TensorFlow: 薛定谔的管道

要说史上最著名的猫,大概就是薛定谔的那只了。它被关在装有少量镭和氰化物的密闭容器里,当镭发生衰变时,就会触发机关打碎装有氰化物的瓶子,猫就会死亡;如果镭不发生衰变,猫就会存活下来。在量子力学理论中,由于放射性的镭处于衰变和没有衰变两种状态的叠加,这只猫也处于生死叠加态,只有对其进行观测,才能决定这只猫的生死。
所以,哈姆雷特说:
生存还是死亡,这是一个问题!
今天我们从猫说起,来讨论一个管道,一个蕴含着某些不确定性的管道:TensorFlow。我们从TensorFlow中的一个计算实例出发,在这个例子中的一个计算节点像薛定谔的猫一样具备不确定性的输出结果:如下图所示的例子,同时计算节点assign和节点c时,c的计算结果out_c是不确定的,这是因为TensorFlow会尽可能的对计算过程并行化,所以out_c的结果依赖assign和c谁先执行。

那么面对这样一个可能会产生“薛定谔现象”的框架,我们如何利用它来实现模型呢?
我们在使用TensorFlow这个软件库构建模型时,实际上是在TensorFlow提供的这套api系统里编写TF程序,这里可以把TensorFlow看成是一门进行数值计算的“编程语言”。那么为了更好的掌握TF这么“语言”,我们可以从三个层次来学习:
理解TensorFlow的基本概念和基本组件
基于对基本概念的理解,利用基本组件来构建模型
调试模型,优化模型速度,优化模型精度
这里我们从理解基本概念以及一个调试模型的例子出发,来介绍其实现模型计算的过程。
