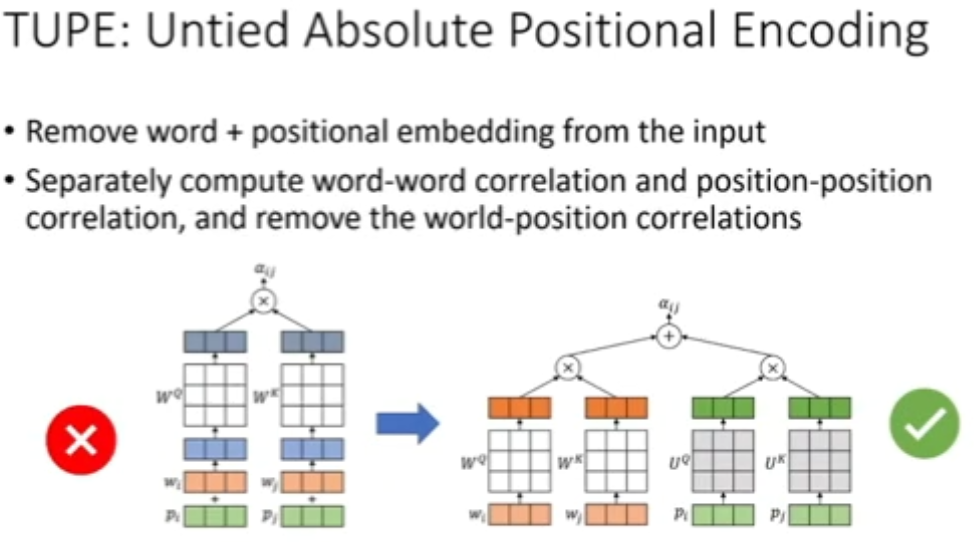 图 21:调整绝对位置编码
图 21:调整绝对位置编码
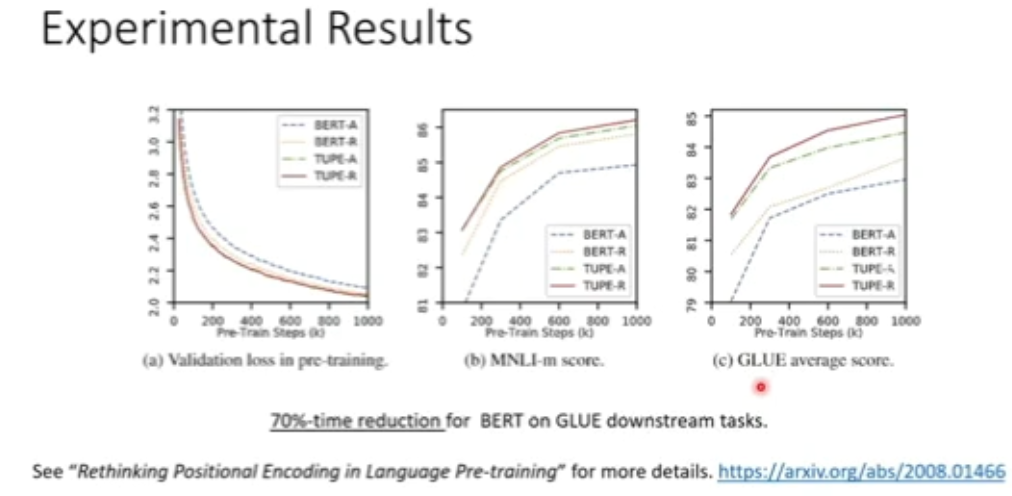 图 22:TUPE 实验结果
图 22:TUPE 实验结果
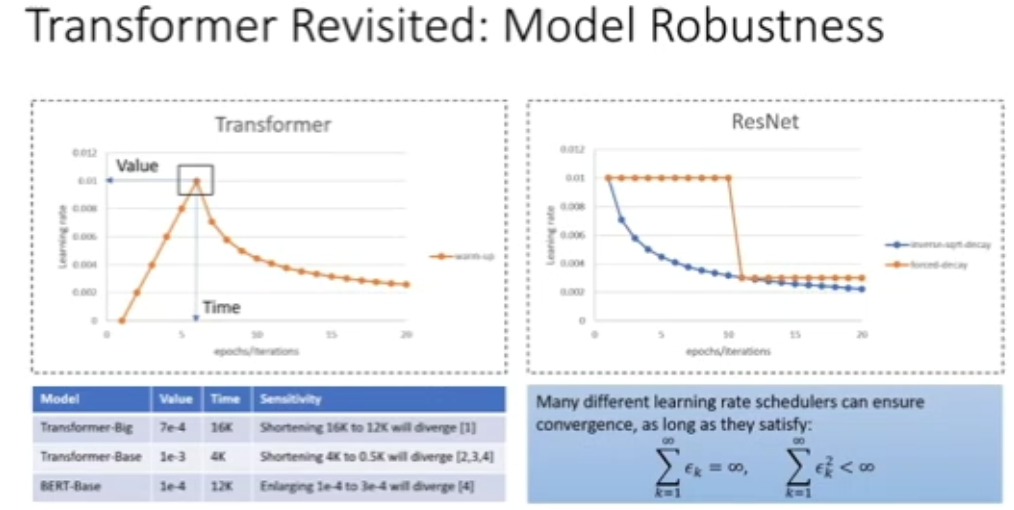 图 23:Transformer 模型的鲁棒性
图 23:Transformer 模型的鲁棒性
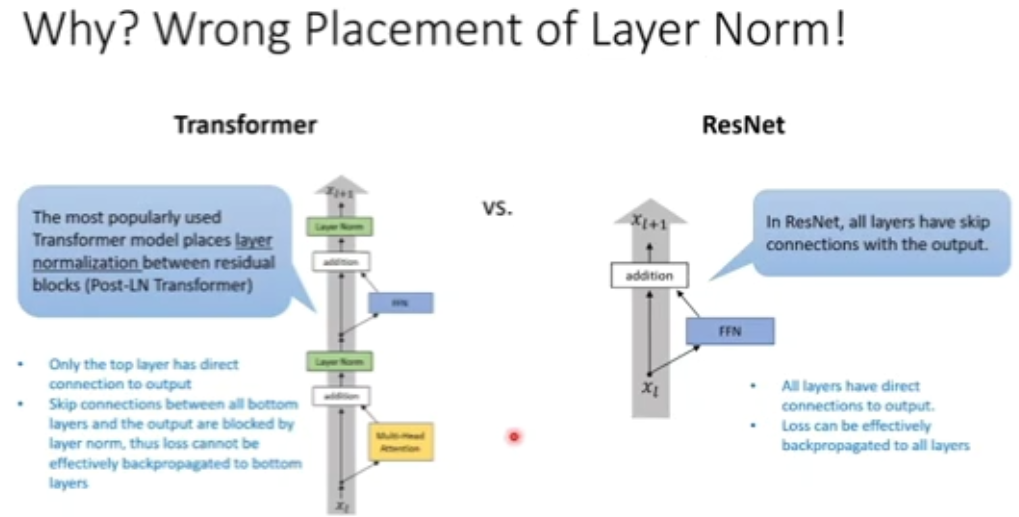 图 24:Transformer 模型缺乏鲁棒性的原因
