通用强化学习用算法发现算法:DeepMind 数据驱动「价值函数」自我更新,14款Atari游戏完虐人类!

新智元报道
新智元报道
来源:DeepMind
编辑:白峰
【新智元导读】击败卡斯帕罗夫的「深蓝」并不是真正的人工智能,它过度依赖了人类设计的规则,而最近DeepMind的一项深度强化学习新研究表明,不用人工介入,完全数据驱动,算法自己就能发现算法。

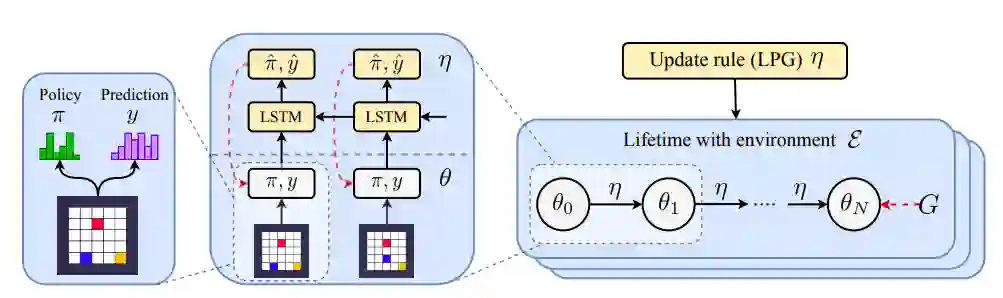
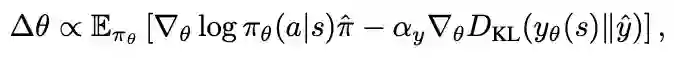
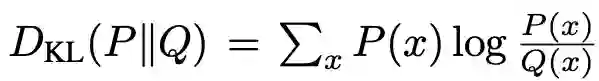
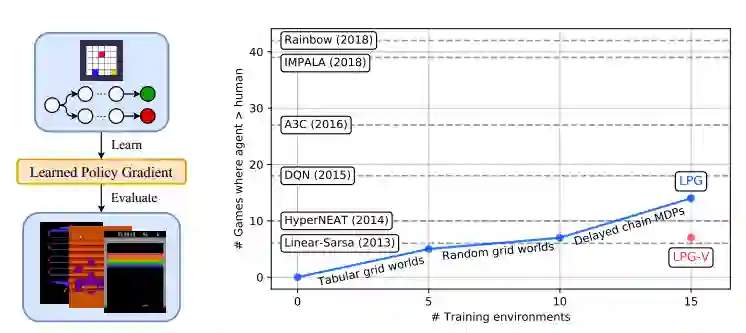
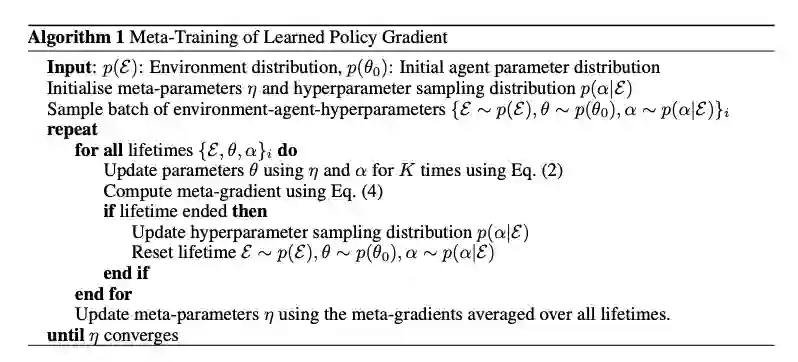 LPG的元训练过程
LPG的元训练过程
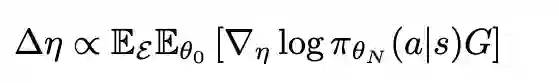

登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文