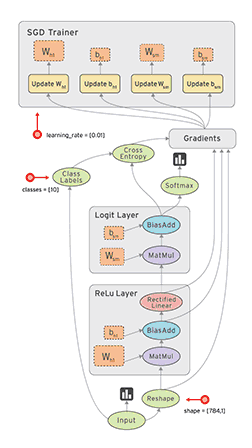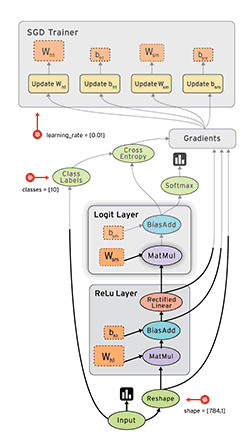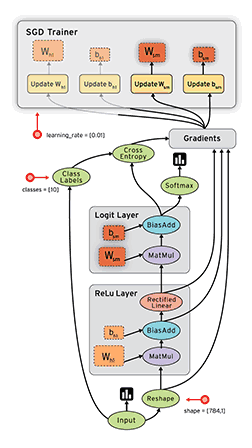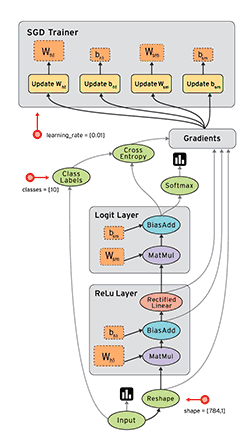
TensorFlow的核心是通过数据流图的方式来实现数值计算,这里最核心的概念就是数据流图,TensorFlow是以静态图(这里不强调其动态图的特性)的方式来表达计算,那么一旦计算模型以图的方式表达完成,就要通过Session来驱动计算,整体示意如上图所示,节点和边构成了你的计算模型,而实际计算时数据(Tensor)沿着图的边被驱动着进行计算从而流动起来,这也形象的表示了TensorFlow=Tensor+Flow。因此TensorFlow程序就可以分为两个阶段:
阶段一:组装一个计算图,这里只是用TF的api来表达计算模型,生成的是一个静态图,图由计算的节点以及节点之间的连接表示,这个阶段只是静态的表示了计算,因此得不到任何实际的计算值。
阶段二:通过一个Session(会话)来执行计算,这里可以计算某个节点,而这个节点所依赖的父节点都会被驱动先行执行。
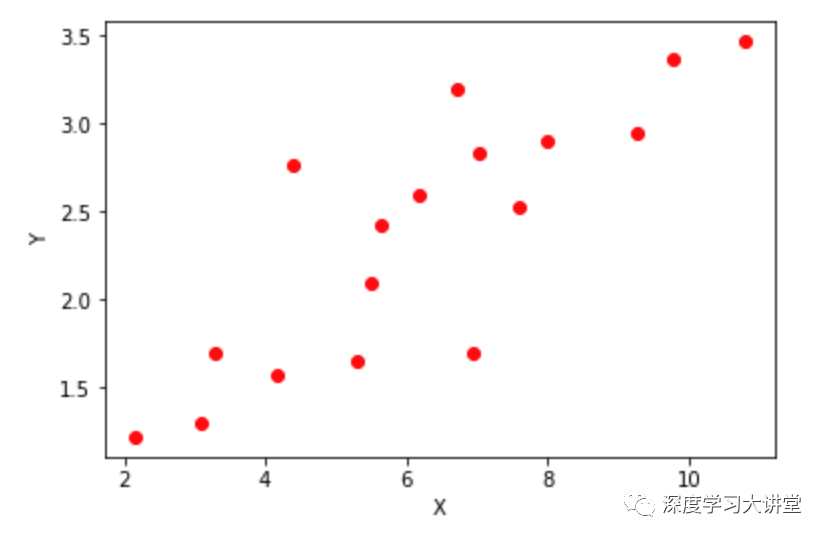
比如我们想从下图所示的数据(X,Y)中学习一个线性关系y=w*x+b
对于这样一个机器学习任务,一般分为测试过程和训练过程,测试过程一般比较简单,这里我们介绍如何使用TensorFlow来实现训练过程,对于机器学习模型的训练过程的一般可以如下面流程图所示:
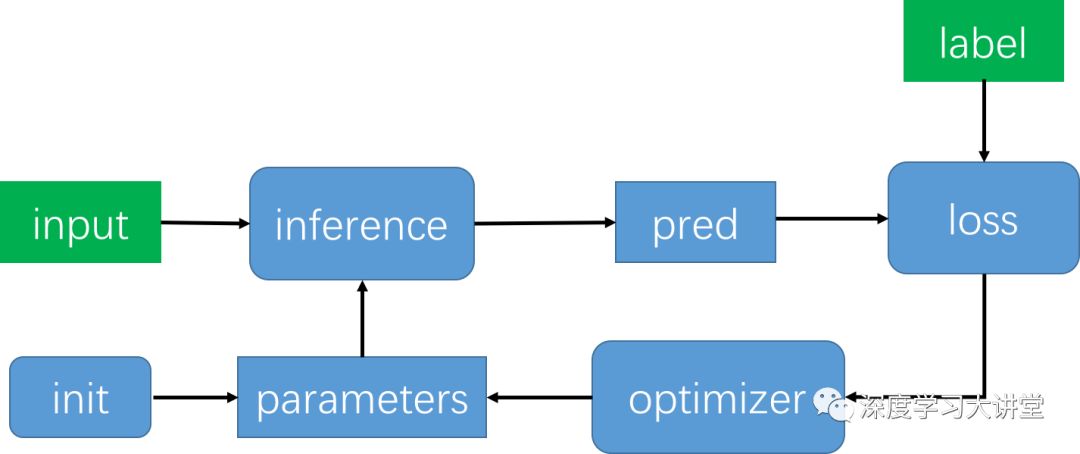
具体步骤为:
1. 定义输入和输出标签
2. 定义模型参数
3. 初始化模型参数
4. 基于输入和模型参数,由模型的推理过程计算模型的预测结果
