案例分享 | 58 二手车在移动端上的 AI 技术探索

背景
人工智能技术近年来逐渐成熟且日趋火热,但由于平台算力等原因,最初只能运行在后端服务器上对外提供服务,这在技术架构上造成了很多无法跨越的痛点。随着一些人工智能框架在移动平台上推出落地方案,58 二手车移动端团队也在 AI 方面做了一些探索,主要项目包括在移动端进行车辆自动识别和行驶证 VIN 码识别。
痛点:目前市面上大部分 APP 提供的车辆识别功能,都是通过手机拍照或者手动选择图片上传至后端,后端通过运算返回结果。这种方案给移动端带来的缺点是不够灵活、操作繁琐、交互体验差,流量消耗大。对于后端来说,服务器拿到的图片数据量大且未经过滤,压力陡增。VIN 码识别功能同样也面临这样的问题。
思考:如果让物体检测模型在移动平台上发挥作用,通过相机扫描镜头视野内的场景,将含有目标物体(车辆或 VIN 码)的图片上传给服务器进行精确的需要较高硬件性能支撑的运算,这样就利用千千万万台移动设备进行数据过滤,精确上传,以上提到的所有移动端及后端面临的体验问题、流量问题、服务器压力问题都将迎刃而解。
挑战:以上方案让系统架构在整体上得到极大改良,同时也给移动平台带来了很多挑战。移动平台算力能否支撑物体识别框架及模型的运算、集成 AI 模型及依赖库的安装包尺寸是否过大等都是亟需解决的问题。
通过对人工智能平台能力的持续关注和对其中一些移动平台相关技术的深入研究,我们在 Android 和 iOS 平台上成功实现了车辆识别和 VIN 码识别功能。
-
项目所涉及 AI 相关基础知识 -
移动平台上的车辆识别项目 移动端平台上的工程化落地方案及优化
项目所涉及 AI 相关基础知识
TensorFlow 是 Google 提供的开源深度学习框架。TensorFlow 到底是什么,网上有大量文章介绍,本文不再赘述。
Object_Detection API 是 Google 开放的物体识别系统,能够在单个图像中定位和识别多个对象。当模型获得一张图像时,它可以在图像中获得自己“认知”范围内的所有对象的列表,以及每个对象所在的位置、大小、置信度等信息。
我们基于 TensorFlow 的 Object_detection 目标检测架构进行了尝试,并以该架构为基础网络对车辆识别功能进行了模型训练,将模型迁移到了 Android 和 iOS 平台。
TensorFlow Lite,以下简称 TFLite。由名字可以看出,它是 TensorFlow 中的轻量化部分,是一种可以用于设备端推断的深度学习框架。它具有占用空间小,低延迟的特点。与 TensorFlow 超高的准确性相比,TFLite 的设计原则旨在兼顾准确性的同时,还能在各种设备上高效地运行模型。
-
TFLite 模型有两种格式:浮点运算(float 32)和量化模型(quantized_unit 8); -
在运行效率方面,TFLite 提供能够在移动设备运行更快的内核解释器; 在模型尺寸方面,当支持所有优化操作时,模型小于 300K,当仅支持 Inception v3 和 MobileNet 模型优化时,模型小于 200K。
Google 官方给出了 TFLite 的 Demo, Demo 提供了包含 person、bus、car、apple 等 90 个日常常见的分类,模型大小为 4.2M,以下是效果图:
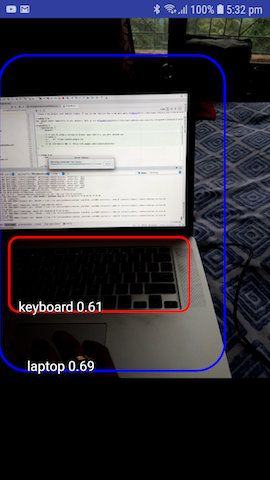