图 24:Transformer 模型缺乏鲁棒性的原因
 图 25:Transformer 与 ResNet 训练过程对比
图 25:Transformer 与 ResNet 训练过程对比
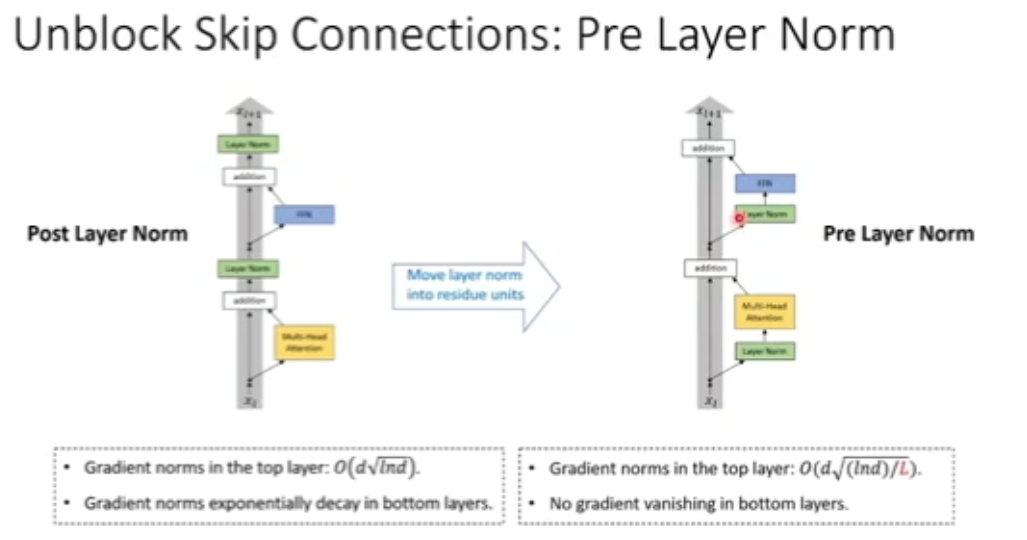 图 26:前处理层归一化
图 26:前处理层归一化
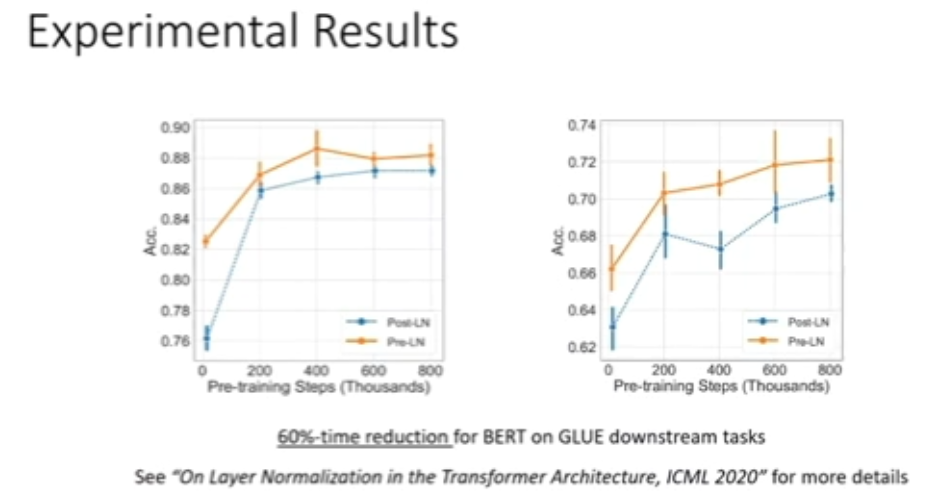 图 27:层归一化调整实验结果
图 27:层归一化调整实验结果
5
掩模语言模型≠好任务
 图 28:掩模语言模型——完形填空
图 28:掩模语言模型——完形填空
 图 29:多选题任务