5. 基于模型的预测结果和标签值,由损失函数来计算loss
6. 优化器通过更新参数来最小化loss
7. 不断重复4-6直到迭代次数达到或者loss低于设定的阈值
使用TensorFlow来完成以上计算时,我们需要:
1) 使用静态图的方式表达上面的计算过程(对应阶段一)
2) 使用Session(会话)来驱动上面的计算(对应阶段二)
可以如下面代码所示,

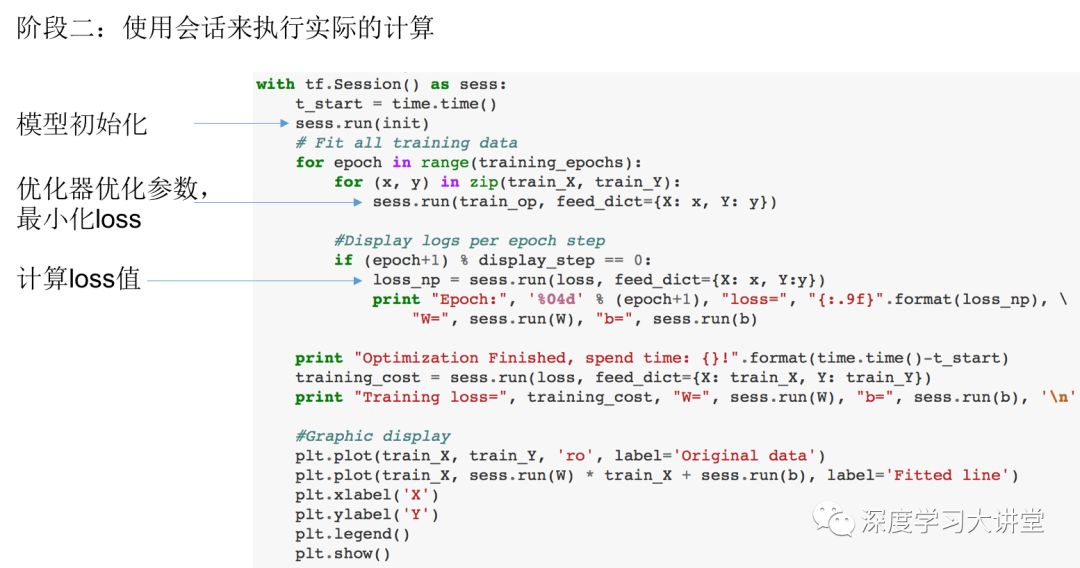
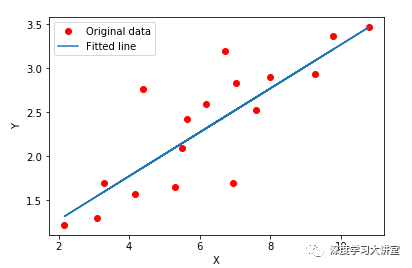
所有我们想要进行的计算都需要在阶段一进行表达,如我们需要进行模型初始化这样一个计算过程,那么我们需要在阶段一构造一个init操作节点,我们需要最小化loss,更新模型参数,我们可以构造一个train_op操作节点,每个计算对应计算图中的一个计算节点,一旦计算图构建完成,我们就可以在阶段二过程通过运行这个节点来进行实际的计算如sess.run(init),sess.run(train_op)。由此通过阶段一阶段二两部分程序完成我们想要的计算逻辑,学习到的线性模型如下图所示。
正是因为TF这种graph和session两阶段的划分,导致我们在调试TF的时候也会分为两个阶段:
1. 错误发生在组装图部分。这里TF会进行类型检测,以及shape推理,所以一般dtype和shape相关的错误会与这一部分代码相关。
2. 错误发生在执行图部分。这里TF会进行运行时的计算,所以NaN等问题会发生在这个阶段。
如果想更多的了解如何使用TensorFlow构建机器学习模型,可以点击阅读原文,关注深度学习大讲堂推出的Tensorflow实战课程。
往期精彩回顾



