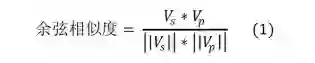人工智能是关于如何模拟实现人类智能的理论、方法、技术及应用的研究。基于不同的理念,人工智能研究分三个主要学派:符号主义学派、联结主义学派和行为主义学派( Nilsson,2009)。符号主义学派认为人类认知和思维的基本单元是符号,主要基于逻辑推理的方法模拟智能,相应成果是以专家系统、知识本体、知识图谱为代表的知识表示理论与技术。近年来,教育知识图谱( Chen et al.,2018)就是符号主义理论在教育学中的应用实例。联结主义学派把人类的智能归结为人脑的高层活动,利用神经网络及网络间的连接机制与学习算法模拟智能,代表成果是当前流行的卷积神经网络和循环神经网络。卷积神经网络善于捕捉数据的局部特征,广泛应用于图像识别、视频分析等领域。它可以基于摄像头的视频数据分析学生课堂注意力模型
( Canedo et al.,2018)。循环神经网络善于捕捉数据的前后依赖关系,常被用于序列数据的处理。针对学生知识状态评估的深度知识跟踪模型就是利用循环神经网络算法实现的( Piech et al.,2015)。行为主义学派认为智能是对外界复杂环境的适应,主要基于“感知一行动”行为模型模拟智能,代表性工作是增强学习,适用于各种决策场景,如智能教学系统如何为学生选择学习路径。在教育领域,人工智能不仅可用于解决适应性学习等问题,也可用于助力破解长期制约教育发展的关键问题。教育过程中,学生经常会出现上课故意捣乱、欺负同学等问题行为,如何解决这些问题,需要具备心理学、教育学、社会学、生理学等专业知识,但一般教师和家长通常不具有多学科完备的知识,难以对学生进行良好的教育引导。本研究针对此难题,利用人工智能技术设计和开发智能育人助理系统,帮助教师和家长矫正孩子的问题行为,引导孩子健康成长。
知识图谱通常指利用多关系图结构描述真实世界或特定领域各类实体及实体关系的知识库(Singhal,2012)。知识图谱为人工智能提供了知识基础,可以支持智能语义检索、个人智能助理、智能深度问答等智能应用。从应用领域角度,它分为通用知识图谱和领域知识图谱。通用知识图谱面向普通用户,侧重内容广度;领域知识图谱通常供行业人员使用,侧重内容的深度和精度。近年来,随着知识图谱研究的发展,工业界和学术界研发构建了 DB Pedia(Lehmann et al., 2015), Concept Net (Speer & Havasi ,2013)、 XLORE( Wang et al.,2013)等知识图谱。
知识图谱的构建包括三个步骤:图谱模式的定义、知识获取、知识融合(刘峤等,2016)。图谱模式定义知识的实体类型及关系类型。领域知识图谱因其实际的应用场景相对清晰,主要由专家依据实际需求进行的人工定义。知识获取的目的是从原始数据中识别图谱模式定义各类抽象实体及关系类型实例,包括命名实体识别和关系识别( Sarawagi,2008)。对命名实体识别任务,主流方法是利用机器学习的序列标注算法,常用的有条件随机场模型( Conditional Random Field,简称CRF)( Sutton&Mccallum,2012)、长短期记忆网络( Long Short Term Memory,简称ISTM)( Lample et al.,2016)等。关系识别任务同样可以利用命名实体识别的序列标注模型进行序列识别,但更多的是基于半监督学习和非监督学习的算法,常用的有远监督学习方法Mintz et al., 2009 ), Open IE (Banko et al.,2007),及基于注意力的神经网络( Lin et al.,2016)。知识图谱构建的最后步骤是知识融合,主要是融合知识获取结果中相同或冲突的实体和关系,使用的算法是基于概率图模型的算法( Herzog et al.,2007),以及基于机器学习分类的算法( Wang et al.,2012)。知识图谱可以实现知识层面的计算,从而更好地支持各种智能应用。常见的知识计算分析包括本体推理、规则推理、路径计算、社区计算、相似子图计算、链接预测、不一致检测等。