图 29:多选题任务
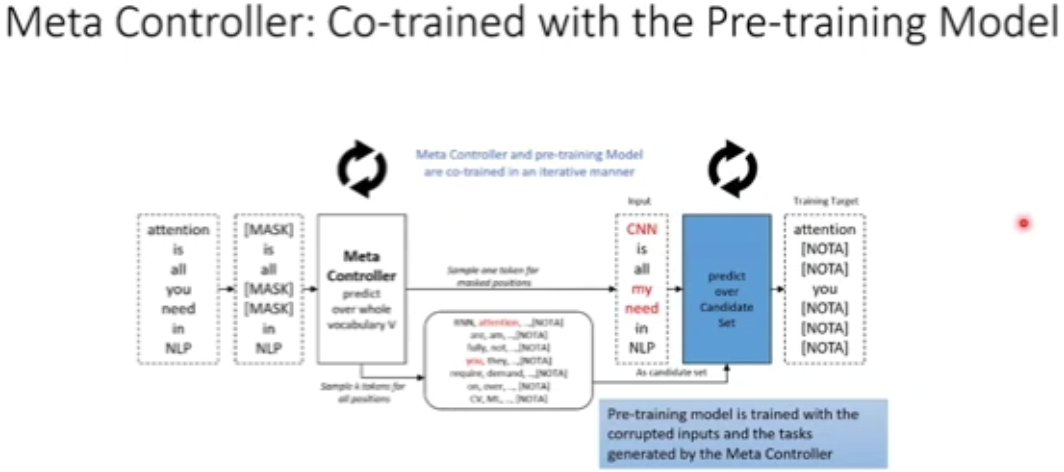 图 30:使用元控制器进行预训练
图 30:使用元控制器进行预训练
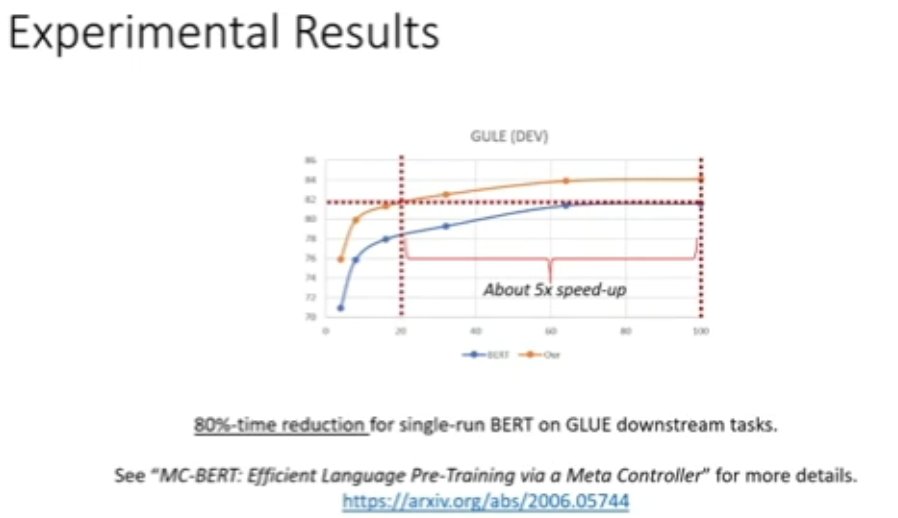 图 31:基于自适应多选题任务的预训练实验结果
图 31:基于自适应多选题任务的预训练实验结果
6
优化策略同样重要
 图 32:CNN 和 Transformer 之间的差别
图 32:CNN 和 Transformer 之间的差别
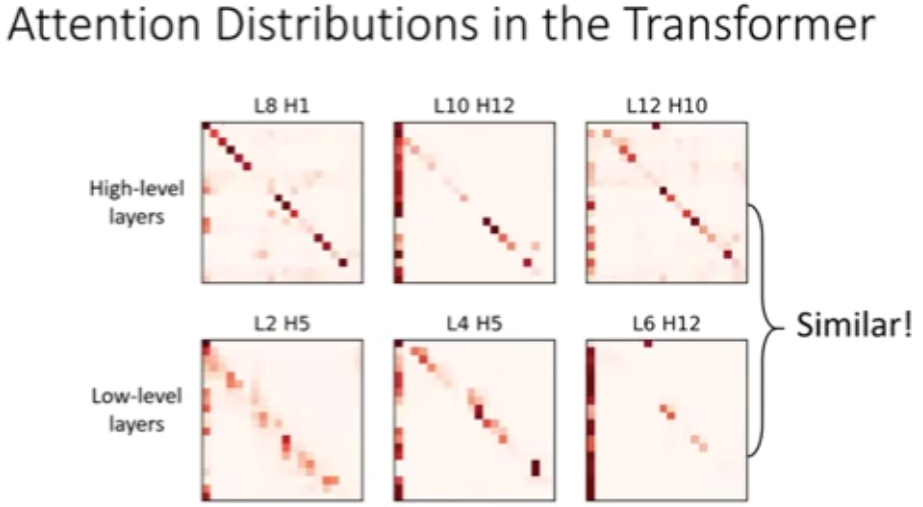 图 33:Transformer 中的注意力分布
