哈佛用NBA比赛数据生成报道,评测各模型效果 | 数据集+论文+代码
安妮 编译整理
量子位出品 | 公众号 QbitAI
近日,哈佛大学的三名研究人员公开发表论文《Challenges of Data-to-Document Generation》,利用NBA的比赛结果数据尝试生成描述性文本,并测试了现有的神经网络模型生成文本效果如何。

这篇论文由Sam Wiseman、Stuart M. Shieber和Alexander M. Rush三人共同完成。Wiseman是工程和应用科学学院的博士生,Shieber和Rush同是是哈佛大学的NLP专家。

论文摘要
神经模型已经在小型数据库生成短描述文本问题上取得了重大进展。在这篇文章中,我们用稍微复杂的数据库测试神经模型数据转文本的能力,探究现有方法在这个任务中的有效性。
首先,我们引入了一个记载了大量数据的语料库,里面也包含与数据匹配的描述性文档。随后,我们创建了一套用来分析表现结果的评估方法,并用当前的神经模型生成方法获取基线观测数据。
结果表明,这些模型可以生成流畅的文本,但看起来不像人类写的。此外,模板化的基线在某些指标上的表现会超过神经模型。
测试数据集
研究人员用两个数据集测试模型性能。
第一个数据集是来自体育网站ROTOWIRE的4853篇NBA比赛报道,包含NBA在2014年初到2017年3月之间的比赛。这个数据集被随机分为训练、验证和测试集,分别包含3398、727和728条报道。
第二个数据集来自体育网站SBNation,涵盖了10903篇从2006年底到2017年3月之间的报道。其中训练、验证和测试集中分别有7633、1635和1635条报道。
下面这张表格展示了数据集中可能被记录的信息——

测试结果
研究人员从ROTOWIRE数据库中抽取了以下数据,里面同时包含了比分数据和球员信息,让模型转化成文本。
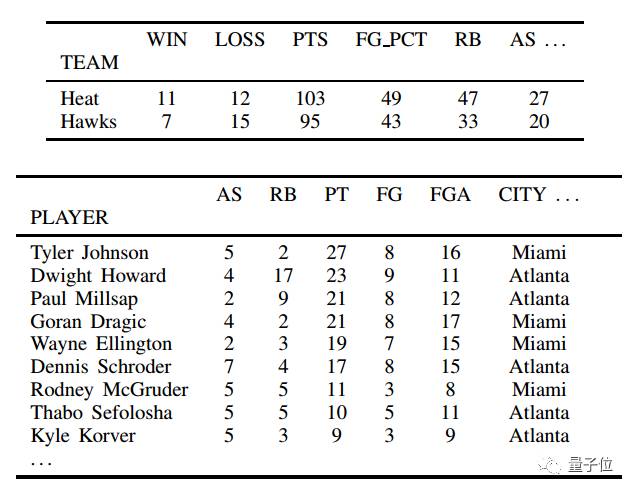
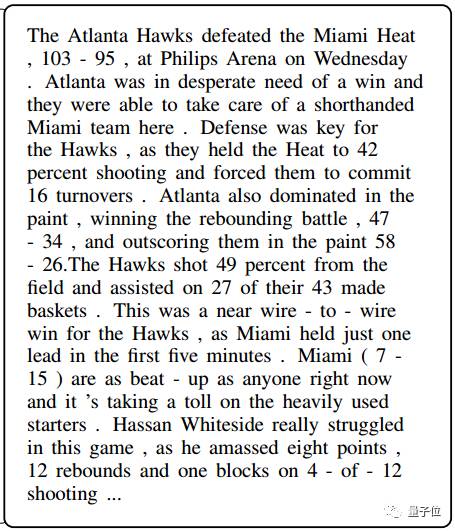
根据上面的数据,神经模型生成了以下文字内容。虽然不如新闻报道有文采,但看起来还算流利。
扩展资料
最后,附送研究详细信息——
Paper地址:
https://arxiv.org/pdf/1707.08052.pdf
Dataset地址:
https://github.com/harvardnlp/boxscore-data
Code地址:
https://github.com/harvardnlp/data2text
【完】
活动报名

8月9日(周三)晚,量子位邀请三角兽首席科学家王宝勋,分享基于对抗学习的生成式对话模型,欢迎点击这里报名~
交流沟通
量子位还有自动驾驶、NLP、CV、机器学习等专业讨论群,仅接纳相应领域的一线工程师、研究人员等。
请添加小助手qbitbot2为微信好友,提交相应说明,符合条件将被邀请入群。(审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者等岗位,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

△ 扫码强行关注『量子位』
追踪人工智能领域最劲内容