移动平台上的车辆识别项目
-
准备图片样本集,并手动标注样本(样本图片我们是网上随机下载的车辆图片进行标注); -
将样本集分别拆分为训练集、验证集和测试集生成 XML 文件(这一步也就是将我们标注的图片读取到 XML 中,保存标注的分类信息及坐标等数据)看一个列子(XML 文件图一):可以看到 XML 中包含了一些输入到模型中的参数 name:car、size、object 等等; -
将 XML 转化为 CSV(CSV 文件图二):这一步也就是将我们上面生成的 XML 文件数据全部读取到表格中; -
生成模型所识别的 TFRecord 二进制文件(TFRecord 内部使用了 “Protocol Buffer” 二进制数据编码方案,它只占用一个内存块,只需要一次性加载一个二进制文件的方式即可,简单,快速,尤其对大型训练数据很友好。而且当我们的训练数据量比较大的时候,可以将数据分成多个 TFRecord 文件,来提高处理效率); -
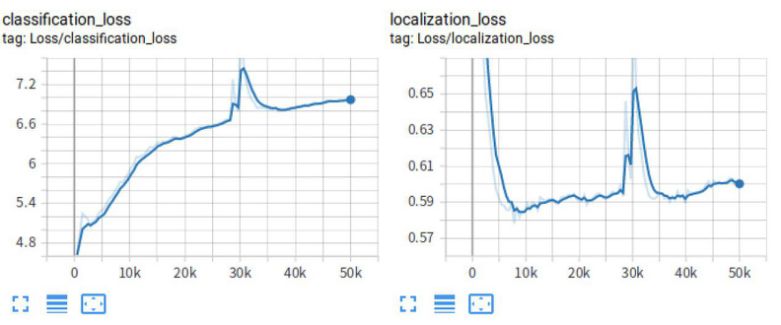
执行训练脚本,开始训练; 通过可视化工具 TensorBoard 查看训练过程(图三、图四);
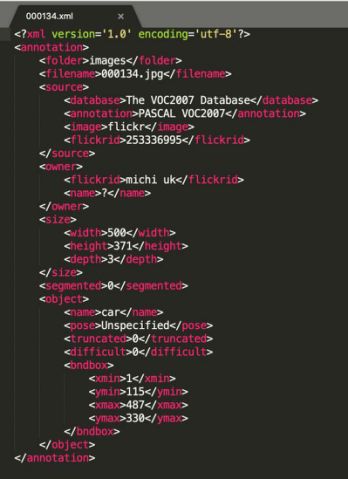
图一 xml 文件
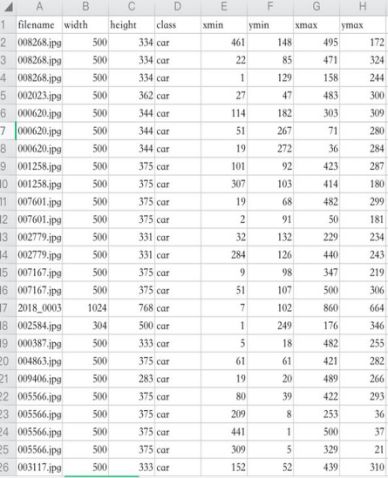
图二 CSV 文件
图三
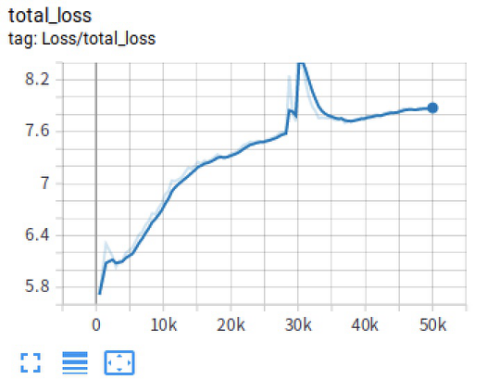
图四
-
样本数据可能太随机化,且不够清晰,其中掺杂了很多的奇怪的车型; -
模型选择不是最佳; -
训练参数的设置(训练步数、学习率、batch_size 等); 是否需要加入负样本集;
-
加入一些 58 二手车数据库中的真实二手车图片; 在模型选择上我们参考官方文档 (https://tensorflow.google.cn/lite/performance/best_practices),可以看到下图中模型越大准确度越高但是延迟性也越高,官方推荐可以根据自己的适用场景来进行取舍,考虑到 APP 包大小以及车辆识别的特征我们选择了准确度较低但是模型最小的量化的 MobileNet v2 (quantized_unit8 量化)。