图 33:Transformer 中的注意力分布
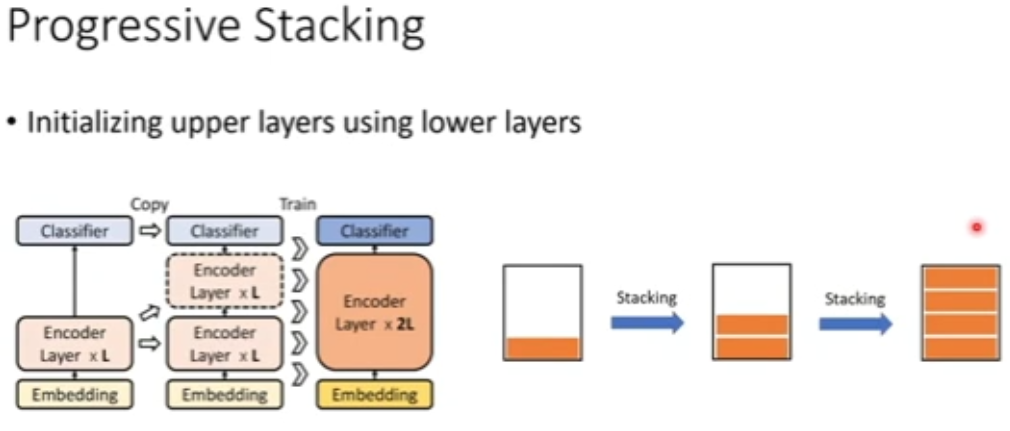 图 34:渐进堆叠
图 34:渐进堆叠
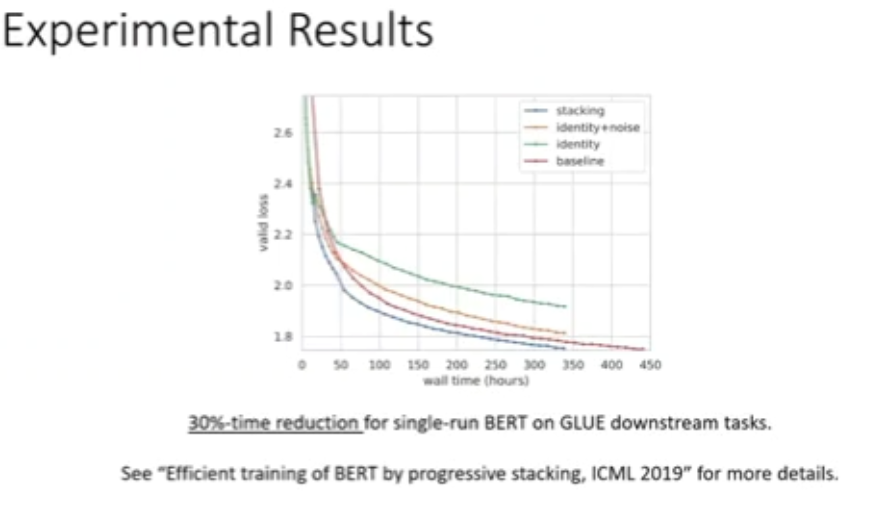 图 35:渐进堆叠实验结果
图 35:渐进堆叠实验结果
7
结语
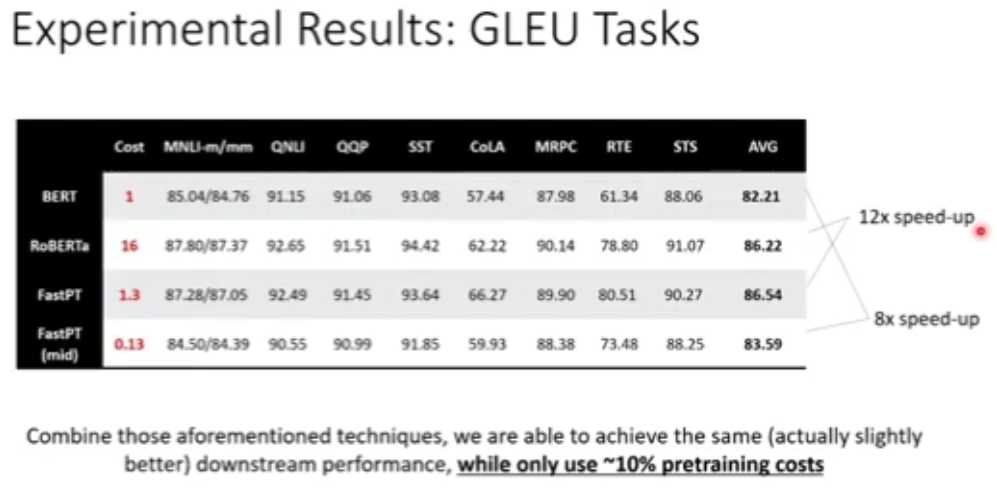 图 36:GLEU 任务实验结果
图 36:GLEU 任务实验结果
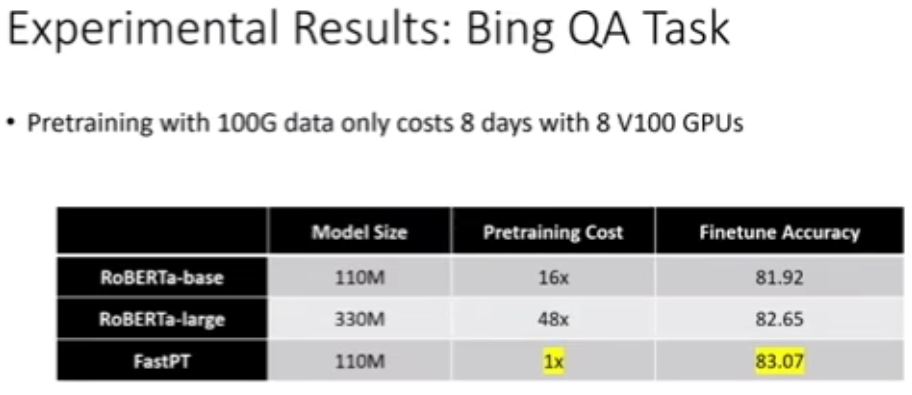 图 37:Bing QA 任务实验结果