(二)对话系统
对话系统指能够与人进行连贯对话的计算机系统,可以采用文本、语音、图形、触觉、手势及其他方式与人进行交互,常以语音交互为主。在人工智能领域,模仿人类交谈能力的尝试可追溯到人工智能的早期阶段。1950年,艾伦·图灵提出了通过对话测试机器智能水平的方法,被普遍称为图灵测试或模仿游戏。近年来,大数据与人工智能技术的发展,尤其是深度学习的发展,极大地带动了对话系统的研究。从应用场景角度分析,对话系统主要分为两类:任务导向型对话系统和非任务导向型对话系统( Chen et al.,2017)。任务导向对话系统为实现特定任务而设计,它通过对话从用户端获取信息帮助其完成特定任务,常见的应用场景有机票预定、产品查询、在线客服等。与之相比,非任务导向型对话系统(又称闲聊机器人)没有清晰的任务,主要以模仿人与人之间非结构化会话或具有聊天特性的交互为目的( Martin& Jurafsky,2009)。本研究主要是基干任务导向型对话系统设计研发智能育人助理,因此以下主要讨论任务导向型对话系统的相关工作。
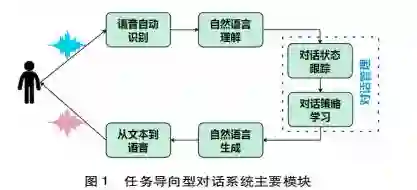
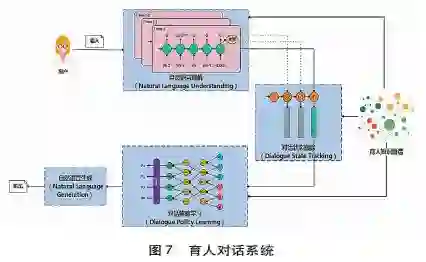
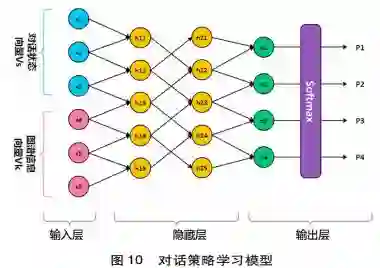
针对任务导向型对话系统,传统研究主要基于管道( Pipeline)模型(见图1),包括:1)语音自动识别模块( Automatic Speech Recognition,简称ASR),负责识别用户的语音输入并转换成文本。传统的语音识别算法主要利用隐马尔可夫模型( Rabiner,1989)。近年来,随着深度学习技术的发展,深度神经网络模型应用于语音识别并取得了较好的效果( Amodei et al.,2016)。2)自然语言理解模块(Natural Language Understanding,简称NLU),主要负责对用户输入的文本进行语义理解,包括用户意图识别( Intention Detection)和语义槽填充( Slot Fitting)。意图识别通常转换为分类问题,近年来主要利用深度模型通过文本分类的方法判别( Tur et al.,2012)。语义槽的填充通常转化为信息抽取问题,利用序列标注算法识别。传统方法主要是基于条件随机场模型,近年来逐渐采用深度神经网络模型标注( Yao et al.,2013)。3)对话管理( Dialogue Manager,简称DM),负责整体对话的管理,包括对话状态跟踪( Dialogue State Tracking,简称DST)和对话策略学习( Dialogue Policy Leaming,简称DPL)。对话状态跟踪负责对当前对话状态信息的表征,通常以语义槽形式表示,同时基于识别的用户意图和语义槽值,更新对话。对话状态跟踪研究历经人工规则阶段( Goddeau et al.,1996)、统计概率模型阶段( Williams,2013),以及深度学习模型阶段( Mrksic et al.,2015)。4)对话策略学习解决如何根据当前的对话状态,生成系统的下一步操作可以利用基于规则与监督式学习相结合的方式( Yan et al.,2017),或利用深度强化模型( Cuayahuitl et al. 2015)。5)自然语言生成( Natural Language Generaion,简称NLG)主要负责根据对话策略选择系统操作,依据模板或当前流行的深度生成模型生成用户可以理解的自然语言文本,( Wen et al.,2015)。从文本到语音( Text to Speech,简称TTS)主要负责把生成的自然语言文本转换成语音输出。近年来,随着端到端深度模型的发展,许多研究者提出基于端到端深度学习框架的任务导向型对话系统,可以从整体上对系统进行共同优化( Wen et al.,2017)。
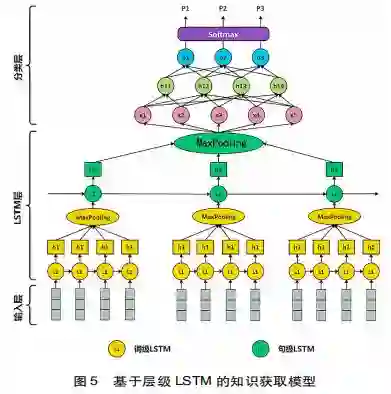
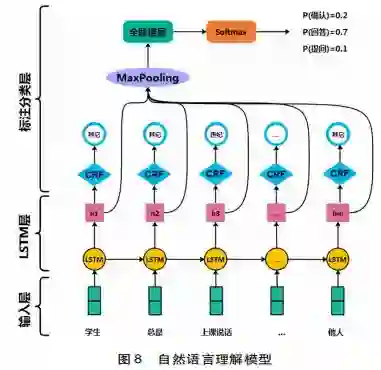
输入层利用当前人工智能领域的词嵌人算法,学习词组的语义向量表示,捕捉词组之间的语义关系作为LSTM模型的输入特征向量。流行的词嵌入学习主要基于公开文本库(如维基百科文本),利用Word2vec( Mikolov et al., 2013)或GloVe(Pennington et al.,2014)算法训练生成词组的语义向量。然而,这种方式通常不能捕捉词组的特殊领域语义。因此,本研究以育人案例数据集为文本库,利用Word2vec算法和学习词组的领域语义向量表示,构建模型的输入特征向量。
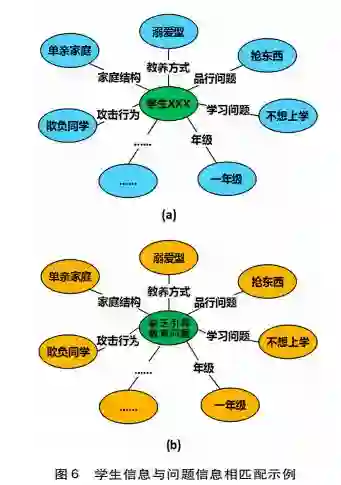
自然语言理解模块主要是对用户的输入文本进行语义理解,包括两方面:一是对用户意图的理解,如用户是想提出问题,还是回答系统的问题;二是针对用户的输人依据图谱定义的知识结构进行语义槽填充,如用户回答学生的年级是三年级时,需要识别出语义槽“年级”对应的值是“三年级”。语义槽填充的本质问题其实是序列标注问题,即针对用户的输入语句识别哪些词表示相关语义槽数值。针对自然语言理解的模型设计,常用的方法是构建两个不同的模型分别识别用户的意图和进行语义槽填充。最近,有研究尝试利用模型对两项任务同时进行优化求解,提高自然语言理解的准确率( Li et al.,2017)。因此,本研究采用类似的方法构建模型,先利用LSTM模型对输入文本进行语义解析,然后用分类模型和CRF模型对用户意图和语义槽识别标
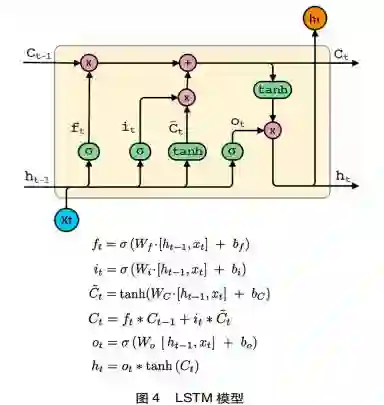
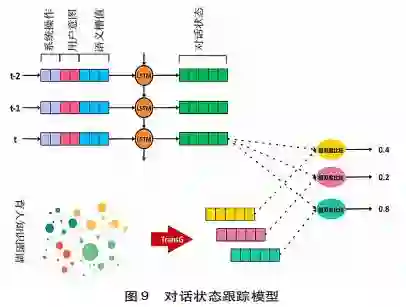
对话状态是对话系统内部对当前整个对话所处阶段的表示,融合了对话过程的上下文信息。传统的对话系统基于自然语言理解模块产生的结果,直接更新状态结构中相对应的语义槽,从而生成新的对话状态。然而,这种方法的容错性低,当自然语言理解模块识别出现错误时,此对话状态跟踪模块必然出现错误且没有办法加以更正。针对此问题,相关研究人员提出了基于概率模型的对话状态跟踪,即自然语言理解模块产生的结果不再是唯一的确定性结果,而是用概率表示每个语义槽的可能性。因此,对话状态的表示不再是0或1的二元表示,而是用概率表示每个状态的可能性。在状态更新过程中,根据上一时刻的对话状态和系统决策,及对当前用户输入的理解识别,重新计算新的对话状态。基于类似的理念,本研究设计了基于LSTM的深度学习模型(见图9)更新对话状态。LSIM的输入包括三方面信息:上一时刻的系统操作、当前的用户意图以及相应的语义槽信息。基于这三方面输人信息,结合上一时刻的对话状态向量,LSTM模型可以生成当前时刻新的对话状态向量。基于新的对话状态向量,此模块将进一步与知识图谱相结合生成潜在的答案选项,即利用知识图谱嵌入模型 Transg(Xiao et al.,2016)对知识图谱进行学习训练,生成关于每个育人问题的向量表示;通过与对话状态向量比较,计算每个问题与对话状态向量的相似度,并根据阈值选取相似的问题集,作为潜在的答案。