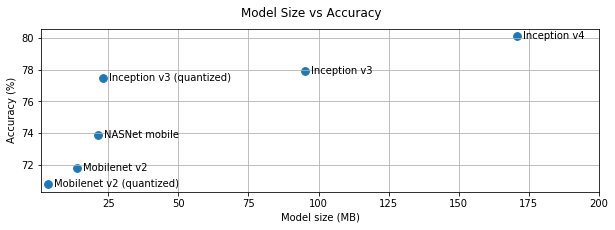
模型大小和准确度对比
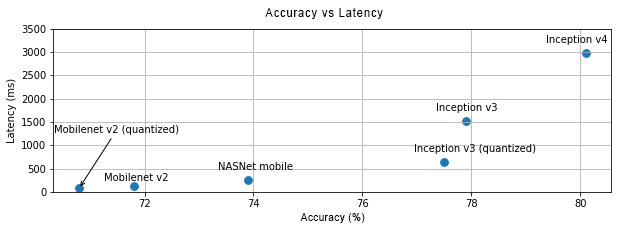
准确度和延迟性对比
-
训练参数上面经过几个版本的模型训练结果最终定为:训练步数为 50000 步、步长 batch_size 定为 8、初始学习率 learning_rate 为 0.004,其他均保持和官方提供的不变; 样本图片加入 person、dog、cat、other 四种负样本;
损失函数:
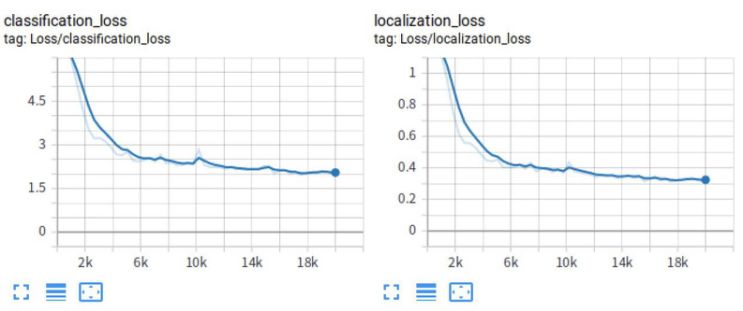
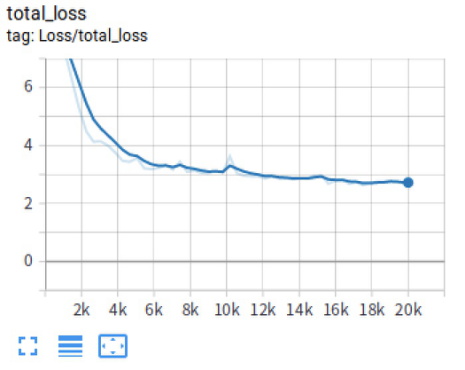
优化后的模型训练过程
分析上面的损失函数:可以看到经过重新训练的模型损失函数相对于之前已经好了很多,其中分类损失 (classification_loss)、定位损失 (localization_loss) 以及总损失 (total_loss) 均呈现下降效果,并且收敛的数值也相对于之前减少了还很多。
但是在真实的扫描过程中偶尔会误框一些相对于较方的物体,比如显示器,电脑,虽然识别出来的可信度 (confidence) 不高,但是不能出现误框,这样会给用户带来不信任感,所以我们决定对样本数据集继续优化。
之前训练模型的基础样本图片为 1800 张,考虑到会误识别一些方形的情况,我们决定对样本数据集做随机裁剪、随机亮度、对比度、色度、饱和度的设置来增大样本量,这样的话对于提高模型的准确率和提升模型的泛化能力非常有帮助,并且也可以获得更多的图片样本。
首先将基础样本中的车辆的图片进行裁剪,在原有标注的基础上面对其进行缩小裁剪,裁剪到标注框的位置,这样更能凸显车辆的具体特征,同时也能减少模型对一张图片中负样本特征提取。
其次我们又对图片分别进行随机亮度、饱和度、对比度、色度的增强,这样可以减少识别物体不同色彩等无关因素对图像识别模型的影响。图片如下:

原图

裁剪后的图

随机饱和度

随机对比度

随机色度
数据增强后的样本
经过此次样本数据的增强基本解决了之前偶尔误框的场景,并且为了测试模型在真机上的运行效果,我们在测试机上导入了 1000 张二手车图片,通过脚本启动模型进行识别,每张图片识别 3 次,将总的 3000 次识别结果保存下来,得到框选的次数达到 2836 次,平均的置信度也高达 94.6%,对于粗分类后框选的图片上传到 server 端之后,server 端进行车辆细分类,这里不做具体分析。
车辆识别效果如图所示:
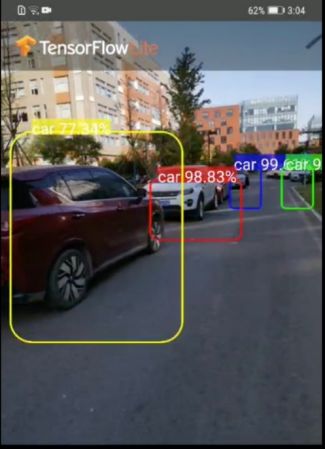

车辆识别效果图
有了对车辆识别的经验,我们希望可以通过对 VIN 码识别,获取车辆基本信息,节省车辆发布时间,提高发布通过率,并期望将 VIN 码识别的场景放在二手车的发布界面。
VIN 码识别的模型构建原理基本与车辆识别类似,这里就不做赘述了。
依据车辆识别的经验我们对 2889 张 VIN 图片做同样的操作,并加入了对抗样本以及修改训练文件中的 aspect_ratio 值,用于避免识别过程中多标、高标、少标等现象。实际训练样本达到 34668 张。
图片如下:

原图

随机切割

对抗样本
训练后的模型大约仍有 10% 的概率出现多标现象,很小概率出现少标,手机距离行驶证比较远的时候会偶尔出现高标,正常效果置信度在 90% 以上。
结论:基本满足使用场景,效果如下图所示:

VIN 码识别效果图
移动端平台上的工程化落地方案及优化
估车价 APP 之前使用的方案一直都是通过用户拍照或者选择图片将图片上传给服务端,服务端返回识别结果。所以我们先在估车价 APP 上引入了车辆识别的模型,编码整体流程如下图:
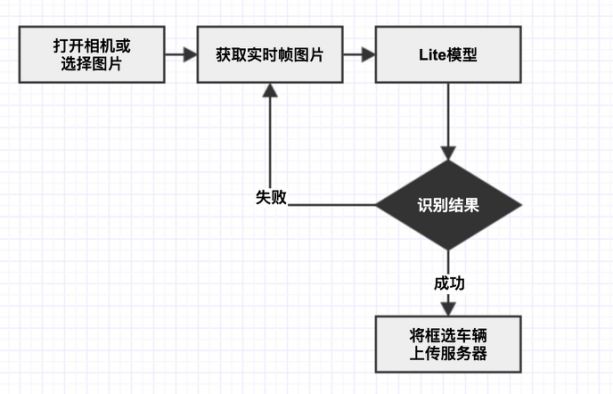
车辆识别流程图
考虑到以后的拓展,我们尝试用下载的方式将 TFLite 模型文件导入项目工程,方便以后为项目提供更多的物体检测的能力,比如今后加入识别 VIN 码或者其他物体,直接从远程下载模型进行读取实现物体扫描;也不再需要将模型文件打入 APP,同时也减少了包大小。
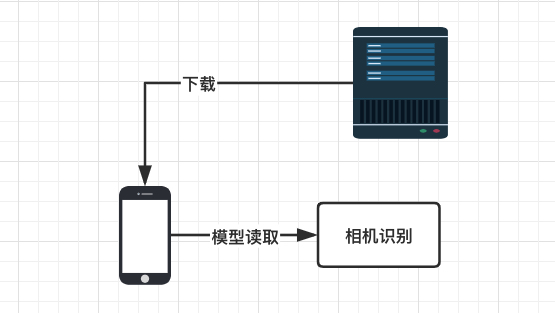
模型下载
-
将车辆识别粗分类模型前置到移动端,服务端将细分类识别的品牌车系返回移动端,减少服务端压力,避免无效的图片上传及扫描; -
优化了用户体验和交互流程,用户打开界面后进行实时扫描(或者选择图片),扫描到车辆后上传至服务端; 移动端分担了服务端粗分类的识别,减少了识别的响应时间。
服务器端响应时间:
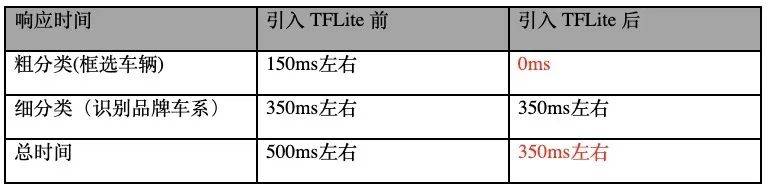
可以看到移动端引入了车辆识别模型后响应时间相比之前减少了 30%~40%,由于手上测试机型范围有限,以上性能测试数据只涵盖以下机型:小米 8、小米 9、华为 Mate20Pro、华为 P20、vivo Z3及 iOS iPhone 7P。
APP 包大小:
模型文件(5.6 M)通过服务器下载的方式读取,只需要引入依赖库就可以了,APP 也只会增加一个依赖库的大小:Android 增加 3.1 M,iOS(OC)增加 1.3 M,(Swift)增加 3.1 M:
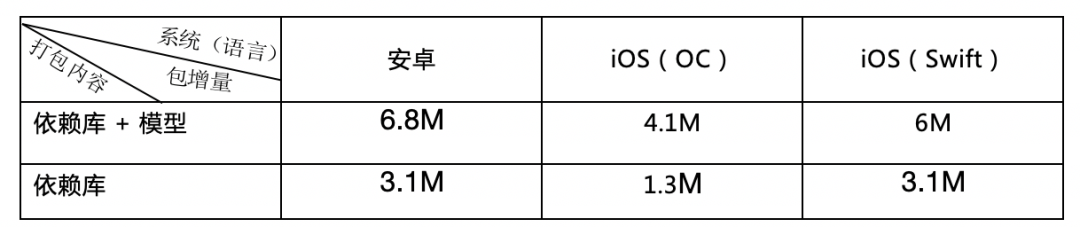
之后我们也会通过尝试 selective registration 等方式进一步缩小包增量。