图 37:Bing QA 任务实验结果
 图 38:NLP 模型预训练的未来
图 38:NLP 模型预训练的未来
 图 39:MSRA 在机器学习领域的研究成果
图 39:MSRA 在机器学习领域的研究成果
“CCF-NLP走进高校”是由中国计算机学会自然语言处理专业委员会(CCF-NLP)发起,联合AI研习社及各个知名高校开展的一系列高校NLP研究分享活动。
“CCF-NLP走进高校”第四期将走进“新疆大学”,一起聆听新疆大学NLP的前沿研究分享。本次活动邀请的嘉宾有哈尔滨工业大学(深圳)教授徐睿峰、清华大学计算机系长聘副教授黄民烈、天津大学教授熊德意、复旦大学教授黄萱菁、新疆大学教授汪烈军、西湖大学特聘研究员张岳。敬请期待!

点击阅读原文,直达直播页面
登录查看更多
相关内容

微软研究院首席研究员。ACM TOIS,TWEB副主编。卡内基梅隆(CMU)客座教授、诺丁汉荣誉教授。IEEE院士,ACM杰出会员。研究兴趣:机器学习、信息检索。个人主页:https://www.msra.cn/zh-cn/people/tie-yan-liu
Arxiv
16+阅读 · 2019年5月24日
Arxiv
7+阅读 · 2019年2月3日




相关VIP内容
相关资讯
相关论文
Arxiv
16+阅读 · 2019年5月24日
Arxiv
7+阅读 · 2019年2月3日