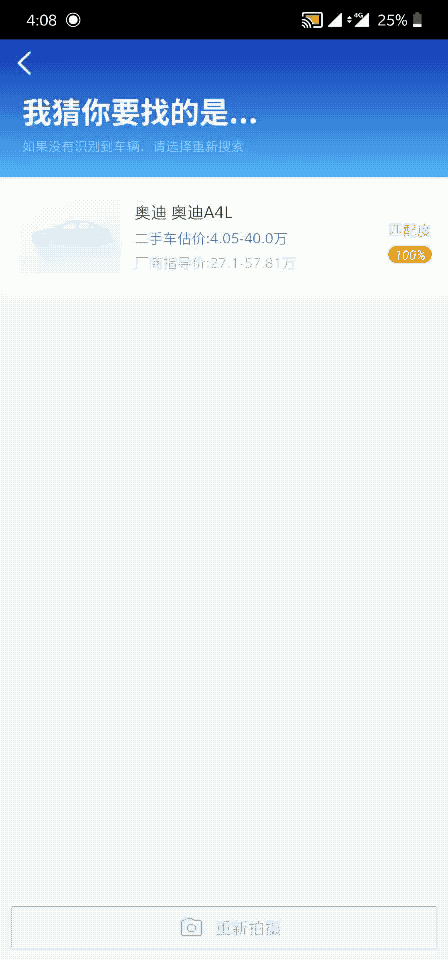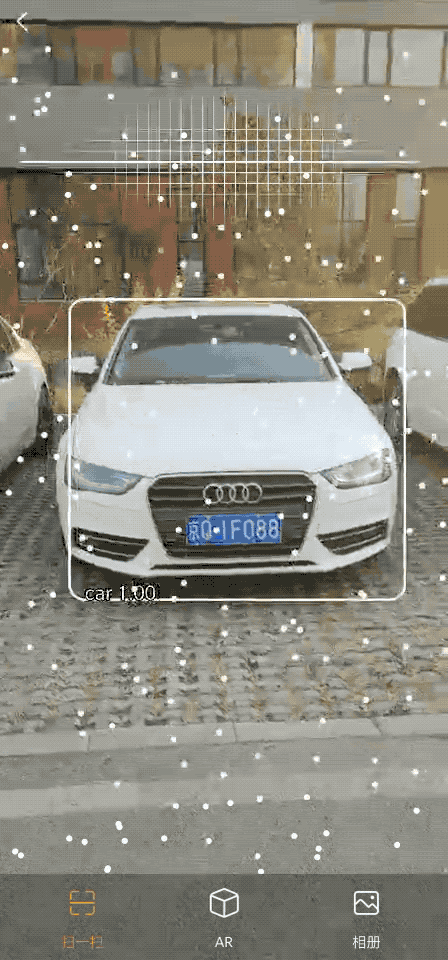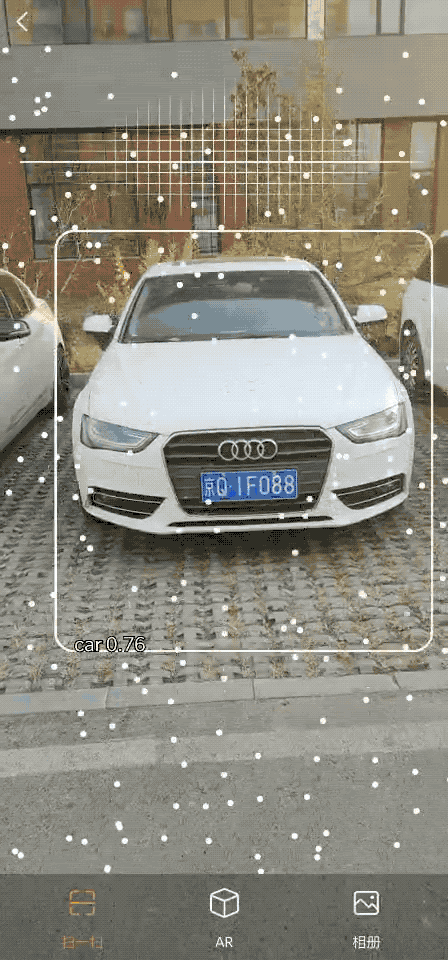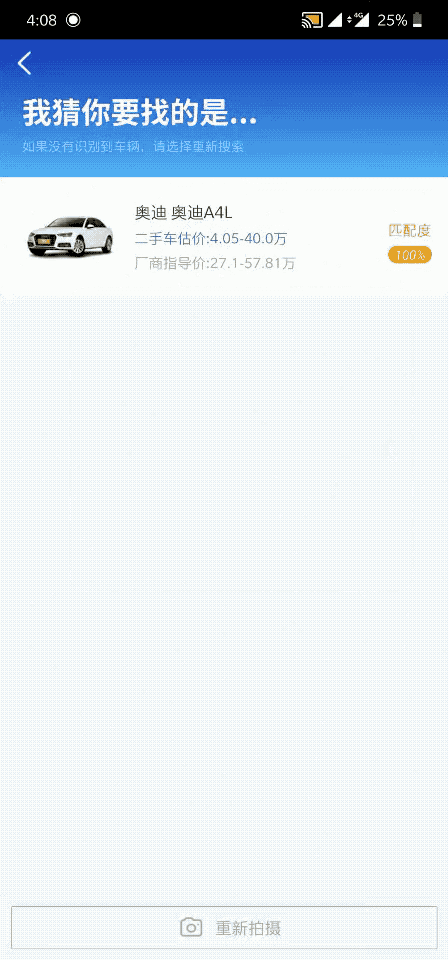
落地效果图
总结、展望或规划
通过两个 AI 功能在移动平台上的落地,我们梳理出整套相关技术体系,并积累了一定的经验,之后我们会进行更多的优化。随着业务的不断深入,AI 技术在移动平台上的应用将愈发深入、全面,会有更多更贴近业务的场景由于移动 AI 技术的使用而变得完善。
相较后端服务器的高性能,以手机为主的移动平台的计算能力远不能及。而人工智能网络的计算量又非常庞大。纵观 AI 技术的发展历史,就曾因为计算量太过庞大,而又没有足够的计算资源而陷入停滞,后来又随着近代计算机技术的迅猛发展得到普及。所以最初的人工智能应用只能在数据层面运行在服务器上。然而技术总是在不断发展,AI 算法的持续优化使得其对计算资源的要求逐渐降低、近年来智能终端设备的性能也得到迅猛发展,在突破算力瓶颈之后,移动智能设备的优势立即凸显出来,它有眼睛(摄像头)可以看,有耳朵(麦)可以听,它能捕捉所有外界的信息,然后通过 AI 技术对信息进行加工、回馈。目前很多 APP 已经可以脱离网络和后端服务器进行智能运算,给用户带来更好、更丰富的使用体验。然而这只是开始,相信随着 AI 技术的逐渐普及和移动平台的性能提升,移动人工智能应用,大有可为。
参考文献
[1] TensorFlow Lite:https://tensorflow.google.cn/lite
作者简介
李通,58 同城二手车技术部后端及移动端负责人,资深研发工程师。
马志超,58 同城二手车技术部高级 IOS 工程师。
黄海杰,58 同城二手车技术部高级 android 工程师。
想加入案例分享?点击 “阅读原文”,填写相关信息,我们会尽快与你联系。
更多相关案例:





